NLP(5) | 命名实体识别

【摘要】 NLP(1) | 词向量one hot编码词向量编码思想
NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词
NLP(3)| seq to seq 模型
NLP(4) | 用词向量技术简单分析红楼梦人物关系用n-gramma生成词向量word2vect进行模型训练
为什么需要实体识别
普通的工具如hanlp,htp,不能识别特定领域的专有名词,所以需...
NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词
NLP(4) | 用词向量技术简单分析红楼梦人物关系用n-gramma生成词向量word2vect进行模型训练
为什么需要实体识别
普通的工具如hanlp,htp,不能识别特定领域的专有名词,所以需要实体识别的算法。下面就以医疗专业为例子来谈一下医疗专业的命名实体识别。
标注
- 人工标注
- 机器标注bootstrapping,例如给文中的水果打标签,给定“苹果”,会自动把文中其他的“桃子”,“李子”等自动标注出来(百度)
- 医疗专业中标注比如:比如检测手段“头 ct”,“腔隙性脑梗死”是疾病,他们的关系是:检测手段证明了疾病

- 先边界识别 然后进行类别判定
例如医疗需要识别的命名实体的类型有疾病、疾病诊断分类、症状、检查、治疗在这五类以及疾病和症状的修饰信息。;对应英文分别是(Disease)(Disease Type) (Symptom) (Test) (Treatment)
-
关系抽取研究主要关注这六类实体关系的抽取: 治疗和疾病之间的关系, 比如治疗施 加于疾病;
-
治疗和症状之间的关系, 比如为缓解症状而施加的治疗; 检查和疾病之间的关系, 比如检查证实疾 病;
-
检查和症状之间的关系, 比如检查发现症状; 疾病和症状之间的关系, 比如疾病导致症状;
-
疾病和疾病诊 断分类之间的关系, 该关系表示疾病的进展程度。
-
关系抽取研究主要关注这六类实体关系的抽取: 治疗和疾病之间的关系, 比如治疗施 加于疾病;
-
治疗和症状之间的关系, 比如为缓解症状而施加的治疗; 检查和疾病之间的关系, 比如检查证实疾 病;
-
检查和症状之间的关系, 比如检查发现症状; 疾病和症状之间的关系, 比如疾病导致症状;
-
疾病和疾病诊 断分类之间的关系, 该关系表示疾病的进展程度。
- 修饰
分别是否认(absent)、非患者本人(family)、当前的(present)、有条件的 (conditional)、可能的(possible)、待证实的(hypothetical)、偶有的(occasional)
-
中文电子病历命名实体和实体关系标注体系及语料库构建 9 在是否发生患者本人这个方面有两个修饰:
-
(1)否认: 患者主动否认、或肯定不发生于患者身上。 比如: 各瓣膜区未闻及病理性杂音。 全腹无压痛、反跳痛及肌紧张。 腹壁静脉曲张: 无
-
(2)非患者本人: 发生于患者家属, 该种修饰可能和“否认”重叠, 若发生此种情况, 选择否认。 比如: 其父母均患有糖尿病 在发生于患者本人的确定程度这个方面有五个修饰:
-
(3)当前的: 肯定发生或正在发生于患者本人的疾病和症状。 比如: 头晕、呕吐伴右下肢无力。 自诉有冠心病史。 头CT示:双侧多发腔梗。
-
(4)有条件的: 当前不一定发生, 在某种条件具备的情况下, 才发生。 比如: 该患者于入院前3个月开始出现阵发性胸闷、心慌, 常于饮酒后出现。
-
(5)可能的: 不确定当前会发生, 需要进一步的证据才能确定。 比如: 不排除缺血性疾病。 右肺中下叶考虑创伤性湿肺。 临床初步诊断: 脑梗死、高血压病、糖尿病。
-
(6)待证实的: 当前不会发生, 但预期会发生。 比如: 手术一周后会有局部瘙痒 多在皮疹出现后1~4周左右出现血尿和 (或) 蛋白尿。
-
(7)偶有的: 指症状或者疾病当前不经常出现, 或者出现的频率较低。 比如: 病程中患者走路不稳, 偶有头晕。 大便偶有一过性发白。 时有胸闷气短。
- 标注
-
3.1疾病 DIS,DISEASE
-
疾病必须是能够治疗的,其语义范围包括:疾病或者综合征、受伤或中毒、先天性畸形、病毒细菌、病理功能、细胞或分子功能障碍、获得性异常、解剖异常、肿瘤进程、精神或行为障碍等。
-
1。1。1 疾病诊断分型 DT, DISEASE TYPE
-
疾病的具体分类,表示疾病的进展程度,疾病诊断分类一般出现在诊断里。如:
-
1)失代偿期 DT
-
2)III期DT
-
3)II型 DT
-
3.2 症状
-
症状是能够被改善或治愈的,并且能够被否定词修饰,为疾病的表现。包括患者向医生陈述的不适感觉(症状)和医生观察到的(体征)或者检查结果,如:
-
3.2.1患者向医生陈述的不适感觉(症状) SYM,SYMPTOM
-
1)疼痛时伴有右下肢活动受限。(“疼痛“ 、”右下肢活动受限”);
-
2)伴活动后心慌气短。(“心慌”、“气短”)
-
3.2.2医生观察到的(体征)ST
-
1)双肺听诊可闻及少量痰鸣音。(“痰鸣音”)
-
2)自带胸片示左下肺症病变。(“左下肺症病变”)
-
3)双肺听诊无著征。(“著征”)
-
3.3 检查 TES,TEST
-
检查是为了发现、证实疾病或症状,找到更多关于疾病或症状的信息而施加给患者的检查项目,包括:化验过程,诊断过程等。如:
-
1)头CT显示脑实质内高密度灶。(“CT”)
-
2)血压最高达到180/130mmHg。(“血压”)
-
3)双肺听诊无著征。(“听诊”)
-
4)自带胸片示左下肺症病变。(“胸片”)
-
3.4 治疗
-
治疗是能够治疗疾病或者缓解症状而施加给患者的手段,包括手术、药品、措施等。本标注语义类型包括:药物、手术。如:
-
3.4.1药品 DRU,DRUG
-
1)奥扎格雪、脑蛋白水解物等静点 (药物“奥扎格雪”和“脑蛋白水解物”)。
-
3.4.2手术 SUR,SURGERY
-
1)4年前行胆囊切除术。(手术“胆囊切除术”)
-
2)鼻内镜下行双筛、双上颌窦。(手术“鼻内镜”)
-
3.4.3措施(非手术,非药品的治疗) PRE,precaution
-
3.5实体修饰词标注
-
3.5.1 否认词(AT,,absent)标注:
-
各瓣膜区未闻及病理性杂音
-
全腹无压痛、反跳痛及肌紧张
-
3.5.2条件词(CL,conditional)标注:
-
在某种条件具备的情况下才发生的词。
-
比如:该患者于入院前3个月开始出现阵发性胸闷、心慌,常于饮酒后出现。
-
再如:吃红薯后血糖升高
-
3.5.3既往信息词(PT,past)
-
明确表示患者过去有过的治疗史或疾病症状,比如:
-
有多年心脏病史。
-
该患者于入院前3个月开始出现阵发性胸闷、心慌,常于饮酒后出现。
-
3.5.4时间标注统一标为TE
-
该患者于入院前3个月开始出现阵发性胸闷、心慌,常于饮酒后出现。
-
3.5.5!!可能性词:
-
不确定当前会发生,需要进一步的证据确认的词。如:
-
不排除缺血性疾病。/右肺中下叶考虑创伤性湿肺
-
待证实词:当前不会发生,但预期会发生。比如:
-
手术一周后会有局部瘙痒
-
3.5.6程度词标注(AM,AMOUNT),非量化的数量描述词,如大小、多少、程度(明显等)等
-
双肺听诊可闻及少量痰鸣音。
-
3.5.7解剖位置
-
器官(REG,REGION)
-
部位词(ORG,ORGEN)
-
3.5.8频率词 (FW,Frequency Word)
-
患者走路不稳,偶有头晕。时有胸闷气短。
-
反复胸闷,憋气,持续时间长短不等。
标注格式: 突发 AM 头晕 SYM 伴 O 恶心 SYM 呕吐 SYM 3小时 TE
分类标签id化
用BIESO来表示边界,大致可以分为如下标签,分别表示(开始,中间,结束,单个,其他) 也可以用BIO进行边界

