核密度(Kde)

【摘要】 密度估计的问题
由给定样本集合求解随机变量的分布密度函数问题是概率统计学的基本问题之一。解决这一问题的方法包括参数估计和非参数估计。
参数估计
参数估计又可分为参数回归分析和参数判别分析。在参数回归分析中,人们假定数据分布符合某种特定的性态,如线性、可化线性或指数性态等,然后在目标函数族中寻找特定的解,即确定回归模型中的未知参数。在参数判别分析中,人们需要假定作为...
密度估计的问题
由给定样本集合求解随机变量的分布密度函数问题是概率统计学的基本问题之一。解决这一问题的方法包括参数估计和非参数估计。
参数估计
参数估计又可分为参数回归分析和参数判别分析。在参数回归分析中,人们假定数据分布符合某种特定的性态,如线性、可化线性或指数性态等,然后在目标函数族中寻找特定的解,即确定回归模型中的未知参数。在参数判别分析中,人们需要假定作为判别依据的、随机取值的数据样本在各个可能的类别中都服从特定的分布。
经验和理论说明,参数模型的这种基本假定与实际的物理模型之间常常存在较大的差距,这些方法并非总能取得令人满意的结果。
核密度估计(kde)在某种意义上是一种将高斯思想的混合带到逻辑极端的算法:它使用由每个点一个高斯分量组成的混合,从而产生一个本质上非参数的密度估计
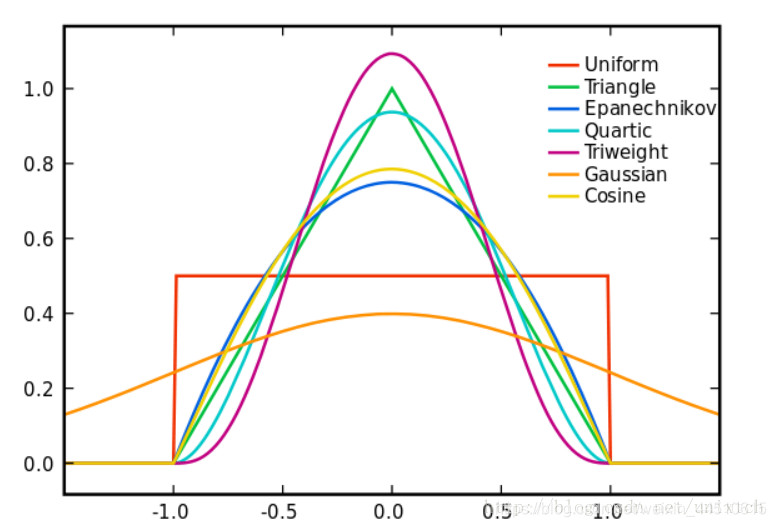
核函数
这里的核函数有uniform,triangular, biweight, triweight, Epanechnikov,normal等。这些核函数的图像大致如下图:
sklearn简单 实现
from sklearn.neighbors import kde
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
kde
- 1
- 2
- 3
- 4
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/90732718

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)