被忽视的fuzzywuzzy库

【摘要】 fuzzywuzzy包一个可以对字符串进行模糊匹配的包
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
123
字符串的对比
fuzz.ratio()对位置敏感,全匹配
fuzz.partial_ratio()非完全匹配
str1 = '毛利是个小菜比'
str2 = '毛利是个小菜比,...
fuzzywuzzy包一个可以对字符串进行模糊匹配的包
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
- 1
- 2
- 3
字符串的对比
fuzz.ratio()对位置敏感,全匹配
fuzz.partial_ratio()非完全匹配
str1 = '毛利是个小菜比'
str2 = '毛利是个小菜比,毛利是个小菜比'
print("fuzz.ratio相似度:",fuzz.ratio(str1,str2))
print("fuzz.partial_ratio相似度:",fuzz.partial_ratio(str1,str2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
fuzz.ratio相似度: 64
fuzz.partial_ratio相似度: 100
- 1
- 2
str1 = '毛利说:是个小菜比'
str2 = '毛利说是个小菜比'
print("fuzz.ratio相似度:",fuzz.ratio(str1,str2))
print("fuzz.partial_ratio相似度:",fuzz.partial_ratio(str1,str2))
- 1
- 2
- 3
- 4
fuzz.ratio相似度: 94
fuzz.partial_ratio相似度: 88
- 1
- 2
忽略顺序匹配(token_sort_ratio)
str1 = '毛利说:是个小菜比'
str2 = '是个小菜比:毛利说'
print("fuzz.ratio相似度:",fuzz.ratio(str1,str2))
print("fuzz.partial_ratio相似度:",fuzz.partial_ratio(str1,str2))
print("token_sort_ratio相似度:",fuzz.token_sort_ratio(str1,str2))
- 1
- 2
- 3
- 4
- 5
fuzz.ratio相似度: 56
fuzz.partial_ratio相似度: 56
token_sort_ratio相似度: 100
- 1
- 2
- 3
去重子集匹配(token_set_ratio)
str1 = '毛利说:是个小菜比'
str2 = '毛利说:是个小小菜比'
print("fuzz.ratio相似度:",fuzz.ratio(str1,str2))
print("fuzz.partial_ratio相似度:",fuzz.partial_ratio(str1,str2))
print("token_sort_ratio相似度:",fuzz.token_sort_ratio(str1,str2))
print("token_set_ratio相似度:",fuzz.token_set_ratio(str1,str2))
- 1
- 2
- 3
- 4
- 5
- 6
fuzz.ratio相似度: 95
fuzz.partial_ratio相似度: 89
token_sort_ratio相似度: 95
token_set_ratio相似度: 95
- 1
- 2
- 3
- 4
print(fuzz.token_sort_ratio("fuzzy was a bear", "fuzzy fuzzy was a bear"))
print(fuzz.token_set_ratio("fuzzy was a bear", "fuzzy fuzzy was a bear"))
- 1
- 2
84
100
- 1
- 2
process
用来返回模糊匹配的字符串和相似度
choices = ["python爬虫教程", "python机器学习教程", "Python数据分析教程", "pythonweb开发教程"]
print(process.extract("数据分析", choices, limit=3))
