NLP(1) | 词向量one hot编码词向量编码思想

词向量one hot编码词向量编码思想Word2VecEmbeddingSkip-gram的原理负采样
前言:深度学习网络rnn能解决有序的问题,我们就生活在这样一个有序的世界。比如时间,音乐,说话的句子,甚至一场比赛,比如最近正在举办的俄罗斯世界杯。
one hot编码
我们在做分类任务的时候经常用到one hot编码,如果把自然语言中每个词当做一个类别,维度就会非常大,但能解决了最基本的问题——能分开词了。如下图:
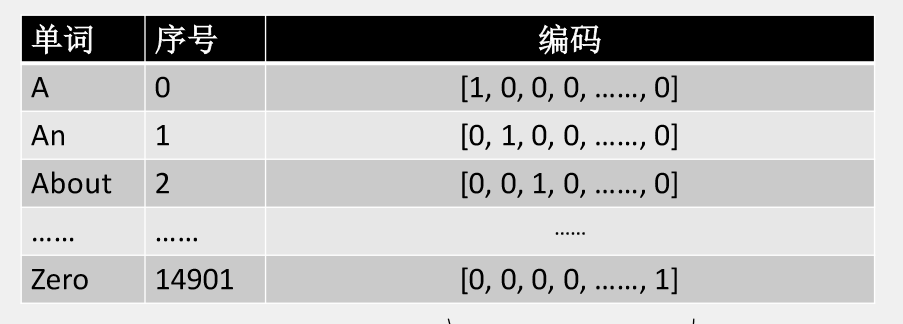
一共能产生14901维。 问题:占用太大空间,词和词之间的相识度无法体现。也就是所说的稀疏化。 one hot代码如下:
-
from sklearn.preprocessing import OneHotEncoder
-
# lables = ['ni','号','ni','meimei']
-
lables = [0,1,0,4]
-
lables = np.array(lables).reshape(len(lables),-1)
-
enc = OneHotEncoder()
-
enc.fit(lables)
-
target = enc.transform(lables).toarray()
-
-
print(target)
输出结果如下:

词向量编码思想
我们需要把上面的编码转化为这样的编码:

能很好地解决上面的问题。基于以上思想,生出很多方法,主要有两种假说。
- 假说一:The distributional hypothesis 分布式假说
一个词由周围词来推断。相似的词会出现在相似的语境里。例如今晚的天空有很多星星。句子中天空和星星相关,横向共现。这样,我们可以由词跟语境的关系来判断相似度,天空和星星就是相似的。BOW, LSI, LDA等模型都是由这种假说出发的,产生的很多种方法来计算这个实值向量。1954年BOW模型不考虑语序,出现一次加1。2003年LDA模型,是主题模型中的某一个特例。PMI/PPMI等方法都研究共现,相关词共同出现几次,然后再做SVD矩阵分解等。
- 假说二:Distributed models
相似词在相似语境contex下。例如今天天空有很多星星。今天天空有个太阳。这两个句子中的星星和太阳这两个词出现在了同样的上下文之中,它们是相似的,但它们是一种纵向的相似性。基于这种假说诞生的方法,最重要的就是这个Word2Vec。 当然,我们要讲解的重点是Word2Vec。事实上,Word2Vec是由神经网络语言模型得到的一个副产物
Word2Vec
Word2vec 是代码项目的名字,只是计算词嵌入(word embedding)的一个工具,是CBOW和Skip-Gram这两个模型的合体,目前这套工具完全开源。 CBOW是利用词的上下文预测当前的单词;而Skip-Gram则是利用当前词来预测上下文。

Embedding
Word2Vec中从输入到隐层的过程就是Embedding的过程。 Embedding的过程就是把多维的onehot进行降维的过程,是个深度学习的过程。满足:
- 嵌入层向量长度可设置
- 映射过程是全连接
- 嵌入层的值可训练
- 由高维度映射到低纬度,减少参数量

