Machine Learning | (5) Scikit-learn的分类器算法-朴素贝叶斯

Machine Learning | (1) Scikit-learn与特征工程
Machine Learning | (2) sklearn数据集与机器学习组成
Machine Learning | (3) Scikit-learn的分类器算法-k-近邻
Machine Learning | (4) Scikit-learn的分类器算法-逻辑回归
Machine Learning | (5) Scikit-learn的分类器算法-朴素贝叶斯
朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一个非常简单,但是实用性很强的分类模型。朴素贝叶斯分类器的构造基础是贝叶斯理论。
概率论基础
概率定义为一件事情发生的可能性。事情发生的概率可以 通过观测数据中的事件发生次数来计算,事件发生的概率等于改事件发生次数除以所有事件发生的总次数。举一些例子:
- 扔出一个硬币,结果头像朝上
- 某天是晴天
- 某个单词在未知文档中出现
我们将事件的概率记作P(X),那么假设这一事件为X属于样本空间中的一个类别,那么0≤P(X)≤1。
联合概率与条件概率
- 联合概率
是指两件事情同时发生的概率。那么我们假设样本空间有一些天气数据:
是指两件事情同时发生的概率。那么我们假设样本空间有一些天气数据:
| 编号 | 星期几 | 天气 |
|---|---|---|
| 1 | 2 | 晴天 |
| 2 | 1 | 下雨 |
| 3 | 3 | 晴天 |
| 4 | 4 | 晴天 |
| 5 | 1 | 下雨 |
| 6 | 2 | 下雪 |
| 7 | 3 | 下雪 |

-
a = "life is short,i like python"
-
b = "life is too long,i dislike python"
-
c = "yes,i like python"
-
label=[1,0,1]
词袋法的特征值计算
若使用词袋法,且以训练集中的文本为词汇表,即将训练集中的文本中出现的单词(不重复)都统计出来作为词典,那么记单词的数目为n,这代表了文本的n个维度。以上三个文本在这8个特征维度上的表示为:
| life | is | i | short | long | like | dislike | too | python | yes | |
|---|---|---|---|---|---|---|---|---|---|---|
| a' | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| b' | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 |
| c' | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
上面a',b'就是两个文档的词向量的表现形式,对于贝叶斯公式,从label中我们可以得出两个类别的概率为:
P(ci=1)=0.5,P(ci=0)=0.5
对于一个给定的文档类别,每个单词特征向量的概率是多少呢?
提供一种TF计算方法,为类别y_kyk每个单词出现的次数N_iNi,除以文档类别y_kyk中所有单词出现次数的总数NN:
Pi=N/Ni
首先求出现总数,对于1类别文档,在a'中,就可得出总数为1+1+1+1+1+1=6,c'中,总共1+1+1+1=4,故在1类别文档中总共有10次
每个单词出现总数,假设是两个列表,a'+c'就能得出每个单词出现次数,比如P(w=python)=2/10=0.20000000,同样可以得到其它的单词概率。最终结果如下:
-
# 类别1文档中的词向量概率
-
p1 = [0.10000000,0.10000000,0.20000000,0.10000000,0,0.20000000,0,0,0.20000000,0.10000000]
-
# 类别0文档中的词向量概率
-
p0 = [0.16666667,0.16666667,0.16666667,0,0.16666667,0,0.16666667,0.16666667,0.16666667,0]
拉普拉斯平滑系数
为了避免训练集样本对一些特征的缺失,即某一些特征出现的次数为0,在计算P(X1,X2,X3,...,Xn∣Yi)的时候,各个概率相乘最终结果为零,这样就会影响结果。我们需要对这个概率计算公式做一个平滑处理:
Pi=N+α∗m / Ni+α
其中mm为特征词向量的个数,\alphaα为平滑系数,当\alpha{=}1α=1,称为拉普拉斯平滑
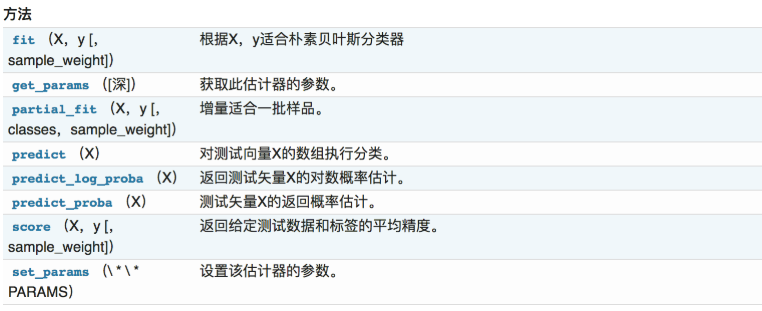
sklearn.naive_bayes.MultinomialNB
-
class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
-
"""
-
:param alpha:float,optional(default = 1.0)加法(拉普拉斯/ Lidstone)平滑参数(0为无平滑)
-
"""
-
互联网新闻分类
读取20类新闻文本的数据细节
-
from sklearn.datasets import fetch_20newsgroups
-
-
news = fetch_20newsgroups(subset='all')
-
-
print news.data[0]
上述代码得出该数据共有18846条新闻,但是这些文本数据既没有被设定特征,也没有数字化的亮度。因此,在交给朴素贝叶斯分类器学习之前,要对数据做进一步的处理。
20类新闻文本数据分割
-
from sklearn.cross_validation import train_test_split
-
-
X_train,X_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=42)
文本转换为特征向量进行TF特征抽取
-
from sklearn.feature_extraction.text import CountVectorizer
-
-
vec = CountVectorizer()
-
# 训练数据输入,并转换为特征向量
-
X_train = vec.fit_transform(X_train)
-
# 测试数据转换
-
X_test = vec.transform(X_test)
朴素贝叶斯分类器对文本数据进行类别预测
-
from sklearn.naive_bayes import MultinomialNB
-
-
# 使用平滑处理初始化的朴素贝叶斯模型
-
mnb = MultinomialNB(alpha=1.0)
-
-
# 利用训练数据对模型参数进行估计
-
mnb.fit(X_train,y_train)
-
-
# 对测试验本进行类别预测。结果存储在变量y_predict中
-
y_predict = mnb.predict(X_test)
性能测试
- 特点分析
朴素贝叶斯模型被广泛应用于海量互联网文本分类任务。由于其较强的特征条件独立假设,使得模型预测所需要估计的参数规模从幂指数量级想线性量级减少,极大的节约了内存消耗和计算时间。到那时,也正是受这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得该模型在其他数据特征关联性较强的分类任务上的性能表现不佳
参考资料
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/104300817

- 点赞
- 收藏
- 关注作者
评论(0)