五十八、2020美赛C题的思路以及个人Python的解法

@Author:Runsen
这是2020年美赛C题,当时三月份朋友找我搞定,今天在清理文件中发现了,于是做一个记录。这不是我的作业,我的专业可是化工。与这些没有什么关系。
阳光公司计划在线上市场上推出和销售三种新产品:微波炉,婴儿奶嘴和吹风机。他们已聘请您的团队作为顾问,通过顾客过去对其他竞争产品提供的相关评级和评论,识别关键模式、关系、措施和参数
- 告知其在线销售策略;
- 确定潜在的重要设计功能,以增强 产品的可取性。
- 阳光公司过去曾使用数据来为销售策略提供信息,但他们以前从未使用过这种特殊的组合和数据类型。
- 阳光公司对这些数据中以时间为基准的模式以及它们是否以有助于该公司制作成功产品的互动方式特别感兴趣。
为了帮助您,阳光公司的数据中心为您提供了该项目的三个数据文件:hair_dryer.tsv,microwave.tsv和pacifier.tsv。这些数据代表在数据指示的时间段内在亚马逊市场上购买微波炉、婴儿奶嘴和吹风机的客户提供的评级和评论。他们还提供了数据标签定义的词汇表。提供的数据文件包含了您应当使用的唯一数据。
| 数据集定义 | 每行代表划分为以下几列的数据 |
|---|---|
| marketplace(string) | 撰写评论的市场的2个字母的国家/地区代码。 |
| customer_id(string) | 随机标识符,可用于汇总单个作者撰写的评论。 |
| review_id(string) | 评论的唯一ID |
| product_id(string) | 评论所属的唯一产品ID |
| product_parent(string) | 随机标识符,可用于汇总同一产品的评论 |
| product_title(string | 产品的标题 |
| product_category(string) | 产品的主要消费者类别 |
| star_rating(int) | 评论的1-5星级 |
| helpful_votes(int) | 有帮助的投票数 |
| total_votes(int) | 评论获得的总票数 |
| vine(string) | 基于客户在Amazon社区中撰写准确而有见地的评论所获得的信任,邀请他们成为Amazon Vine Voices。亚马逊为Amazon Vine成员提供了供应商已提交给该程序的产品的免费副本。 Amazon不会影响Amazon Vine成员的意见,也不会修改或编辑评论。 |
| verified_purchase(string) | “ Y”表示亚马逊已验证撰写评论的人在亚马逊上购买了该产品,并且没有以大幅度折扣购买该产品。 |
| review_headline(string) | 评论的标题 |
| review_body(string) | 评论文本 |
| review_date(bigint) | 撰写评论的日期 |
要求:
1、分析所提供的三个产品数据集,以识别、描述和支持数学证据、有意义的定量和/或定性模式、关系、衡量标准和星级评定、评审之间的参数,以及帮助性评级,这将有助于阳光公司在他们的三个新的在线市场产品提供成功。
2、使用您的分析来解决以下来自Sunshine Company市场总监的具体问题和要求:
-
确定基于评级和评论的数据度量,这些数据度量是Sunshine Company在其三种产品在网上市场上销售后最需要跟踪的信息。
-
识别并讨论每个数据集中基于时间的度量和模式,这些度量和模式可能表明产品在在线市场上的声誉在增加或减少。
-
确定基于文本的度量值和基于评级的度量值的组合,这些度量值最好地指示潜在的成功或失败产品。
-
特定的明星收视率会引发更多的评论吗?例如,客户在看到一系列低星级评级后,是否更有可能撰写某种类型的评论?
-
基于文本的评论的特定质量描述,如“热情”、“失望”和其他,是否与评级水平密切相关?
