一篇文章搞懂数据仓库:数据仓库架构-Lambda和Kappa对比

【摘要】 在介绍Lambda和Kappa架构之前,我们先回顾一下数据仓库的发展历程: 传送门-数据仓库发展历程
写在前面
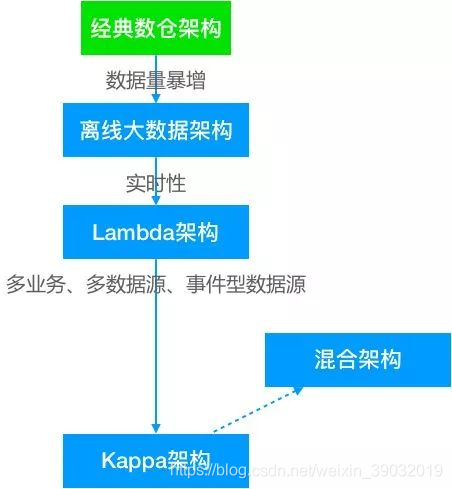
咳,随着数据量的暴增和数据实时性要求越来越高,以及大数据技术的发展驱动企业不断升级迭代,数据仓库架构方面也在不断演进,分别经历了以下过程:早期经典数仓架构 > 离线大数据架构 > Lambda > Kappa > 混合架构。
架构...
在介绍Lambda和Kappa架构之前,我们先回顾一下数据仓库的发展历程: 传送门-数据仓库发展历程
写在前面
咳,随着数据量的暴增和数据实时性要求越来越高,以及大数据技术的发展驱动企业不断升级迭代,数据仓库架构方面也在不断演进,分别经历了以下过程:早期经典数仓架构 > 离线大数据架构 > Lambda > Kappa > 混合架构。
| 架构 | 组成 | 特点 |
|---|---|---|
| 经典数仓架构 | 关系型数据库(mysql、oracle)为主 | 数据量小,实时性要求低 |
| 离线大数据架构 | hive,spark为主 | 数据量大,实时性要求低 |
| Lambda | hive,spark负责存量,strom/Flink负责实时计算 | 数据量大,实时性要求高 |
| Kappa | kafka、strom、Flink | 多业务,多数据源,事件型数据源 |
| 混合架构 |
ps.表中举例若有不当,欢迎指正
Lambda
Lambda架构原理
Lambda架构的核心思想是把大数据系统拆分成三层:Batch Layer,Speed Layer和Serving Layer。其中,Batch Layer负责数据集存储以及全量数据集的预查询。Speed Layer主要负责对增量数据进行计算,生成Realtime Views。Serving Layer用于响应用户的查询请求,它将Batch Views和Realtime Views的结果进行合并,得到最后的结果,返回给用户,如下图

Lambda架构的缺点
Lambda架构解决了大数据量下实时计算的问题,但架构本身也存在一定缺点。
- 实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
- 批量计算在计算窗口内无法完成:在IOT时代,数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题。
- 开发和维护的复杂性问题:Lambda 架构需要在两个不同的 API(application programming interface,应用程序编程接口)中对同样的业务逻辑进行两次编程:一次为批量计算的ETL系统,一次为流式计算的Streaming系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。这种系统实际上非常难维护
- 服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。
Kappa
Kappa架构原理
Kappa架构的核心思想包括以下三点:
- 用Kafka或者类似的分布式队列系统保存数据,你需要几天的数据量就保存几天。
- 当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
- 当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
 在Kappa架构下,只有在有必要的时候才会对历史数据进行重复计算,并且实时计算和批处理过程使用的是同一份代码。
在Kappa架构下,只有在有必要的时候才会对历史数据进行重复计算,并且实时计算和批处理过程使用的是同一份代码。
 在Kappa架构下,只有在有必要的时候才会对历史数据进行重复计算,并且实时计算和批处理过程使用的是同一份代码。
在Kappa架构下,只有在有必要的时候才会对历史数据进行重复计算,并且实时计算和批处理过程使用的是同一份代码。Lambda架构和Kappa架构优缺点对比
| 项目 | Lambda | Kappa |
|---|---|---|
| 数据处理能力 | 可以处理超大规模的历史数据 | 历史数据处理的能力有限 |
| 机器开销 | 批处理和实时计算需一直运行,机器开销大 | 必要时进行全量计算,机器开销相对较小 |
| 存储开销 | 只需要保存一份查询结果,存储开销较小 | 需要存储新老实例结果,存储开销相对较大 |
| 开发、测试难度 | 实现两套代码,开发、测试难度较大 | 只需面对一个框架,开发、测试难度相对较小 |
| 运维成本 | 维护两套系统,运维成本大 | 只需维护一个框架,运维成本小 |
小结
- Lambda 将全量历史数据和实时增量数据合并输出。
- Kappa 两个流协作输出,queries每次使用最新一个流处理结果
小编有话
目前很多准实时增量批处理方案也能满足实时性需求,从稳定性和运维成本上也表现更佳。
比如kudu(存储)+impala(计算)准实时方案,可以实现千万级数据的增量更新和olap查询,性能优异。
数仓系列传送门:https://blog.csdn.net/weixin_39032019/category_8871528.html
文章来源: notomato.blog.csdn.net,作者:kissme丶,版权归原作者所有,如需转载,请联系作者。
原文链接:notomato.blog.csdn.net/article/details/110790403

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)