sklearn模型的训练(下)

【摘要】 聚类模型的训练
聚类模型最重要的就是(K-means)
KMeans算法的基本思想如下:
随机选择K个点作为初始质心
While 簇发生变化或小于最大迭代次数: 将每个点指派到最近的质心,形成K个簇 重新计算每个簇的质心
图中有3个初始质点,形成的3个簇,再计算每个簇的质心,比较差别
# 生成数据 make_blobs
import numpy as ...
聚类模型的训练
聚类模型最重要的就是(K-means)
KMeans算法的基本思想如下:
随机选择K个点作为初始质心
While 簇发生变化或小于最大迭代次数:
将每个点指派到最近的质心,形成K个簇 重新计算每个簇的质心
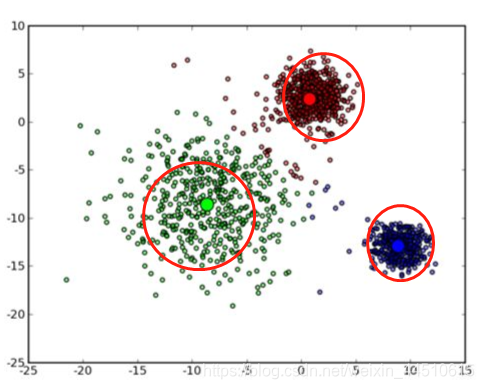
图中有3个初始质点,形成的3个簇,再计算每个簇的质心,比较差别
# 生成数据 make_blobs
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib
from sklearn.datasets.samples_generator import make_blobs
center=[[1,1],[-1,-1],[1,-1]]
cluster_std=0.3
X,labels=make_blobs(n_samples=200,centers=center,n_features=2, cluster_std=cluster_std,random_state=0)
print('X.shape',X.shape)
print("labels",set(labels))
df = pd.DataFrame(np.c_[X,labels],columns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/88783146

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)