3。给阳光公司的市场总监写一封一到两页的信,总结你团队的分析和结果。包括你的团队最自信地向市场总监推荐的结果的具体理由
思路
-
数据清理:数据中包括重复信息,同时存在很多垃圾信息,比如星级评论与文字评论极度不符的(一好一差)删除,同时删除没有帮助的投票数和评论获得的总票数为0的评论,我们还要确定已验证撰写评论的人在亚马逊上确定购买了该产品的真实用户。(这个我没有做处理,因为我不知道如何将一好一差进行删除)
-
判断产品的好坏:每个数据集中识别并讨论基于时间的度量和模式,这些度量和模式表明产品在在线市场中的声誉在上升还是下降,这样我们可以推销声誉更高的产品。(这个需要知道的是keras建立时间序列,回滚的办法)
-
建立产品服务体系:我们需要将使用LDA主题模型,提取出差评里的关键词,从而建立更加完整的产品服务体系。
-
客户在看到一系列低星级评级后,我们需要确定客户是否更有可能撰写某种类型的评论。因此我们需要将挖掘时间节点前的星级评价对时间节点后的评论是否存在联系,可以巧妙 的利用相关性分析解决此问题。例如仅考虑每一条评论与此前一周的评级的关 系,即可提取数据样本,作处理后利用spss作相关性分析。(没有采用SPSS)
本次采用了Python代码,使用keras进行了建立时间序列和LDA主题模型提评论的关键词
数据清理
1、去除重复数据
数据中包括重复信息和NA值,我们选择去除
data.drop_duplicates(inplace=True)
data.dropna(inplace=True)
- 1
- 2
2、去除没有购买的数据
我们认为verified_purchase=N的数据,具有没有研究的意思,因为并没有真实的购买产品,因此我们需要选择真实客户的数据
data = data[(data['verified_purchase'] == 'y')|(data['verified_purchase'] == 'Y') ]
- 1
3、去除没有帮助的数据
helpful_votes和total_votes如果都为0,我们认为毫无帮助,因此我们选择去除
# 删除没有帮助的投票数和评论获得的总票数为0的没有评论
data = data[(data['helpful_votes'] != 0)&(data['total_votes'] != 0)]
- 1
- 2
4、将评论等级分开
我们需要将评论中的停用词选择删除
# 读取停用词
stop = ''
with open('stopwords.txt','r',encoding='utf-8',errors='ignore') as s: for line in s: line = line.strip() stop += line
- 1
- 2
- 3
- 4
- 5
- 6
我们用dataList存放总评论内容,tagList存放总评论分数
import jieba
from nltk.corpus import stopwords dataList = [] tagList = []
for i in data.values: if int(i[7]) >= 4: flag = 1 elif int(i[7]) >= 3: flag = 2 else: flag = 3 # 将review_body分词 wordList = jieba.cut(i[-2], cut_all=True) # 去停用词 termsAll = list(set([term for term in wordList if term not in stop])) filtered = [w for w in termsAll if(w not in stopwords.words('english'))] dataList.append(filtered) tagList.append(str(flag))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
我们根据star_rating的分数,将将评论等级分开。根据常规:4、5属于好评,3中评,2,1属于差评,
data['tag'] = tagList
pos_data = data[data["tag"]== '1']
sec_data = data[data["tag"]== '2']
neg_data= data[data["tag"]== '3']
pos_review = []
for i in pos_data.review_body.values: # 将review_body分词 wordList = jieba.cut(i, cut_all=True) # 去停用词 termsAll = tuple(set([term for term in wordList if term not in stop])) pos_review.append(termsAll) sec_review = []
for i in sec_data.review_body.values: # 将review_body分词 wordList = jieba.cut(i, cut_all=True) # 去停用词 termsAll = tuple(set([term for term in wordList if term not in stop])) sec_review.append(termsAll)