Skip-gram的原理

在embedding的基础上再加上一个输出层就是Skip-gram的过程了。根据某个词,然后分别计算它前后出现某几个词的各个概率。 如果有这样一个词序列 (你真漂亮)那么就会有四个1-hot 编码的输入向量: 1000, 0100,0010,0001。这就是可能的CBow模型的输入,假设我们当前的输入是0100,也就是“真”这个字。
再来看输出,假如我们希望预测“真”这个词的上下文,,比如说取前后各一个。
那么就会有两个output,刚才说了每个output是一个概率Vector, 假设这两个output Vector是(0.3, 0.5, 0.7,), (0.1,0.9,0.1)。第一个(0.3,0.5,0.7)中的数字表示的就是“你”出现在“真”之前一位的概率是0.3, “真”出现在“真”之前一位的概率是0.5, “漂亮”出现在“真”前一位的概率是0.7。同样,后一个向量(0.1,0.9,0.1)则表示“你”出现在“真”之后的概率是0.1,“真”出现在“真”之后的概率是0.1,……。
这样的话,只要我们给定了一个词,整个CBow网络就可以得到这个词上下文中各个词出现的概率,我们用蒙特卡洛模拟的方法根据哪些概率值去采样,就能得到一个具体的上下文。 然后就是优化了,使得输入的词之间“真漂亮”之间的概率足够大。 写出目标函数:
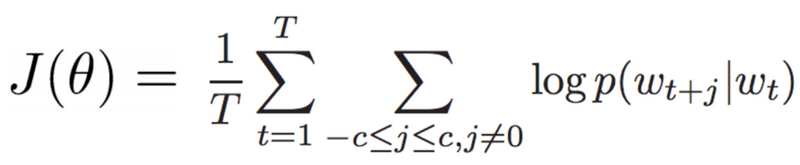
T是语料库单词的总个数,p(wt+j|wt)是已知当前词wt,预测周围词的总概率对数值。
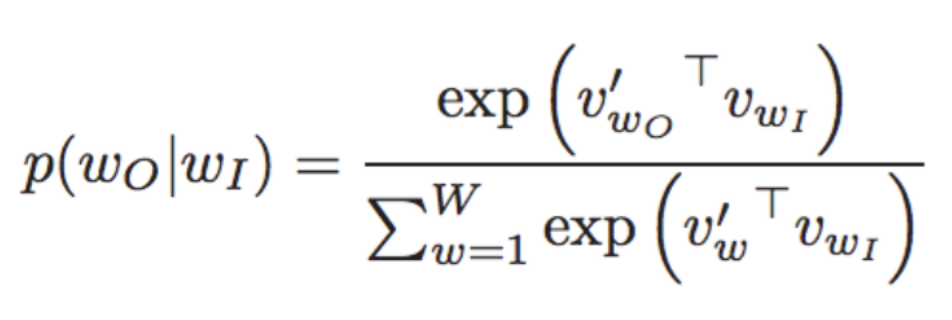
负采样
然而,在实际的计算过程中,运算量过于巨大,于是人们就像出了一个绝妙的解决办法,从而快速地完成任务。这种方法就被称为“负采样”(Negative sampling)。 负采样的核心思想是,如果将自然语言看作是一串单词的随机组合,那么它的出现概率是很小的。于是,如果我们将拼凑的单词随机组合(负采样)起来将会以很大的概率不会出现在当前文章中。于是,我们很显然应该至少让我们的模型在这些负采样出来的单词组合上面出现概率应该尽可能地小,同时要让真正出现在文中的单词组合出现概率大。这样我们的模型才足够有效。于是,我们的目标变成了优化新的概率函数:
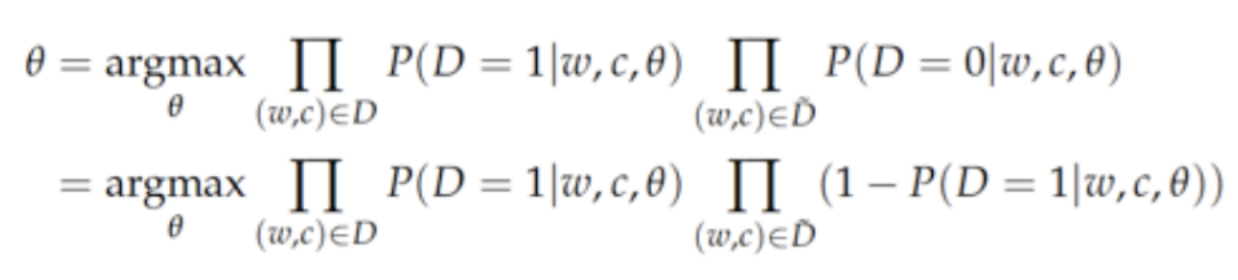
参考资料
https://cloud.tencent.com/developer/article/1148561
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/102747533

- 点赞
- 收藏
- 关注作者
评论(0)