贪心科技机器学习训练营(十一)

【摘要】 先把来源写上
来源:贪心学院,https://www.zhihu.com/people/tan-xin-xue-yuan/activities
往期文章:
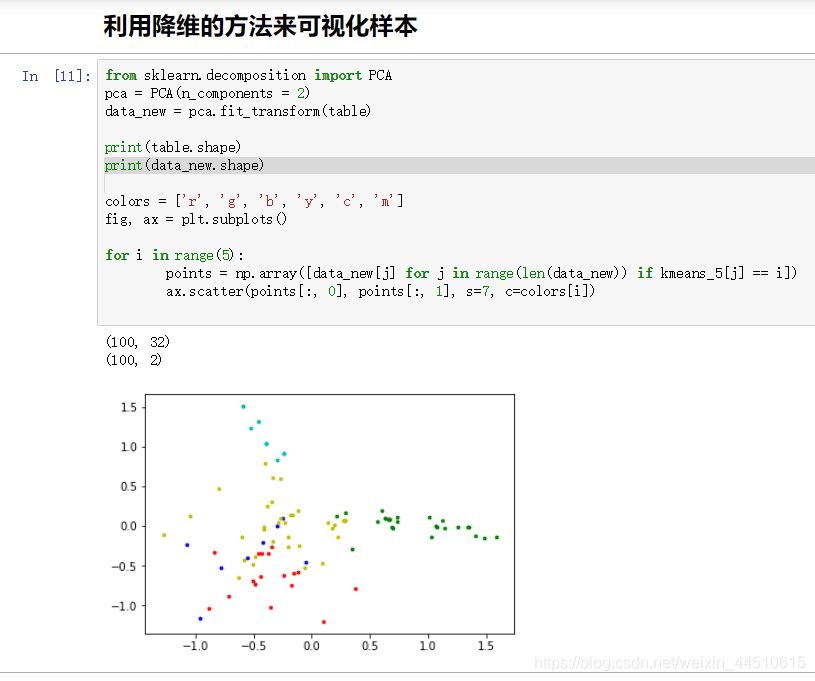
K-means算法
k - means 是无监督学习的一种,主要用于分类
首先确定K值,就是类别数,我们想把数据分为几类。根据k值随机选取K个点,作为中心点,分别计算其余各个点到这K个点的距离。对于每一个非...
先把来源写上
来源:贪心学院,https://www.zhihu.com/people/tan-xin-xue-yuan/activities
往期文章:
k - means 是无监督学习的一种,主要用于分类
- 首先确定K值,就是类别数,我们想把数据分为几类。
- 根据k值随机选取K个点,作为中心点,分别计算其余各个点到这K个点的距离。对于每一个非中心点,找到离它最近的那个中心点,把这个非中心点和对应的中心点归为一类。
- 计算每个类别中所有点的均值,作为新的中心点,然后重复以上动作,再次计算每个点到新的中线点的距离,找的离它最近的归为一类,再次计算中心点
- .如果中心点不变了,就得到了最终的聚类中心,每个点找到离它最近的中心点,就完成了聚类。
K-means中K值的选取
from sklearn.cluster import KMeans
wcss = []
for k in range(1,15): kmeans = KMeans(n_clusters=k) kmeans.fit(x) wcss.append(kmeans.inertia_)
plt.plot(range(1,15),wcss)
plt.xlabel("k values")
plt.ylabel("WCSS")
plt.show()
---------------------
作者:毛利学python
来源:CSDN
原文:https://blog.csdn.net/weixin_44510615/article/details/92021326
版权声明:本文为博主原创文章,转载请附上博文链接!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
手写k-means

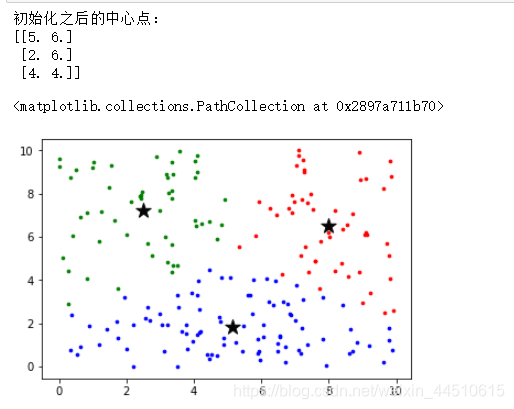
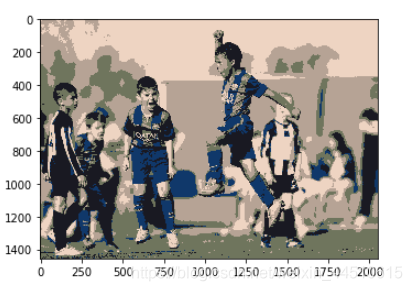
k-means读取图片 (这里的k是颜色的个数)

