文本分类实战(上)

【摘要】 数据集介绍
其中0表示消极,1表示积极,主要处理 ‘data/yelp_labelled.txt’, ‘data/amazon_cells_labelled.txt’, ‘data/imdb_labelled.txt’
import pandas as pd
"""
数据读取,其中0表示消极,1表示积极,合并数据集
"""
filepath_dict = {...
数据集介绍
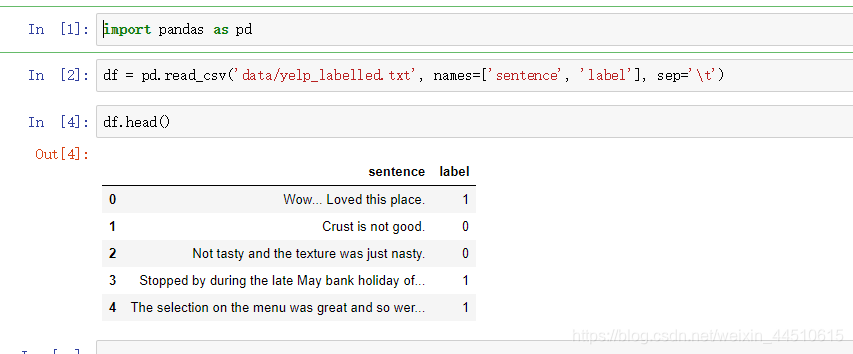
其中0表示消极,1表示积极,主要处理 ‘data/yelp_labelled.txt’, ‘data/amazon_cells_labelled.txt’, ‘data/imdb_labelled.txt’
import pandas as pd
"""
数据读取,其中0表示消极,1表示积极,合并数据集
"""
filepath_dict = {'yelp': 'data/yelp_labelled.txt', 'amazon': 'data/amazon_cells_labelled.txt', 'imdb': 'data/imdb_labelled.txt'}
df_list = []
for source, fil
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/90212080

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)