贪心科技机器学习训练营(四)

【摘要】 先把来源写上
来源:贪心学院,https://www.zhihu.com/people/tan-xin-xue-yuan/activities
这次回归
之前写过关于平安股票的,竟然没想到是同一个案例
平安股票分析
说明下这个模型是没用的
import numpy as np # 数学计算
import pandas as pd # 数据处理, 读取 CSV...
先把来源写上
来源:贪心学院,https://www.zhihu.com/people/tan-xin-xue-yuan/activities
这次回归
之前写过关于平安股票的,竟然没想到是同一个案例
说明下这个模型是没用的
import numpy as np # 数学计算
import pandas as pd # 数据处理, 读取 CSV 文件 (e.g. pd.read_csv)
import matplotlib.pyplot as plt
from datetime import datetime as dt
- 1
- 2
- 3
- 4
- 5
# 你可以使用如下的方法下载某一个公司的股票交易历史
# 000001 为平安银行
# 如果你还没有安装, 可以使用 pip install tushare 安装tushare python包
# import tushare as ts
# df = ts.get_hist_data('000001')
# print(df)
# df.to_csv('000001.csv')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
df = pd.read_csv('./000001.csv')
- 1
print(np.shape(df))
df.head()
- 1
- 2
(611, 14)
- 1
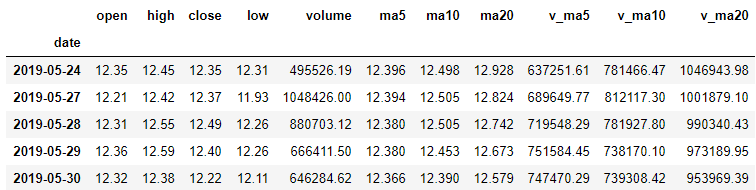
| date | open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-05-30 | 12.32 | 12.38 | 12.22 | 12.11 | 646284.62 | -0.18 | -1.45 | 12.366 | 12.390 | 12.579 | 747470.29 | 739308.42 | 953969.39 |
| 1 | 2019-05-29 | 12.36 | 12.59 | 12.40 | 12.26 | 666411.50 | -0.09 | -0.72 | 12.380 | 12.453 | 12.673 | 751584.45 | 738170.10 | 973189.95 |
| 2 | 2019-05-28 | 12.31 | 12.55 | 12.49 | 12.26 | 880703.12 | 0.12 | 0.97 | 12.380 | 12.505 | 12.742 | 719548.29 | 781927.80 | 990340.43 |
| 3 | 2019-05-27 | 12.21 | 12.42 | 12.37 | 11.93 | 1048426.00 | 0.02 | 0.16 | 12.394 | 12.505 | 12.824 | 689649.77 | 812117.30 | 1001879.10 |
| 4 | 2019-05-24 | 12.35 | 12.45 | 12.35 | 12.31 | 495526.19 | 0.06 | 0.49 | 12.396 | 12.498 | 12.928 | 637251.61 | 781466.47 | 1046943.98 |
股票数据的特征
- date:日期
- open:开盘价
- high:最高价
- close:收盘价
- low:最低价
- volume:成交量
- price_change:价格变动
- p_change:涨跌幅
- ma5:5日均价
- ma10:10日均价
- ma20:20日均价
- v_ma5:5日均量
- v_ma10:10日均量
- v_ma20:20日均量
# 将每一个数据的键值的类型从字符串转为日期
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df.tail()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2019-05-24 | 12.35 | 12.45 | 12.35 | 12.31 | 495526.19 | 0.06 | 0.49 | 12.396 | 12.498 | 12.928 | 637251.61 | 781466.47 | 1046943.98 |
| 2019-05-27 | 12.21 | 12.42 | 12.37 | 11.93 | 1048426.00 | 0.02 | 0.16 | 12.394 | 12.505 | 12.824 | 689649.77 | 812117.30 | 1001879.10 |
| 2019-05-28 | 12.31 | 12.55 | 12.49 | 12.26 | 880703.12 | 0.12 | 0.97 | 12.380 | 12.505 | 12.742 | 719548.29 | 781927.80 | 990340.43 |
| 2019-05-29 | 12.36 | 12.59 | 12.40 | 12.26 | 666411.50 | -0.09 | -0.72 | 12.380 | 12.453 | 12.673 | 751584.45 | 738170.10 | 973189.95 |
| 2019-05-30 | 12.32 | 12.38 | 12.22 | 12.11 | 646284.62 | -0.18 | -1.45 | 12.366 | 12.390 | 12.579 | 747470.29 | 739308.42 | 953969.39 |
# 检测是否有缺失数据 NaNs
df.dropna(axis=0 , inplace=True)
df.isna().sum()
- 1
- 2
- 3
- 4
open 0
high 0
close 0
low 0
volume 0
price_change 0
p_change 0
ma5 0
ma10 0
ma20 0
v_ma5 0
v_ma10 0
v_ma20 0
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
K线图
Min_date = df.index.min()
Max_date = df.index.max()
print ("First date is",Min_date)
print ("Last date is",Max_date)
print (Max_date - Min_date)
- 1
- 2
- 3
- 4
- 5
First date is 2016-11-29 00:00:00
Last date is 2019-05-30 00:00:00
912 days 00:00:00
- 1
- 2
- 3
plotly画图
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
init_notebook_mode()
import plotly.plotly as py
import plotly.graph_objs as go
trace = go.Ohlc(x=df.index, open=df['open'], high=df['high'], low=df['low'], close=df['close'])
data = [trace]
iplot(data, filename='simple_ohlc')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10


from sklearn.linear_model import LinearRegression
from sklearn import preprocessing
# 创建新的列, 包含预测值, 根据当前的数据预测5天以后的收盘价
num = 5 # 预测5天后的情况
df['label'] = df['close'].shift(-num) # 预测值 print(df.shape)
df.head(6)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

# 丢弃 'label', 'price_change', 'p_change', 不需要它们做预测
Data = df.drop(['label', 'price_change', 'p_change'],axis=1)
Data.tail()
- 1
- 2
- 3
X = Data.values
# 0 到 1
X = preprocessing.scale(X)
# 后面5个不要
X = X[:-num]
df.dropna(inplace=True)
Target = df.label
y = Target.values
print(np.shape(X), np.shape(y))
# (606, 11) (606,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
# 将数据分为训练数据和测试数据
X_train, y_train = X[0:550, :], y[0:550]
X_test, y_test = X[550:, -51:], y[550:606]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(550, 11)
(550,)
(56, 11)
(56,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
lr = LinearRegression()
lr.fit(X_train, y_train)
lr.score(X_test, y_test) # 使用绝对系数 R^2 评估模型
# 0.04930040648385525
非常的垃圾,所以个人认为毫无意义
- 1
- 2
- 3
- 4
- 5
- 6
- 7




打广告,欢迎关注毛利学python

文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/95648371

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)