深度学习和目标检测系列教程 4-300:目标检测入门之目标变量和损失函数

@Author:Runsen
目标定位
图像分类或图像识别模型只是检测图像中对象的概率。与此相反,对象定位是指识别图像中对象的位置。对象定位算法将输出对象相对于图像的位置坐标。在计算机视觉中,定位图像中对象的最流行方法是借助边界框来表示其位置。
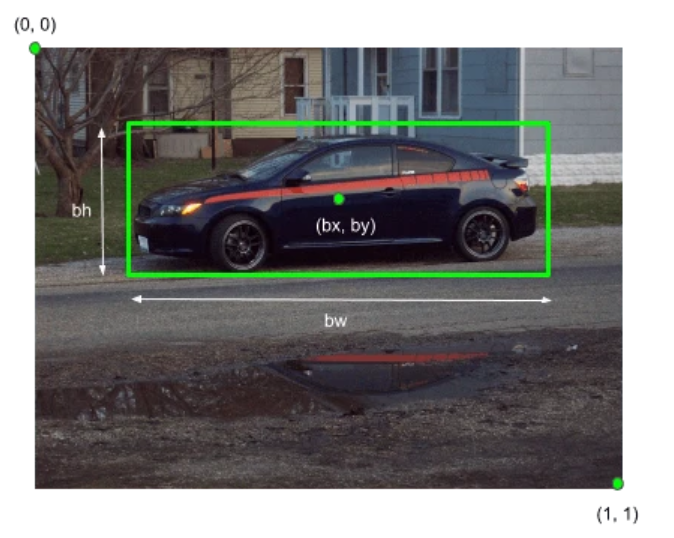
可以使用以下参数初始化边界框:
- bx, by : 边界框中心的坐标
- bw : 边界框的宽度 wrt 图像宽度
- bh : 边界框的高度 wrt 图像高度
定义目标变量
多类图像分类问题的目标变量定义为:
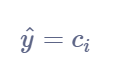
其中, C i C_i Ci是第 i i i类的概率。 例如,如果有四个类,则目标变量定义
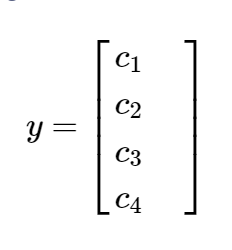
我们可以扩展这种方法来定义目标变量进行目标定位。目标变量定义为
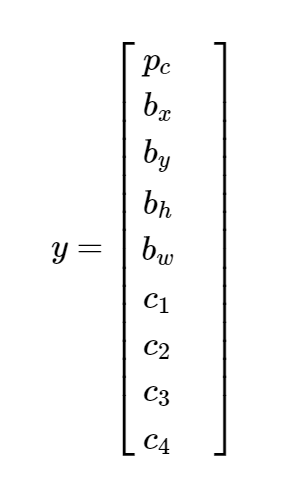
- p c p_c pc = 对象(即四个类)出现在边界框中的概率/置信度。
- bx,by,bh,bw = 边界框坐标。
- c i c_i ci= 对象所属第 i i i类的概率
例如,四个类别是“卡车”、“汽车”、“自行车”、“行人”,它们的概率表示为 c 1 , c 2 , c 3 , c 4 c1,c2,c3,c4 c1,c2,c3,c4
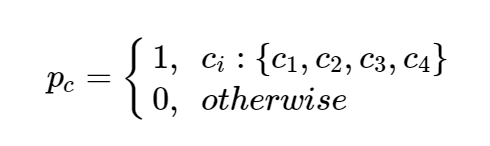
损失函数
让目标变量y的值表示为 y 1 , y 2 , … , y 9 y1,y2,…,y9 y1,y2,…,y9