neg_review = []
for i in neg_data.review_body.values: # 将review_body分词 wordList = jieba.cut(i, cut_all=True) # 去停用词 termsAll = tuple(set([term for term in wordList if term not in stop])) neg_review.append(termsAll)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
判断产品的好坏
时间序列预测是一类比较困难的预测问题。与常见的回归预测模型不同,输入变量之间的“序列依赖性”为时间序列问题增加了复杂度。RNN(recursive neural network)递归神经网络专门用来处理序列依赖性,同样LSTM在深度学习中广泛使用的一种递归神经网络。
我们创建新的df来存放data[‘star_rating’]评分数据
data.set_index(pd.to_datetime(data.review_date))
data.sort_index(inplace=True)
df = pd.DataFrame(index=data.index)
df['star_rating'] = data['star_rating']
- 1
- 2
- 3
- 4
我们回滚10天,预测客户评分
import numpy as np
look_back = 10
def create_dataset(dataset): dataX = [] dataY = [] for i in range(len(dataset) - look_back - 1): x = dataset[i: i+look_back, 0] dataX.append(x) y = dataset[i+look_back, 0] dataY.append(y) print('X: %s, Y: %s' % (x, y)) return np.array(dataX), np.array(dataY)
# Series转化ndarray
dataset = df.values.astype('float32')
# 训练集和测试集
train_size = int(len(dataset)*0.67)
validation_size = len(dataset) - train_size
train, validation = dataset[0: train_size, :], dataset[train_size: len(dataset), :]
X_train, y_train = create_dataset(train)
X_validation, y_validation = create_dataset(validation)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
下面我们使用keras,将前10天的评分作为输入变量,第10天的作为输出变量。
import math
import numpy as np
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
from pandas import read_csv
from matplotlib import pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.utils.vis_utils import plot_model
def build_model(): model = Sequential() model.add(Dense(units=12, input_dim=look_back, activation='relu')) model.add(Dense(units=8, activation='relu')) model.add(Dense(units=1)) model.compile(loss='mean_squared_error', optimizer='adam') return model
model = build_model()
model.fit(X_train, y_train, epochs=30, batch_size=2, verbose=1)
train_score = model.evaluate(X_train, y_train, verbose=0)
print('Train Score: %.2f MSE (%.2f RMSE)' % (train_score, math.sqrt(train_score)))
validation_score = model.evaluate(X_validation, y_validation, verbose=0)
print('Validation Score: %.2f MSE (%.2f RMSE)' % (validation_score, math.sqrt(validation_score)))
