sklearn(聚类和降维)

【摘要】 聚类(clustering)
聚类(clustering),就是根据数据的“相 似性”将数据分为多类的过程。 评估两个不同样本之间的“相似性” ,通 常使用的方法就是计算两个样本之间的“距离”。 使用不同的方法计算样本间的距离会关系到聚类 结果的好坏。
欧氏距离
欧氏距离是最常用的一种距离度 量方法,源于欧式空间中两点的距离。 其计算方法如下
曼哈顿距离...
聚类(clustering)
聚类(clustering),就是根据数据的“相 似性”将数据分为多类的过程。 评估两个不同样本之间的“相似性” ,通 常使用的方法就是计算两个样本之间的“距离”。 使用不同的方法计算样本间的距离会关系到聚类 结果的好坏。
欧氏距离
欧氏距离是最常用的一种距离度 量方法,源于欧式空间中两点的距离。 其计算方法如下
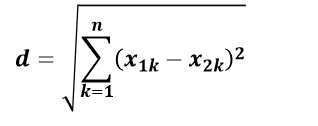

曼哈顿距离
曼哈顿距离也称作“城市街区距 离”,类似于在城市之中驾车行驶, 从一个十字路口到另外一个十字楼口 的距离。其计算方法如下:
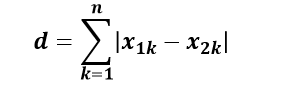

文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/90578381

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)