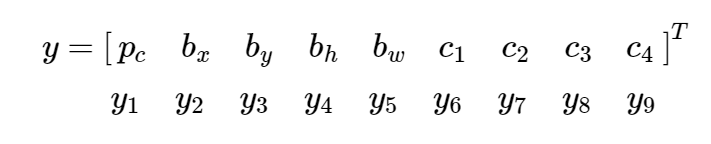
目标定位的损失函数定义为
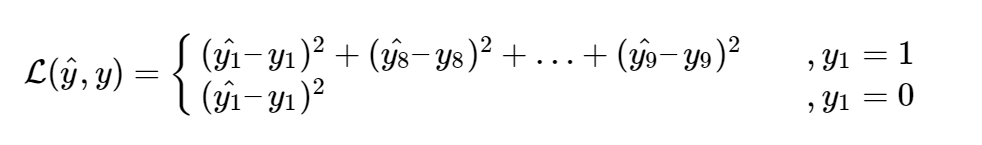
在实践中,我们可以在预测类 c 1 、 c 2 、 c 3 、 c 4 c1、c2、c3、c4 c1、c2、c3、c4的情况下使用考虑softmax输出的log函数。而对于边界框坐标,我们可以使用平方误差,对于 p c p_c pc(物体的置信度),我们可以使用logistic回归损失。
由于我们已经定义了目标变量和损失函数,我们现在可以使用神经网络对目标进行分类和定位。
物体检测
构建对象检测的一种方法是首先构建一个分类器,该分类器可以对对象的紧密裁剪图像进行分类。下图显示了此类模型的一个示例,其中模型在经过紧密裁剪的汽车图像数据集上进行训练,并且该模型预测图像是汽车的概率。
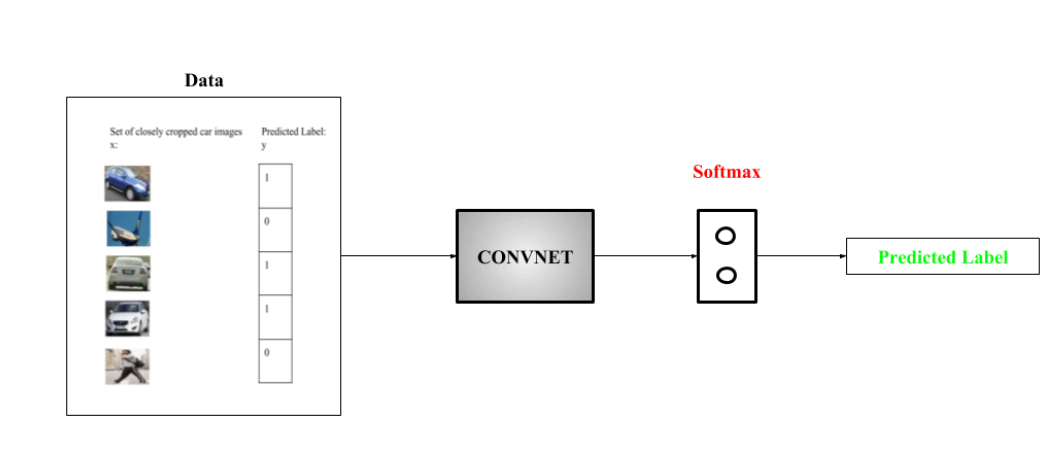
现在,我们可以使用这个模型来检测使用滑动窗口机制的汽车。在滑动窗口机制中,我们使用滑动窗口(类似于卷积网络中使用的滑动窗口)并在每张幻灯片中裁剪图像的一部分。裁剪的大小与滑动窗口的大小相同。然后将每个裁剪后的图像传递给一个 ConvNet 模型(类似于上图 中所示的模型),该模型反过来预测裁剪后的图像是汽车的概率。

在整个图像上运行滑动窗口后,调整滑动窗口的大小并再次在图像上运行。经过多次重复这个过程。由于之前裁剪了大量图像并通过 ConvNet 传递,因此这种方法在计算上既昂贵又耗时,使整个过程非常缓慢。滑动窗口的卷积实现有助于解决这个问题。
滑动窗口的卷积
在使用 convents 实现滑动窗口之前,分析如何将网络的全连接层转换为卷积层。
