statTarget-基于QC样本的代谢组学数据校正

为什么数据质量控制重要呢?
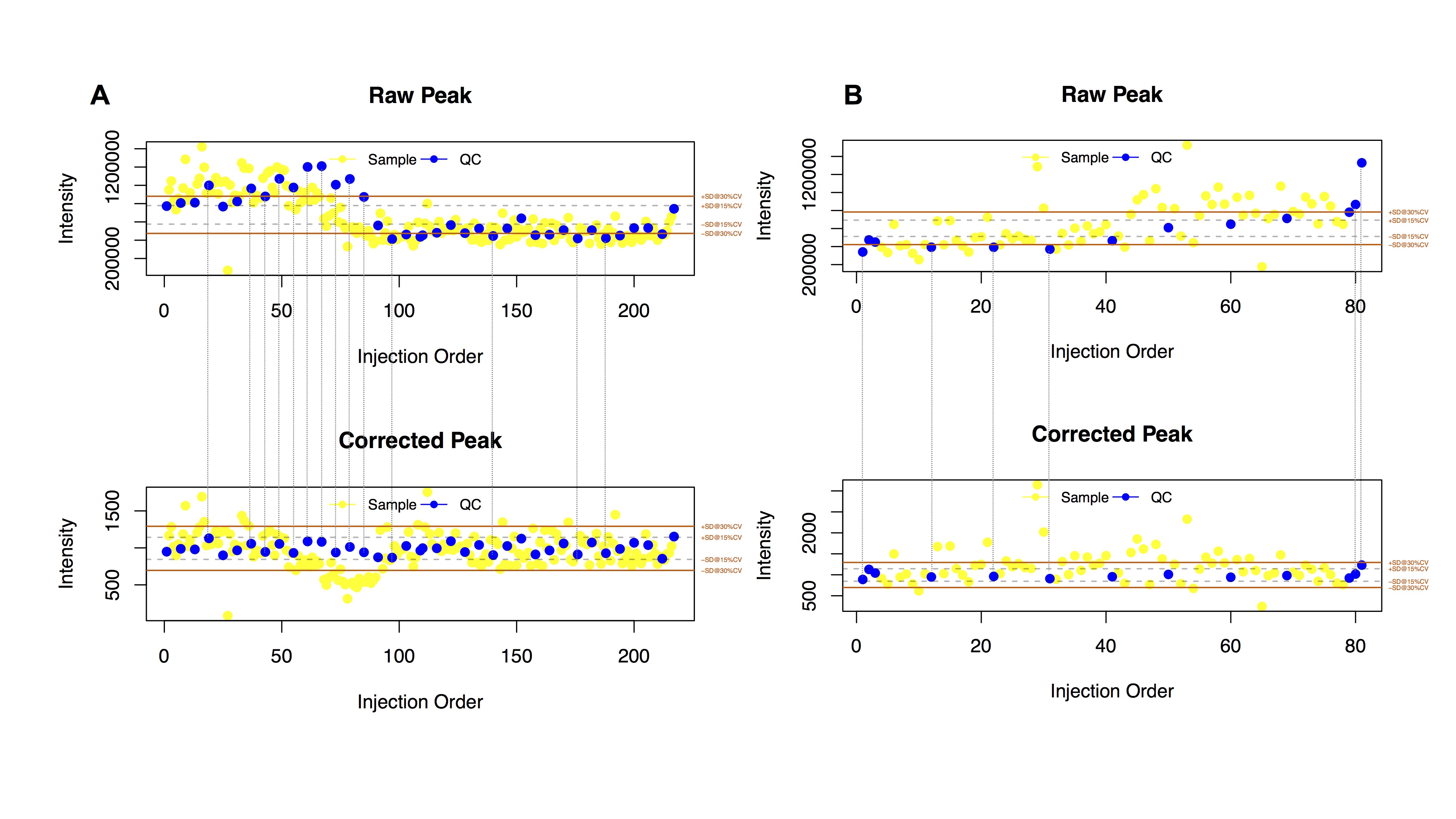
质量控制是生物分析的基本概念之一,用在保证组学测定的数据的重复性和精确性。由于色谱系统与质谱直接与样品接触, 随着分析样品的增多,色谱柱和质谱会逐步的污染,导致信号的漂移。通过重复使用同一个质控样本来跟踪整个数据采集过程的行为, 已经被大多数的分析化学领域专家推荐和使用。质控样本被用于评估整个质谱数据在采集过程中的信号漂移, 这些漂移进一步能够被精确的算法所识别,校正,提高数据的质量。如图1所示,蓝色质控样本点的特征峰信号强度在整个分析过程中能够具有将近6倍差异(最高点-最低点), 通过QC-RFSC算法校正后,信号强度差异被降到了1.5倍以内。完全符合FDA对于生物样本分析的质控要求。
statTarget是一种流线型的工具,具有简单易用的界面,提供组学数据的数据校正(QC-RFSC)和广泛的精确地统计分析。
概述
statTarget一个精简的可以提供图形用户界面,基于质QC样本进行信号校正,可以整合不同批次之间的代谢组学和蛋白质组学数据,并进行全面的统计分析。
statTarget是如何工作的
statTarget包括两方面内容
- 一个是信号校正(见后面的shiftCor函数)。其包括基于
QC样本进行信号校正的集成学习方法。比如:
- 基于QC样本的随机森林校正(QC-based random forest correction, QC-RFSC);
- 基于QC样本的LOESS(locally weighted scatterplot smoothing)信号校正(QC-based LOESS signal correction, QCRLSC)
- 第二部分内容是
