四十二、Scrapy爬取csdn的博客标题和网址

【摘要】 @Author:Runsen
每天一爬虫,健康生活每一天、
今天使用Scrapy爬下CSDN的文章的url
目标:爬取CSDN的各类文章的url,简单使用scrapy 来爬取
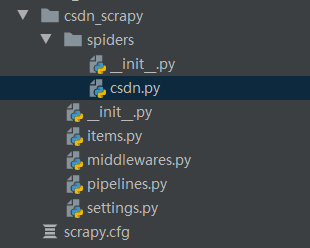
创建的Scrapy项目如下所示。
item.py
import scrapy
class CsdnScrapyItem(scrapy.Item): # define the fie...
@Author:Runsen
每天一爬虫,健康生活每一天、
今天使用Scrapy爬下CSDN的文章的url
目标:爬取CSDN的各类文章的url,简单使用scrapy 来爬取
创建的Scrapy项目如下所示。
item.py
import scrapy
class CsdnScrapyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 文章名 title = scrapy.Field(
- 1
- 2
- 3
- 4
- 5
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/91348778

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)