NLP(3)| seq to seq 模型

【摘要】 NLP(1) | 词向量one hot编码词向量编码思想
NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词
什么是Seq2Seq网络? 在Seq2Seq模型中采用了这种 Encoder-Decoder架构,其中 Encoder 是一个RNNCell(RNN ,GRU,LSTM 等) 结构,四层的LSTM结构使得能够提取足够多的特征,使得decode的模型...
NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词
- 什么是Seq2Seq网络? 在Seq2Seq模型中采用了这种 Encoder-Decoder架构,其中 Encoder 是一个RNNCell(RNN ,GRU,LSTM 等) 结构,四层的LSTM结构使得能够提取足够多的特征,使得decode的模型变好
- 几种Seq2Seq模式
1.学霸模式

2.普通作弊

3.学弱作弊

普通作弊的基础上,回顾上一刻的答案
4.学渣作弊(attention机制)
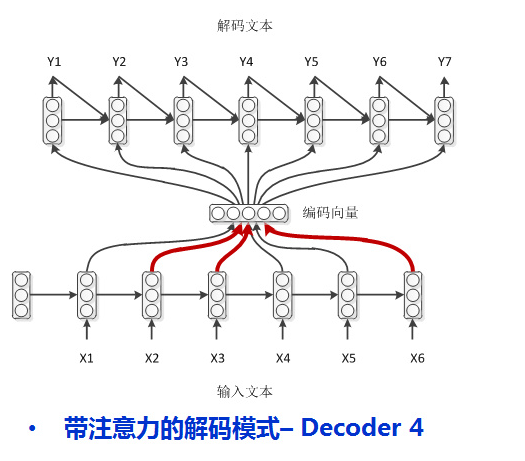
上课的时候划重点
- 应用场景 只要是序列到序列都可以用
- attention机制是怎么引入的?

第一步
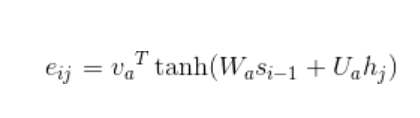
第二步:

第三步:

seqtoseq损失函数
损失函数为交叉熵损失函数,一般情况下,深度学习最后用softmax最为分类器一般都会选择用交叉熵损失函数
参考
https://cloud.tencent.com/developer/article/1163104
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/102750131

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)