sklearn分类模型

【摘要】 分类学习
输入:一组有标签的训练数据(也称观察和评估),标签表明了这些数 据(观察)的所署类别。
输出:分类模型根据这些训练数据,训练自己的模型参数,学习出一个 适合这组数据的分类器,当有新数据(非训练数据)需要进行类别判断,就 可以将这组新数据作为输入送给学好的分类器进行判断。
划分数据集
训练集(training set):顾名思义用来训练模型的已标注数据,...
分类学习
输入:一组有标签的训练数据(也称观察和评估),标签表明了这些数 据(观察)的所署类别。
输出:分类模型根据这些训练数据,训练自己的模型参数,学习出一个 适合这组数据的分类器,当有新数据(非训练数据)需要进行类别判断,就 可以将这组新数据作为输入送给学好的分类器进行判断。
划分数据集
训练集(training set):顾名思义用来训练模型的已标注数据,用来建 立模型,发现规律。
测试集(testing set):也是已标注数据,通常做法是将标注隐藏,输送 给训练好的模型,通过结果与真实标注进行对比,评估模型的学习能力。
训练集/测试集的划分方法:根据已有标注数据,随机选出一部分数据 (70%)数据作为训练数据,余下的作为测试数据,此外还有交叉验证法, 自助法用来评估分类模型。
评价标准
精确率:精确率是针对我们预测结果而言的,(以二分类为例)它表示 的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能 了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP), 也就是
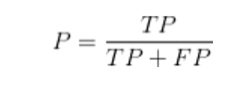
召回率:是针对我们原来的样本而言的,它表示的是样本中的正例有多 少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP), 另一种就是把原来的正类预测为负类(FN),也就是
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/90582139

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)