统计分析(详见后面介绍的statAnalysis函数)。提供了较为全面的用于分析组学数据的计算和统计方法,并且为生物标志物的发现提供多种结果。另外还提供了一个statTargetGUI功能,可以交互界面进行上述功能的操作。
statTarget包的功能列表
- 数据前处理(Data preprocessing):80%的原则,总丰度归一化(sum normalization),概率系数归一化(probabilistic quotient normalization),glog转化(glog transformation),K-近邻算法数据填充[3]、中位数、最小值填充都是针对缺失数据进行填充的方法。
- 数据描述:比如平均值、中位数、和、四分位数及标准差等
- 多元统计分析:如PCA, PLSDA, VIP, Random forest, Permutation-based feature selection。
- 单变量分析:Welch t检验,Shapiro-Wilk normality test(数据正态性检验) and Mann-Whitney test。
- 生物标记物分析:ROC, Odd ratio(优势比), P值多重校正,箱线图和火山图
statTargetGUI
因为该函数提供了一个交互式界面分析的功能
statTargetGUI,所以先看下如何使用
-
## Examples Code for graphical user interface
-
-
library(statTarget)
-
-
statTargetGUI()
-
-
#For mac PC, the GUI function 'statTargetGUI()' need the XQuartz instead of X11 support. Download it from https://www.xquartz.org. R 3.3.0 and RGtk2 2.20.31 are recommended for RGtk2 installation.