print(process.extractOne("分析", choices))
- 1
- 2
- 3
[('Python数据分析教程', 90), ('python爬虫教程', 0), ('python机器学习教程', 0)]
('Python数据分析教程', 90)
- 1
- 2
案例
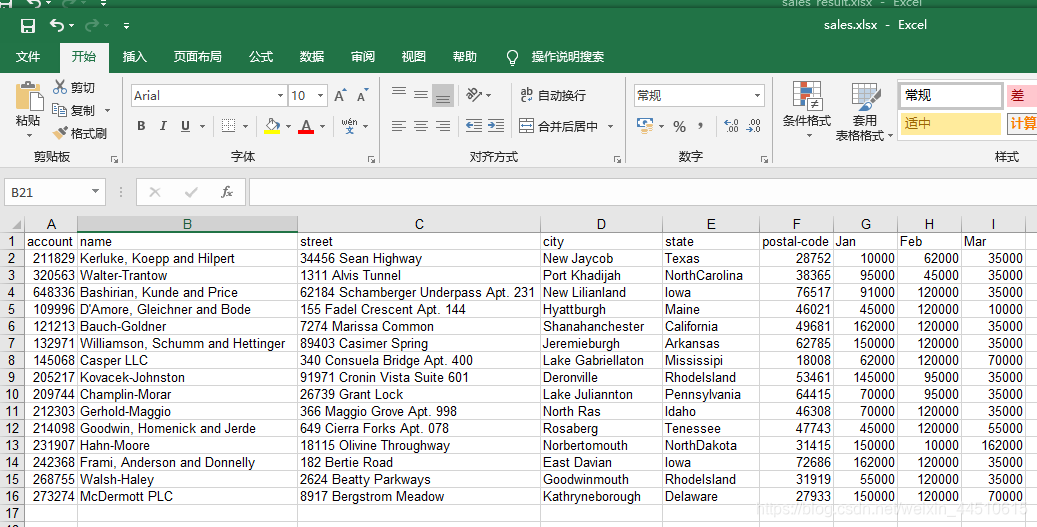
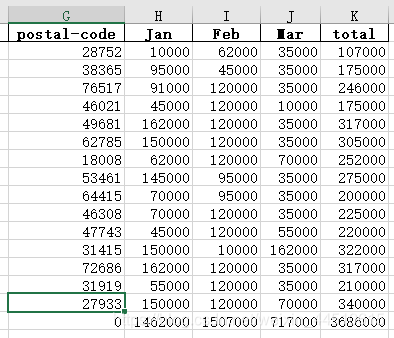
求和
import numpy as np
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
def enum_row(row): print(row['state'])
def find_state_code(row): if row['state'] != 0: print(process.extractOne(row['state'], states, score_cutoff=80))
def capital(str): return str.capitalize()
def correct_state(row): if row['state'] != 0: state = process.extractOne(row['state'], states, score_cutoff=80) if state: state_name = state[0] return ' '.join(map(capital, state_name.split(' '))) return row['state']
def fill_state_code(row): if row['state'] != 0: state = process.extractOne(row['state'], states, score_cutoff=80) if state: state_name = state[0] return state_to_code[state_name] return ''
if __name__ == "__main__": pd.set_option('display.width', 200) data = pd.read_excel('.\\sales.xlsx', sheet_name='sheet1', header=0) print('data.head() = \n', data.head()) print('data.tail() = \n', data.tail()) print('data.dtypes = \n', data.dtypes) print('data.columns = \n', data.columns) for c in data.columns: print(c, end=' ') print() data['total'] = data['Jan'] + data['Feb'] + data['Mar'] print(data.head()) print(data['Jan'].sum()) print(data['Jan'].min()) print(data['Jan'].max()) print(data['Jan'].mean()) print('=============') # 添加一行 s1 = data[['Jan', 'Feb', 'Mar', 'total']].sum() print(s1) s2 = pd.DataFrame(data=s1) print(s2) print(s2.T) print(s2.T.reindex(columns=data.columns)) # 即: s = pd.DataFrame(data=data[['Jan', 'Feb', 'Mar', 'total']].sum()).T s = s.reindex(columns=data.columns, fill_value=0) print(s) data = data.append(s, ignore_index=True) data = data.rename(index={15:'Total'}) print(data.tail()) # apply的使用 