基于K-means的用户分层
数据是这样的:不同的公司举行了不同的优惠活动,每个用户参加了多个活动
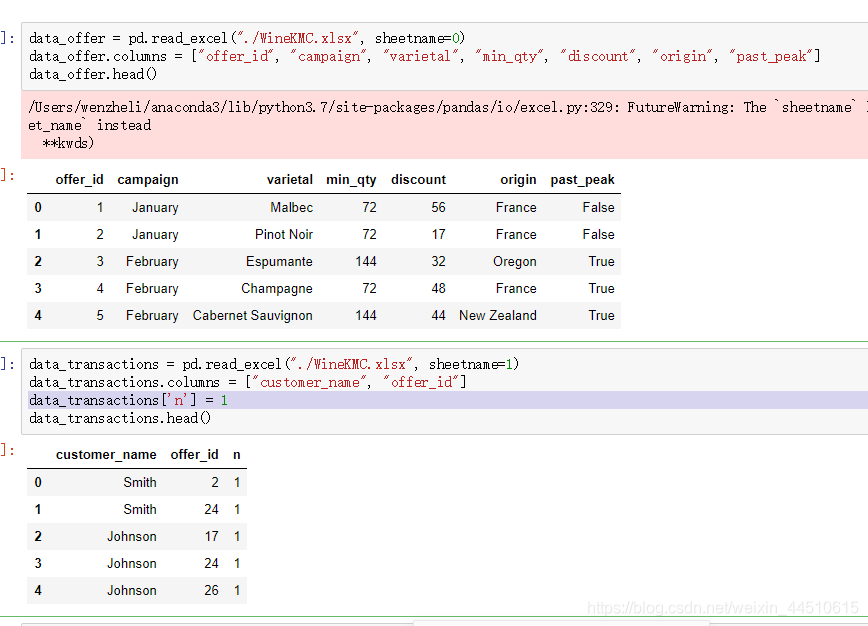

数据透视表
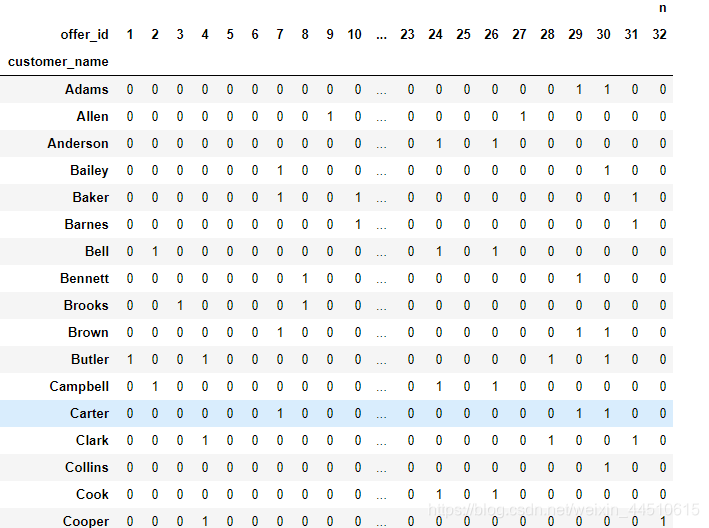
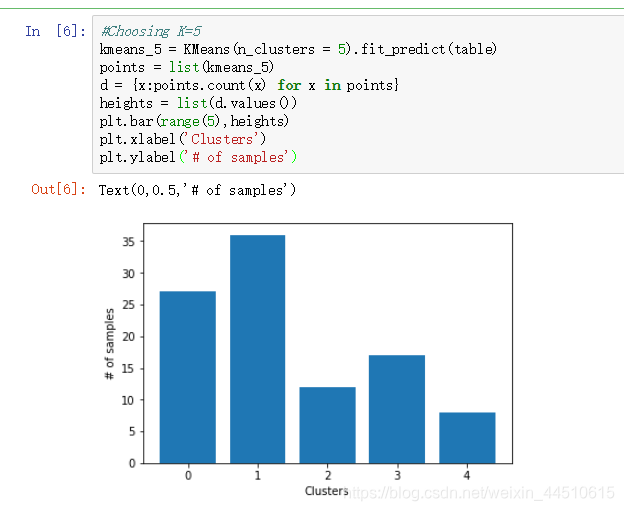
用k-mean将用户分类出来
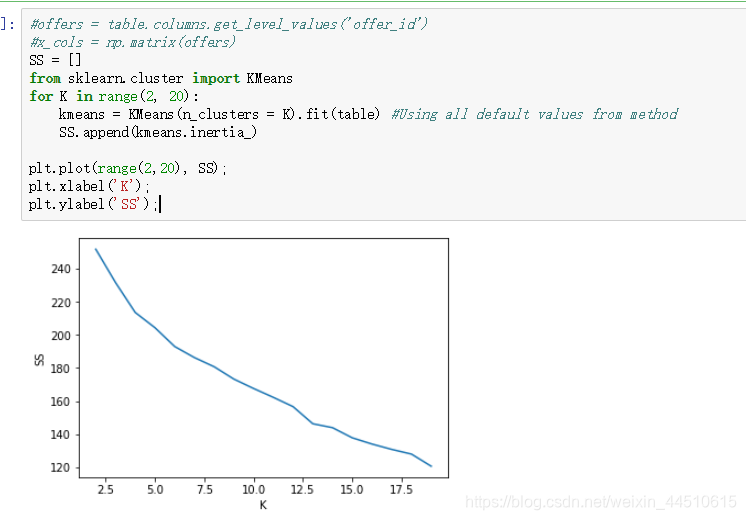
寻找k值
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/96478377

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)