predict_train = model.predict(X_train)
predict_validation = model.predict(X_validation)
# 构建通过训练数据集进行预测的图表数据
# 依据给定形状和类型(shape[, dtype, order])返回一个新的空数组。
predict_train_plot = np.empty_like(dataset)
predict_train_plot[:, :] = np.nan
predict_train_plot[look_back:len(predict_train)+look_back, :] = predict_train
predict_validation_plot = np.empty_like(dataset)
predict_validation_plot[:, :] = np.nan
predict_validation_plot[len(predict_train)+look_back*2+1: len(dataset)-1, :] = predict_validation
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
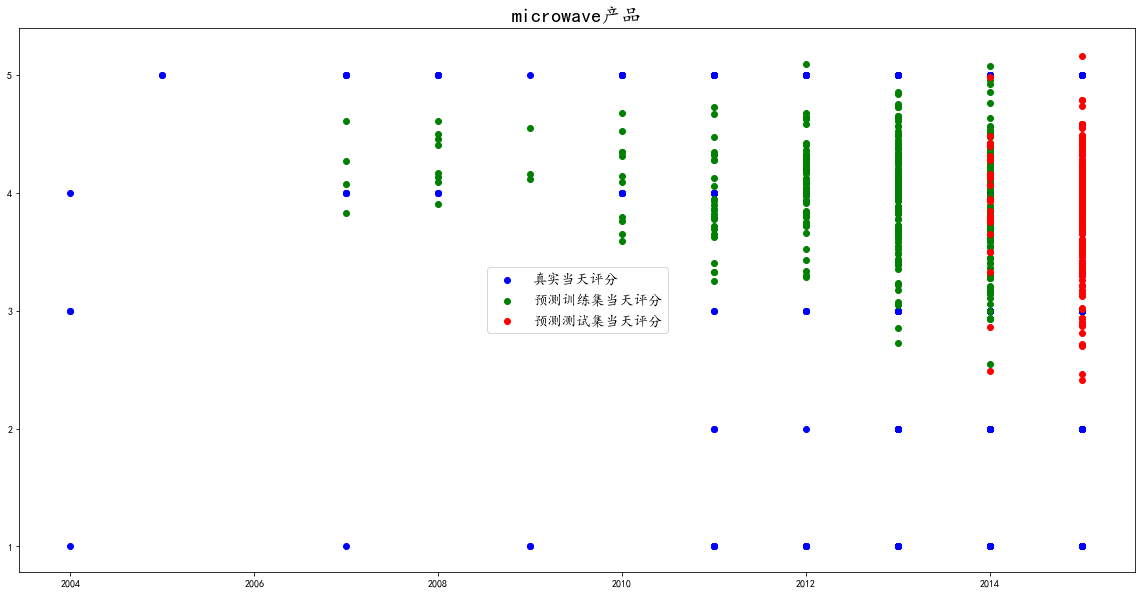
下面我们绘制散点图查看评分的具体分布
df["year"] = df.index.year
plt.figure(figsize=(20,10))
plt.scatter(df.year, dataset,color='blue',label="真实当天评分")
plt.scatter(df.year,predict_train_plot, color='green',label= "预测训练集当天评分")
plt.scatter(df.year,predict_validation_plot, color='red',label= "预测测试集当天评分")
plt.legend(fontsize='x-large')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这是hair_drye产品的评分分布预测

这是microwave产品的评分分布预测
这是pacifiter产品的评分分布预测
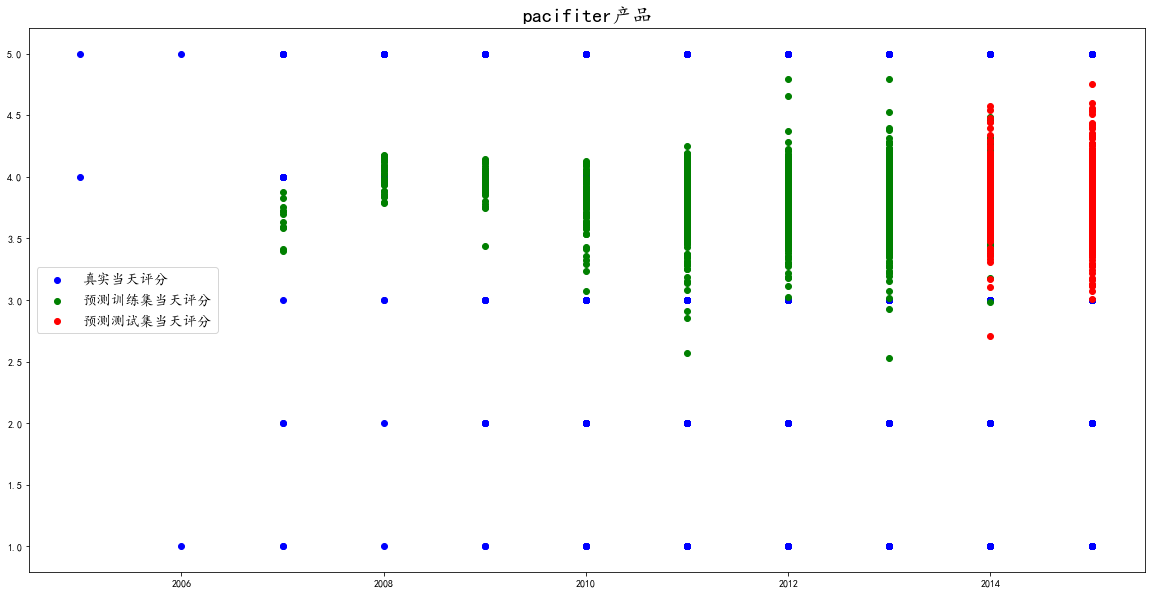
我们从图中看出其实现在三个产品都是处于3-5评分之间,并没有很严重的差评数据预测出来。
建立产品服务体系
我们使用我们需要将使用LDA主题模型,提取出差评里的关键词,从而建立更加完整的产品服务体系。
from gensim import corpora, models, similarities
dictionary = corpora.Dictionary(neg_review)
corpus = [dictionary.doc2bow(sentence) for sentence in neg_review]
# num_topics类似Kmeans指定K值
lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
# 第一类主题,最具有代表性的前10个分词
print (lda.print_topic(1,topn=10))
print (lda.print_topic(2,topn=10))
print (lda.print_topic(3,topn=10))
print (lda.print_topic(4,topn=10))
print (lda.print_topic(5,topn=10))
print (lda.print_topic(6,topn=10))
print (lda.print_topic(7,topn=10))
print (lda.print_topic(8,topn=10))
print (lda.print_topic(9,topn=10))
print (lda.print_topic(10,topn=10))
print (lda.print_topic(11,topn=10))
print (lda.print_topic(12,topn=10))
print (lda.print_topic(13,topn=10))
print (lda.print_topic(14,topn=10))
print (lda.print_topic(15,topn=10))
print (lda.print_topic(16,topn=10))
print (lda.print_topic(17,topn=10))
print (lda.print_topic(18,topn=10))
print (lda.print_topic(19,topn=10))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在20个主题中,我们查找出现多次的关键词
这是hair_drye产品的差评中的关键词:
product,dry,money,problem,disappointed,months,work,hair,bad。
