二、分布式文件系统HDFS及其简单使用

【摘要】
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。
HDFS
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS ...

在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。
HDFS
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口。
HDFS是根据谷歌的论文:《The Google File System》进行设计的
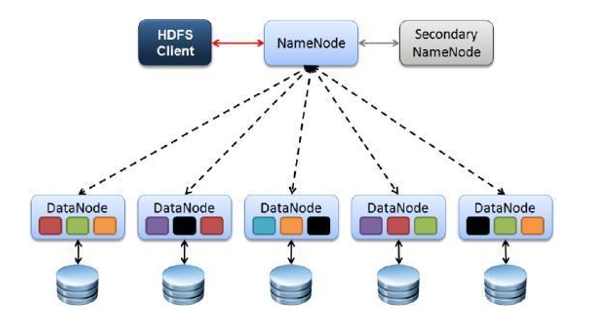
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
Client
Client是客户端。HDFS Client文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
NameNode就是 master,它是一个主管、管理者。管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息)。
NameNode管理 Block 副本策略:默认 3 个副本,处理客户端读写请求。
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/115606831

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)