信号校正
- 文件准备
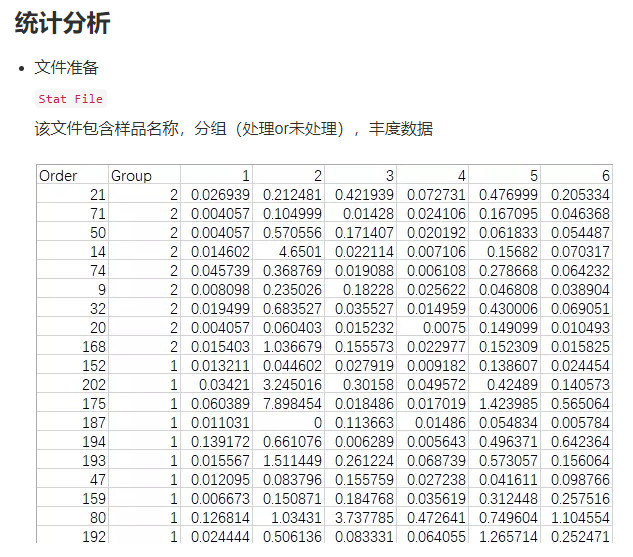
Meta file
该文件包含样品名称,分组信息,批次和进样顺序。
1.Class:QC样品此处标为NA
2.Order:进样顺序
3.Batch:样本的批次信息
4.Meta文件和Profile文件的样品名称必须一致
代码实例
-
## Examples Code
-
-
library(statTarget)
-
-
datpath <- system.file('extdata',package = 'statTarget')
-
samPeno <- paste(datpath,'MTBLS79_sampleList.csv', sep='/')
-
samFile <- paste(datpath,'MTBLS79.csv', sep='/')
-
shiftCor(samPeno,samFile, Frule = 0.8, MLmethod = "QCRFSC", QCspan = 0,imputeM = "KNN")
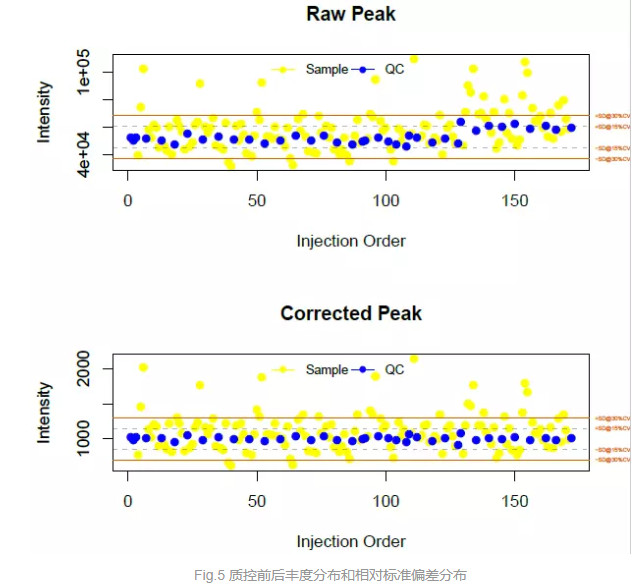
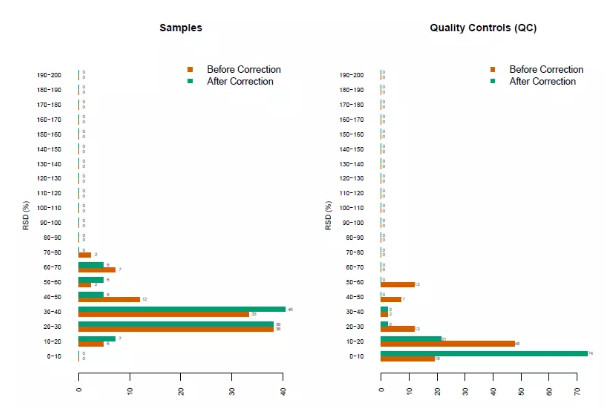
参考:
[1] Luan H., Ji F., Chen Y., Cai Z. (2018) statTarget: A streamlined tool for signal drift correction and interpretations of quantitative mass spectrometry-based omics data. Analytica Chimica Acta. dio: https://doi.org/10.1016/j.aca.2018.08.002
[2] Luan H., Ji F., Chen Y., Cai Z. (2018) Quality control-based signal drift correction and interpretations of metabolomics/proteomics data using random forest regression. bioRxiv 253583; doi: https://doi.org/10.1101/253583
[3] KNN,k-临近算法
[4] statTarget官网
[5] https://www.jianshu.com/p/f2f542032fd2
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/88675773

- 点赞
- 收藏
- 关注作者
评论(0)