因此,我们认为客户给与hair_drye产品差评的原因,可能是金钱,或者客户使用出现了问题等原因
这是microwave产品的差评中的关键词:
product,return,door,service,back,microwave,dangerous,power,issues
因此,我们认为客户给与microwave产品差评的原因,可能是service服务不好,客户认为使用时出现危险。
这是pacfier产品的差评中的关键词:
small,product,pacifiers,disappointed,months,quality,size
因此,我们认为客户给与pacfie产品差评的原因,可能是产品大小不行,客户认为太小了,质量出现问题
同样的我们可以提取出好评里的关键词
from gensim import corpora, models, similarities
dictionary = corpora.Dictionary(pos_review)
corpus = [dictionary.doc2bow(sentence) for sentence in pos_review]
# num_topics类似Kmeans指定K值
lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
# 第一类主题,最具有代表性的前10个分词
print (lda.print_topic(1,topn=10))
print (lda.print_topic(2,topn=10))
print (lda.print_topic(3,topn=10))
print (lda.print_topic(4,topn=10))
print (lda.print_topic(5,topn=10))
print (lda.print_topic(6,topn=10))
print (lda.print_topic(7,topn=10))
print (lda.print_topic(8,topn=10))
print (lda.print_topic(9,topn=10))
print (lda.print_topic(10,topn=10))
print (lda.print_topic(11,topn=10))
print (lda.print_topic(12,topn=10))
print (lda.print_topic(13,topn=10))
print (lda.print_topic(14,topn=10))
print (lda.print_topic(15,topn=10))
print (lda.print_topic(16,topn=10))
print (lda.print_topic(17,topn=10))
print (lda.print_topic(18,topn=10))
print (lda.print_topic(19,topn=10))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这是hair_drye产品的好评中的关键词:
price,dry,money,quickly,powerful,recommend,heat,hair,easy。
因此,我们认为客户给与hair_drye产品好评的原因,可能是金钱,或者客户使用时觉得产品powerful,quickly和easy,有可能recommend给别人
这是microwave产品的好评中的关键词:
microwave,small,great,power,happy,ordered,space,size
因此,我们认为客户给与microwave产品差评的原因,可能是客户使用觉得很好,心情高兴。
这是pacfier产品的好评中的关键词:
great,safe,constantly,love,sanitize,automatic,effort,excellent
money,quickly,powerful,recommend,heat,hair,easy。
因此,我们认为客户给与hair_drye产品好评的原因,可能是金钱,或者客户使用时觉得产品powerful,quickly和easy,有可能recommend给别人
这是microwave产品的好评中的关键词:
microwave,small,great,power,happy,ordered,space,size
因此,我们认为客户给与microwave产品差评的原因,可能是客户使用觉得很好,心情高兴。
这是pacfier产品的好评中的关键词:
great,safe,constantly,love,sanitize,automatic,effort,excellent
因此,我们认为客户给与pacfie产品好评的原因,可能是产品安全,心情高兴
附上代码和数据集:链接:https://pan.baidu.com/s/1vRCVsFZdiQ9Fvz95yNrYcw
提取码:rl2t
后记:其实根本不需要用Python写代码,直接使用Stata几十分钟就可以搞定。
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/108019294

- 点赞
- 收藏
- 关注作者
评论(0)