对数据进行标注
分为训练集和测试集

设置配置参数
-
{
-
"model_type": "idcnn",特征抽取的模型
-
"num_chars": 3538,语料库的实体数目
-
"char_dim": 100,每个字的维度,embedding,把3538维度进行降维
-
"num_tags": 51,标记的种类数目
-
"seg_dim": 20,把边界BIOES增维,变成20维,上采样,所以每个字是120维度,使得边界信息更加丰富
-
"lstm_dim": 100,120维度,卷积之后的通道数
-
"batch_size": 20,
-
"emb_file": "/usr/zxy/NER_IDCNN_CRF/data/vec.txt",
-
"clip": 5,防止梯度爆炸
-
"dropout_keep": 0.5,
-
"optimizer": "adam",
-
"lr": 0.001,
-
"tag_schema": "iobes",
-
"pre_emb": true,预序列嵌入,embeding文件
-
"zeros": true,
-
"lower": false字母小写
-
}
模型保存位置及文件

后台部署
用flask、当然如果多并发,很多人同时在线可以用django
-
from flask import jsonify
-
from flask import Flask
-
from flask import request
-
@app.route('/', methods=['POST','GET'])
-
def get_text_input():
-
#http://127.0.0.1:5002/?inputStr="神经病"
-
#如果遇到显示问题:下载QQ浏览器,将编码设置为utf-8
-
text=request.args.get('inputStr')
-
#if len(text.strip())>0:
-
from flask import jsonify
-
if text:
-
aa=model.evaluate_line(sess, input_from_line(text, char_to_id), id_to_tag)
-
print(aa)
膨胀卷积
选择多次膨胀卷积来抽取特征,能减少参数量
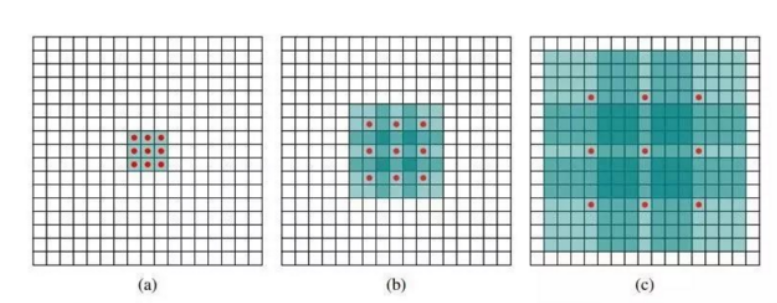
-
#膨胀卷积:插入rate-1个0 这里三层{1,1,2}相当于前两个没有膨胀
-
conv = tf.nn.atrous_conv2d(layerInput,w,rate=dilation,padding="SAME")
难点
- 标签
- 如何提升准确率
- 部分词太长
- 有些类别的词比较少
- 未登录词
如何优化模型
- 学习率
- 初试化参数
- doupout
- L2正则
- batchsize(影响相对小)
参考:
https://cloud.tencent.com/developer/article/1196139
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/102750518

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)