print('==============apply的使用==========') data.apply(enum_row, axis=1) state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU", "KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI", "NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM", "Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL", "Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA", "PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM", "MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE", "NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA", "MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH", "WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA", "NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND", "Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI", "DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"} states = list(state_to_code.keys()) print(fuzz.ratio('Python Package', 'PythonPackage')) print(process.extract('Mississippi', states)) print(process.extract('Mississipi', states, limit=1)) print(process.extractOne('Mississipi', states)) data.apply(find_state_code, axis=1) print('Before Correct State:\n', data['state']) data['state'] = data.apply(correct_state, axis=1) print('After Correct State:\n', data['state']) data.insert(5, 'State Code', np.nan) data['State Code'] = data.apply(fill_state_code, axis=1) print(data) # group by print('==============group by================') print(data.groupby('State Code')) print('All Columns:\n') print(data.groupby('State Code').sum()) print('Short Columns:\n') print(data[['State Code', 'Jan', 'Feb', 'Mar', 'total']].groupby('State Code').sum()) # 写入文件 data.to_excel('sales_result.xlsx', sheet_name='Sheet1', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
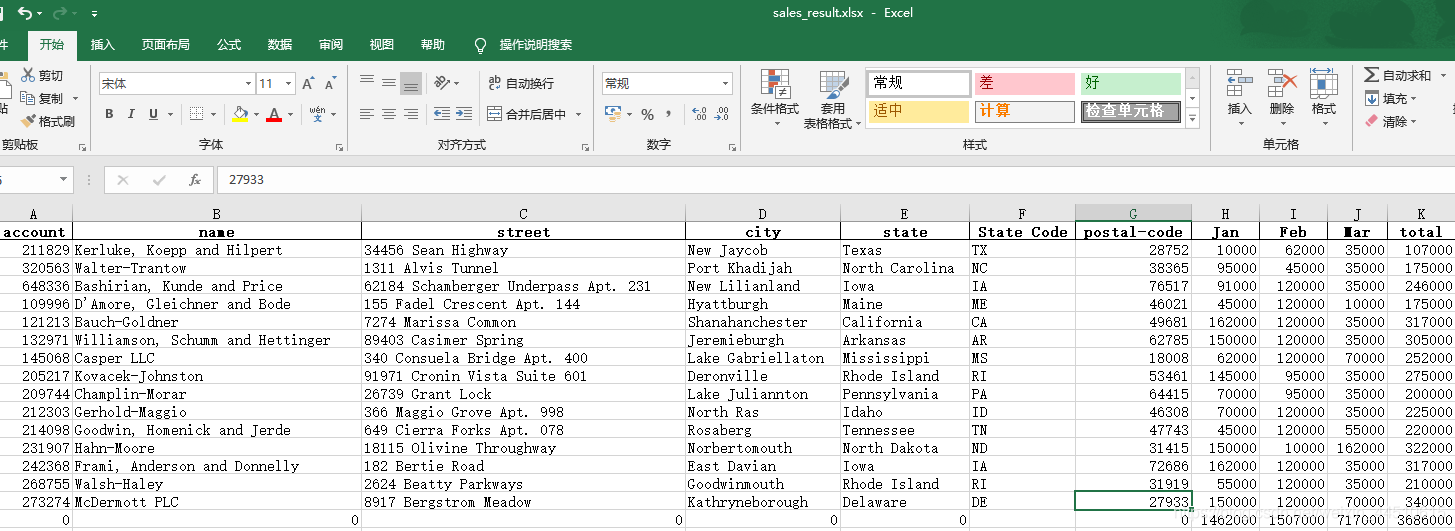
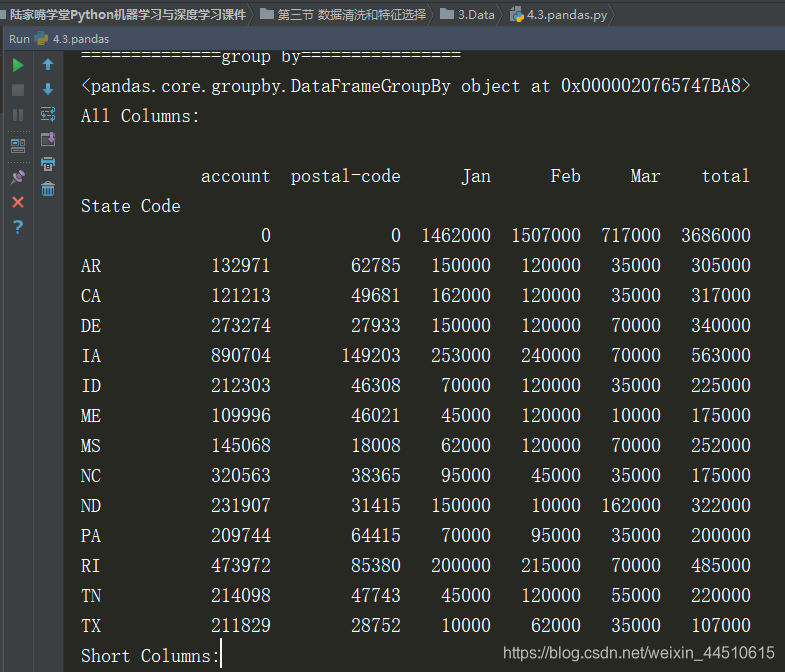
这方法好复杂,看来以后要写下office的笔记了
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/89576975

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)