下面 显示了一个简单的卷积网络,具有两个完全连接的层,每个层的形状为 (400, )。
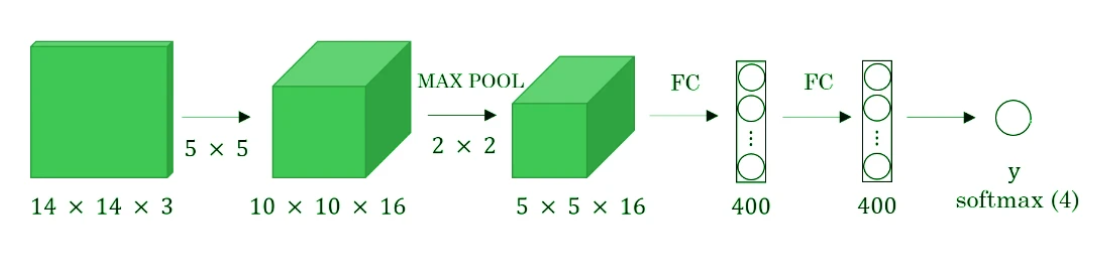
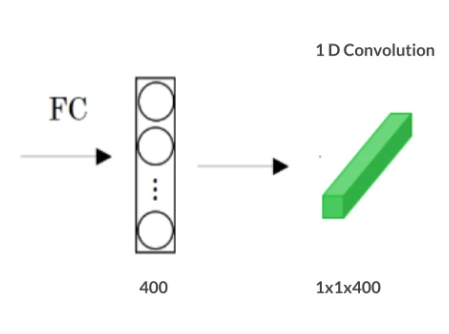
借助一维卷积层,可以将全连接层转换为卷积层。该层的宽度和高度等于 1,过滤器的数量等于全连接层的形状。
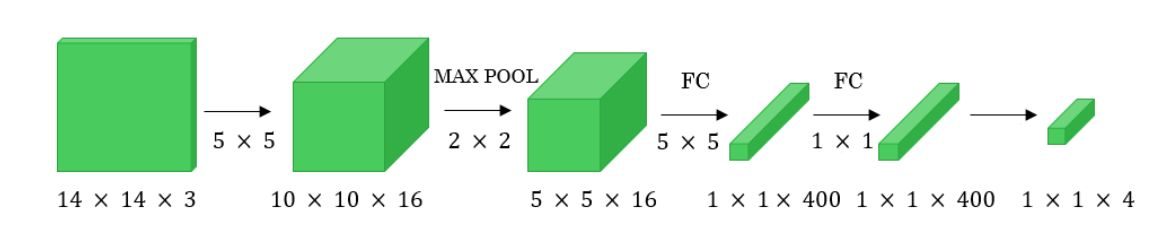
我们可以将全连接层转换为卷积层的概念应用到模型中,方法是将全连接层替换为一维卷积层。一维卷积层的滤波器数量等于全连接层的形状。此外,输出 softmax 层也是形状为 (1, 1, 4) 的卷积层,其中 4 是要预测的类数。 如下图 所示。
现在,扩展上述方法来实现滑动窗口的卷积版本。首先,考虑在以下表示中我们已经训练的 ConvNet(没有完全连接的层)。
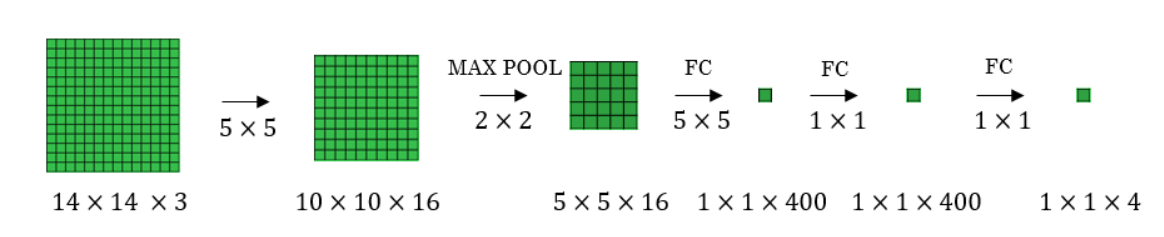
让我们假设输入图像的大小为16 × 16 × 3。如果我们使用滑动窗口方法,那么我们会将该图像传递给上面的 ConvNet 四次,每次滑动窗口都会裁剪一部分大小为14 × 14 × 3的输入图像并将其通过卷积网络。但不是这样,我们将完整图像(形状为16 × 16 × 3)直接输入到经过训练的 ConvNet 中(见图 7)。这导致形状为2 × 2 × 4的输出矩阵. 输出矩阵中的每个单元格表示可能裁剪的结果和裁剪图像的分类值。
例如,下图中输出的左侧单元格(绿色单元格)表示第一个滑动窗口的结果。其他单元格表示剩余滑动窗口操作的结果。
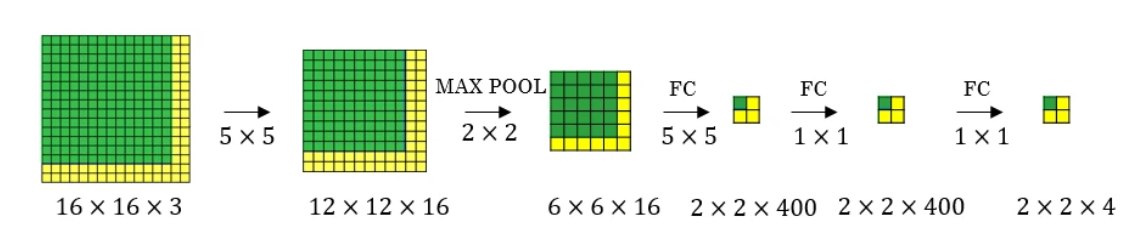
