Tensorflow |(1)初识Tensorflow

关于 TensorFlow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。这次的开源发布版本支持单pc或单移动设备上的计算
什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
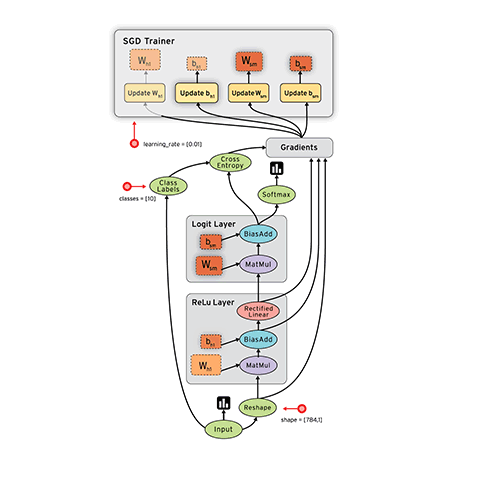
Tensorflow的特征
- 高度的灵活性
TensorFlow 不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用Tensorflow。你来构建图,描写驱动计算的内部循环。我们提供了有用的工具来帮助你组装“子图”(常用于神经网络),当然用户也可以自己在Tensorflow基础上写自己的“上层库”。定义顺手好用的新复合操作和写一个python函数一样容易,而且也不用担心性能损耗。当然万一你发现找不到想要的底层数据操作,你也可以自己写一点c++代码来丰富底层的操作。
- 真正的可移植性(Portability)
Tensorflow 在CPU和GPU上运行,比如说可以运行在台式机、服务器、手机移动设备等等。想要在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习的新想法?Tensorflow可以办到这点。准备将你的训练模型在多个CPU上规模化运算,又不想修改代码?Tensorflow可以办到这点。想要将你的训练好的模型作为产品的一部分用到手机app里?Tensorflow可以办到这点。你改变主意了,想要将你的模型作为云端服务运行在自己的服务器上,或者运行在Docker容器里?Tensorfow也能办到
- 多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的ipython界面来用Tensorflow尝试些想法,它可以帮你将笔记、代码、可视化等有条理地归置好。当然这仅仅是个起点——我们希望能鼓励你创造自己最喜欢的语言界面,比如Go,Java,Lua,Javascript,或者是R
- 性能最优化
比如说你又一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来?由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计算元素分配到不同设备上,Tensorflow可以帮你管理好这些不同副本。
初识tf
使用 TensorFlow, 你必须明白 TensorFlow:
Tensorflow有一下几个简单的步骤:
- 使用 tensor 表示数据.
- 使用图 (graph) 来表示计算任务.
- 在会话(session)中运行图s
关于新版本
TensorFlow提供多种API。最低级API为您提供完整的编程控制。请注意,tf.contrib.learn这样的高级API可以帮助您管理数据集,估计器,培训和推理。一些高级TensorFlow API(方法名称包含的那些)contrib仍在开发中。某些contrib方法可能会在随后的TensorFlow版本中发生变化或变得过时。这个模块类似于scikit-learn中算法模型。
在 TF 中发生的所有事,都是在会话(Session) 中进行的。所以,当你在 TF 中编写一个加法时,其实你只是设计了一个加法操作,而不是实际添加任何东西。所有的这些设计都是会在图(Graph)中产生,你会在图中保留这些计算操作和张量,而不是具体的值。
图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op的执行步骤被描述成一个图. 在执行阶段, 使用会话执行执行图中的op。我们来构建一个简单的计算图。每个节点采用零个或多个张量作为输入,并产生张量作为输出。一种类型的节点是一个常数。像所有TensorFlow常数一样,它不需要任何输入,它输出一个内部存储的值。我们可以创建两个浮点型常量node1 ,node2如下所示:
-
node1 = tf.constant(3.0, tf.float32)
-
node2 = tf.constant(4.0)
-
print(node1, node2)
最终的打印声明生成
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
他为什么不是输出结果,那是因为tensorflow中的图形节点操作必须在会话中运行,稍后介绍
构建图
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算.TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了.,后面我们会接触多个图的使用
默认Graph值始终注册,并可通过调用访问 tf.get_default_graph()
-
import tensorflow as tf
-
-
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点,加到默认图中.构造器的返回值代表该常量 op 的返回值.
-
matrix1 = tf.constant([[3., 3.]])
-
-
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
-
matrix2 = tf.constant([[2.],[2.]])
-
-
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.返回值 'product' 代表矩阵乘法的结果.
-
product = tf.matmul(matrix1, matrix2)
-
-
print tf.get_default_graph(),matrix1.graph,matrix2.graph
重要注意事项:此类对于图形构造不是线程安全的。所有操作都应从单个线程创建,或者必须提供外部同步。除非另有说明,所有方法都不是线程安全的
在会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将启动默认图。
调用Session的run()方法来执行矩阵乘法op, 传入product作为该方法的参数,会话负责传递op所需的全部输入,op通常是并发执行的。
-
# 启动默认图.
-
sess = tf.Session()
-
-
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.返回值 'result' 是一个 numpy `ndarray` 对象.
-
result = sess.run(product)
-
print result
-
-
# 任务完成, 关闭会话.
-
sess.close()
Session对象在使用完后需要关闭以释放资源,当然也可以使用上下文管理器来完成自动关闭动作。
op
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法、加法。tensorflow内建了很多种运算操作,如下表所示:
| 类型 | 示例 |
|---|---|
| 标量运算 | Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal |
| 向量运算 | Concat、Slice、Splot、Constant、Rank、Shape、Shuffle |
| 矩阵运算 | Matmul、MatrixInverse、MatrixDeterminant |
| 带状态的运算 | Variable、Assign、AssignAdd |
| 神经网络组件 | SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling |
| 存储、恢复 | Save、Restore |
| 队列及同步运算 | Enqueue、Dequeue、MutexAcquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、NextIteration |
feed
TensorFlow还提供了feed机制, 该机制可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁,直接插入一个 tensor。feed 使用一个 tensor 值临时替换一个操作的输入参数,从而替换原来的输出结果.
feed 只在调用它的方法内有效, 方法结束,feed就会消失。最常见的用例是将某些特殊的操作指定为"feed"操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符.并且在Session.run方法中增加一个feed_dict参数
-
# 创建两个个浮点数占位符op
-
input1 = tf.placeholder(tf.types.float32)
-
input2 = tf.placeholder(tf.types.float32)
-
-
#增加一个乘法op
-
output = tf.mul(input1, input2)
-
-
with tf.Session() as sess:
-
# 替换input1和input2的值
-
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
如果没有正确提供feed, placeholder() 操作将会产生错误
参考资料
2. https://tensorflow.google.cn/?hl=zh_cn
3. https://www.bbsmax.com/A/WpdK4XxXzV/
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/104333499

- 点赞
- 收藏
- 关注作者
评论(0)