NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词

【摘要】 NLP(1) | 词向量one hot编码词向量编码思想
分词的概念
简单来说就是把词进行分开,分词的难点: 1.如何避免歧义,如:“白开水不如果汁甜”。如何让机器避免将“如果”分到一起。 2.如何识别未登录词,并判断词性(人物,地点) 解决歧义的方法有很多,使用n_gram模型或者概率统计在解决歧义的作用下很好实...
NLP(1) | 词向量one hot编码词向量编码思想
分词的概念
简单来说就是把词进行分开,分词的难点: 1.如何避免歧义,如:“白开水不如果汁甜”。如何让机器避免将“如果”分到一起。 2.如何识别未登录词,并判断词性(人物,地点) 解决歧义的方法有很多,使用n_gram模型或者概率统计在解决歧义的作用下很好实现,如下面要介绍的HMM和CRF.
分词方法分类
- 基于词典的分词算法 基于词典的分词算法又称为机械分词算法,它是按照一定的策略将待分析的汉字串与一个“充分大的机器词典”中的词条进行匹配 , 若在词典中找到某个字符串, 则匹配成功,认为这个字串是词并将之切分出来。基于词典的分词算法有三个要素,分词词典、扫描方向(正向、逆向)和匹配原则(最大匹配,最小匹配等)[2]。 正向最大匹配算法。假设词典里词条的最大长度是Maxlen,则每次从文本最左边截取一个字符串,其长度为Maxlen,把该字串在词典中进行匹配,如果匹配成功,则将这个词从句子中切分出来;若匹配不成功,则将这个字串的最后一个字去掉,再将新得到的字串在词典中匹配。循环这个过程,直到切分出所有的词。
- 基于统计的分词算法和基于理解的分词算法 基于统计的分词算法主要思想是,词是稳定的字的组合,两个字在文本中连续出现的次数越多,就越有可能组合成一个词。因此这类算法通过对大量文本的统计,根据字串在文本中出现的统计频率来决定其是否构成一个词。其主要的统计模型有:互信息、N元文法模型、神经网络模型和隐马尔科夫模型(HMM)等。
下面就介绍一下最大随机场和隐马可夫模型在中文分词中的应用
CRF
- 原理 用一句话来解释就是“有序列的分类”。 就是在原来分类的基础上考虑到了时序,开始(B),中间(B),结尾(E),以及单字构成的词(S) CRF分词的过程就是对词位标注后,将B和E之间的字,以及S单字构成分词 CRF学习的过程: 就是描述一些特征配置:当前词语是xx,上个词xx,满足这种配置的,特征函数输出就是1,不然是0。每个词都有同样多的特征函数判断,所以是全局优化值。预测的过程就是利用每种特征配置给标签打分,然后打分结果加权求和,打分最高的标签,就是预测结果。 训练方法: 线性链的条件随机场跟线性链的隐马尔科夫模型一样,一般推断用的都是维特比算法。这个算法是一个最简单的动态规划。首先我们推断的目标是给定一个X,找到使P(Y|X)最大的那个Y嘛。然后这个Z(X),一个X就对应一个Z,所以X固定的话这个项是常量,优化跟他没关系(Y的取值不影响Z)。然后 exp也是单调递增的,也不带他,直接优化exp里面。所以最后优化目标就变成了里面那个线性和的形式,就是对每个位置的每个特征加权求和。比如说两个状态的话,它对应的概率就是从开始转移到第一个状态的概率加上从第一个转移到第二个状态的概率,这里概率是只exp里面的加权和。那么这种关系下就可以用维特比了。
- 维特比原理 首先你算出第一个状态取每个标签的概率,然后你再计算到第二个状态取每个标签得概率的最大值,这个最大值是指从状态一哪个标签转移到这个标签的概率最大,值是多 少,并且记住这个转移(也就是上一个标签是啥)。然后你再计算第三个取哪个标签概率最大,取最大的话上一个标签应该是哪个。以此类推。整条链计算完之后, 你就知道最后一个词去哪个标签最可能,以及去这个标签的话上一个状态的标签是什么、取上一个标签的话上上个状态的标签是什么,酱。这里我说的概率都是 exp里面的加权和,因为两个概率相乘其实就对应着两个加权和相加,其他部分都没有变。
- 与HMM区别 1)HMM是假定满足HMM独立假设。CRF没有,所以CRF能容纳更多上下文信息。 2)CRF计算的是全局最优解,不是局部最优值。 3)CRF是给定观察序列的条件下,计算整个标记序列的联合概率。而HMM是给定当前状态,计算下一个状态。 4)CRF比较依赖特征的选择和特征函数的格式,并且训练计算量大
- 示例 这里用的是genius包 Genius是一个开源的python中文分词组件,采用 CRF(Conditional Random Field)条件随机场算法。
-
#encoding=utf-8
-
import genius
-
text = u"""昨天,我和施瓦布先生一起与部分企业家进行了交流,大家对中国经济当前、未来发展的态势、走势都十分关心。"""
-
seg_list = genius.seg_text(
-
text,
-
use_combine=True,
-
use_pinyin_segment=True,
-
use_tagging=True,
-
use_break=True
-
)
-
print('\n'.join(['%s\t%s' % (word.text, word.tagging) for word in seg_list]))
['昨天', ',', '我', '和', '施瓦布', '先生', '一起', '与', '部分', '企业家', '进行', '了', '交流', ',', '大家', '对', '中国', '经济', '当前', '、', '未来', '发展', '的', '态势', '、', '走势', '都', '十分关心']
HMM分词
HMM是关于时序的概率模型,描述一个含有未知参数的马尔可夫链所生成的不 可观测的状态随机序列,再由各个状态生成观测随机序列的过程。HMM是一个 双重随机过程---具有一定状态的隐马尔可夫链和随机的观测序列. HMM由隐含状态S、可观测状态O、初始状态概率矩阵π、隐含状态转移概率矩 阵A、可观测值转移矩阵B(又称为混淆矩阵,Confusion Matrix); π和A决定了状态序列,B决定观测序列,因此HMM可以使用三元符号表示,称 为HMM的三元素:
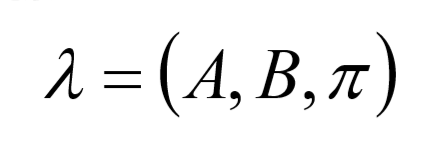
具体的原理部分会专门用一章来介绍。 具体代码可以见:https://github.com/tostq/Easy_HMM
参考
https://cloud.tencent.com/developer/article/1163101
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/102749851

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)