滑动窗口的步幅由 Max Pool 层中使用的过滤器数量决定。在上面的示例中,Max Pool 层有两个过滤器,因此滑动窗口以 2 的步幅移动,从而产生四个可能的输出。使用这种技术的主要优点是滑动窗口同时运行和计算所有值。因此,这种技术非常快。尽管这种技术的一个弱点是边界框的位置不是很准确。
YOLO
在使用卷积滑动窗口技术时解决预测准确边界框问题,效果最好的算法是YOLO 算法。由 Joseph Redmon、Santosh Divvala、Ross Girshick 和 Ali Farhadi 于 2015 年开发。YOLO 很受欢迎,因为它在实时运行的同时实现了高精度。之所以这样称呼该算法,是因为它只需要通过网络进行一次前向传播即可进行预测。
该算法将图像划分为网格,并对每个网格单元运行图像分类和定位算法。例如,我们有一个大小为256 × 256的输入图像。我们在图像上放置一个3 × 3 的网格。

接下来,我们在每个网格单元上应用图像分类和定位算法。对于每个网格单元,目标变量定义为
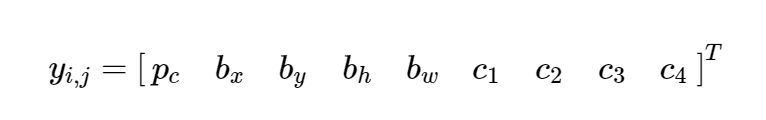
用卷积滑动窗口做一次。由于每个网格单元的目标变量的形状是1 × 9并且有 9 ( 3 × 3 ) 个网格单元,模型的最终输出将是:
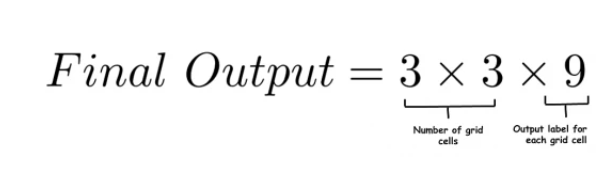
YOLO 算法的优点是速度非常快,并且可以预测更准确的边界框。此外,在实践中为了获得更准确的预测,我们使用更精细的网格,比如19 × 19,在这种情况下,目标输出的形状为19 × 19 × 9。
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/118394780

- 点赞
- 收藏
- 关注作者
评论(0)