三十六、Scrapy 中的复写默认管道和Rule扩展

【摘要】 @Author:Runsen
scrapy中的强大媒体管道(二)
上文用scrapy 爬百度美女图片,补充如何重写默认管道知识点,当年爬取的网站是:http://www.27270.com/。但是这里也访问不了,网站没了。所以下面的笔记当作回忆。
上次我们是直接使用了图片管道,有时候我们需要重写管道。 一般重写get_media_requests 和item_...
@Author:Runsen
上文用scrapy 爬百度美女图片,补充如何重写默认管道知识点,当年爬取的网站是:http://www.27270.com/。但是这里也访问不了,网站没了。所以下面的笔记当作回忆。

上次我们是直接使用了图片管道,有时候我们需要重写管道。
一般重写get_media_requests 和item_completed
- get_media_requests 一般用来加上请求头
- item_completed 保存路径
下面就是图片管道的源码
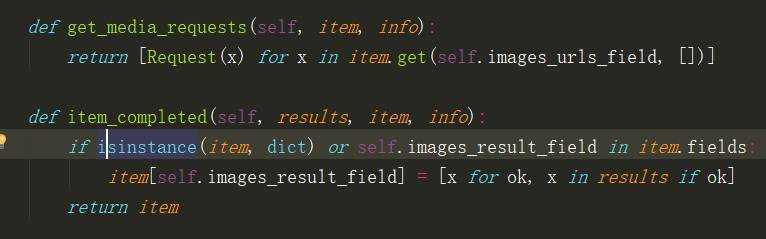
下面的代码是之前用Scrapy爬取百度图片的pipelines.py,现在我们重写了get_media_requests,和item_completed方法。
import scrapy
from scrapy.pipelines.image
- 1
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/89075132

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)