七、Python简单爬取学堂在线合作院校页面内容

【摘要】 这是一个大学生的爬虫作业,我是收钱干活的,比较简单,来过来分享一下。
就是要爬取到合作院校的名称及该所院校在学堂在线开课的数量,将爬取到的数据保存到一个json文件中!例如:“{“清华大学”:308}”
直接用xpath就可以了,保存为字典,然后转化成json就OK了。
dict(zip(course,nums))将两个列表变成字典,这个需要知道。
爬取代...
这是一个大学生的爬虫作业,我是收钱干活的,比较简单,来过来分享一下。

就是要爬取到合作院校的名称及该所院校在学堂在线开课的数量,将爬取到的数据保存到一个json文件中!例如:“{“清华大学”:308}”
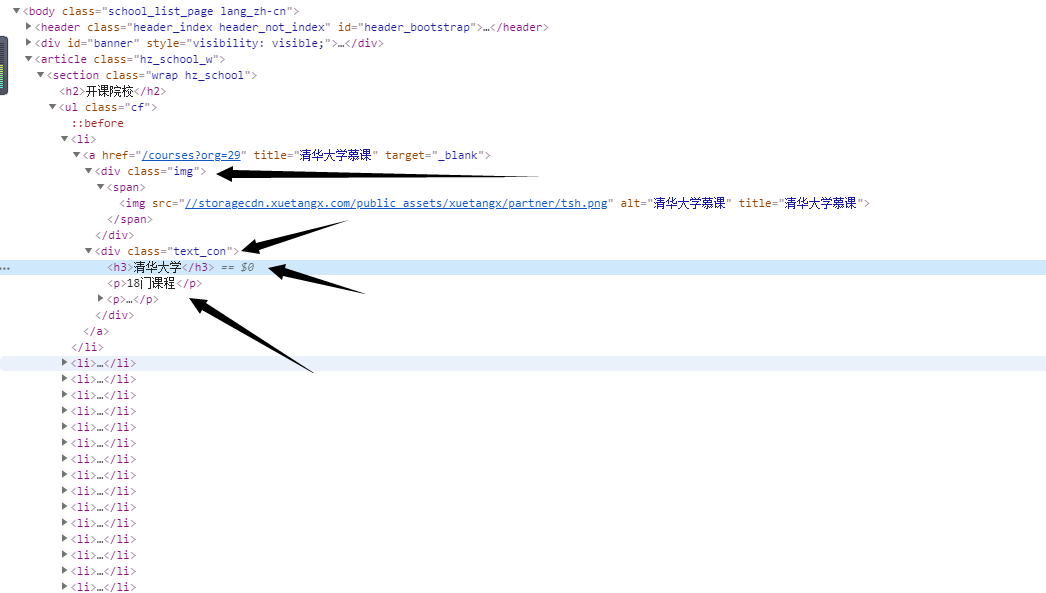
直接用xpath就可以了,保存为字典,然后转化成json就OK了。
dict(zip(course,nums))将两个列表变成字典,这个需要知道。
爬取代码如下。
'''
@Author: Runsen
@微信公众号: 润森笔记
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/4/13
'''
'''
目标:爬取学堂在线合作院校页面内容
网址:http://www.xuetangx.com/partners
要求:爬取到合作院校的名称及该所院校在学堂在线开课的数量,将爬取到的数据保存到一个json文件中!例如:“{"清华大学":308}”
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/105707524

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)