23篇大数据系列(二)scala基础知识全集(史上最全,建议收藏)

作者简介:
蓝桥签约作者、大数据&Python领域优质创作者。管理多个大数据技术群,帮助大学生就业和初级程序员解决工作难题。
我的使命与愿景:持续稳定输出,赋能中国技术社区蓬勃发展!
大数据系列文章,从技术能力、业务基础、分析思维三大板块来呈现,你将收获:
❖ 提升自信心,自如应对面试,顺利拿到实习岗位或offer;
❖ 掌握大数据的基础知识,与其他同事沟通无障碍;
❖ 具备一定的项目实战能力,对于大数据工作直接上手;
评论、点赞、收藏是对我最大的支持!!!
大数据工程师系列专栏: 面试真题、开发经验、调优策略
大数据工程师知识体系:

大数据时代已经到来
最近几十年,高速发展的互联网,渗透进了我们生活的方方面面,整个人类社会都已经被互联网连接为一体。身处互联网之中,我们无时无刻不在产生大量数据,如浏览商品的记录、成交订单记录、观看视频的数据、浏览过的网页、搜索过的关键词、点击过的广告、朋友圈的自拍和状态等。这些数据,既是我们行为留下的痕迹,同时也是描述我们自身最佳的证据。
2014年3月,马云曾经在北京的一次演讲中说道:“人类正从IT时代走向DT时代”。7年过去了,正如马云预想的那样,大数据时代已经到来了。
大数据工程师的工作内容是什么?
而大数据时代,有一个关键性的岗位不得不提,那就是大数据工程师。想必大家也会好奇,大数据工程师,日常是做什么的呢?
| 1.数据采集 | 找出描述用户或对业务发展有帮助的数据,并将定义相关的数据格式,交由业务开发部门负责收集对应的数据。 |
| 2.ETL工程 | 对收集到的数据,进行各种清洗、处理、转化等操作,完成格式转换,便于后续分析,保证数据质量,以便得出可以信赖的结果。 |
| 3.构建数仓 | 将数据有效治理起来,构建统一的数据仓库,让数据与数据间建立连接,碰撞出更大的价值。 |
| 4.数据建模 | 基于已有的数据,梳理数据间的复杂关系,建立恰当的数据模型,便于分析出有价值的结论。 |
| 5.统计分析 | 对数据进行各种维度的统计分析,建立指标体系,系统性地描述业务发展的当前状态,寻找业务中的问题,发现新的优化点与增长点。 |
| 6.用户画像 | 基于用户的各方面数据,建立对用户的全方位理解,构建每个特定用户的画像,以便针对每个个体完成精细化运营。 |
大数据工程师必备技能
那么,问题来了,如果想成为一名大数据工程师,胜任上述工作内容,需要具备什么样的条件?拥有什么样的知识呢?
| 分类 |
子分类 |
技能 |
描述 |
| 技 术 能 力 |
编程基础 |
Java基础 |
大数据生态必备的java基础 |
| Scala基础 |
Spark相关生态的必备技能 |
||
| SQL基础 |
数据分析师的通用语言 |
||
| SQL进阶 |
完成复杂分析的必备技能 |
||
| 大数据框架 |
HDFS&YARN |
大数据生态的底层基石 |
|
| Hive基础 |
大数据分析的常用工具 |
||
| Hive进阶 |
大数据分析师的高级装备 |
||
| Spark基础 |
排查问题必备的底层运行原理 |
||
| Spark SQL |
应对复杂任务的利刃 |
||
| 工具 |
Hue&Zeppelin |
通用的探索分析工具 |
|
| Azkaban |
作业管理调度平台 |
||
| Tableau |
数据可视化平台 |
||
| 业务基础 |
数据收集 |
数据是如何收集到的? |
|
| ETL工程 |
怎么清洗、处理和转化数据? |
||
| 数据仓库基础 |
如何完成面向分析的数据建模? |
||
| 元数据中心 |
如何做好数据治理? |
||
| 分析思维 |
数据分析思维方法论 |
怎么去分析一个具体问题? |
|
| 排查问题思维 |
如何高效排查数据问题? |
||
| 指标体系 |
怎么让数据成体系化? |
||
Scala为什么会如此重要,作者觉得主要有以下三点原因:
1、因为spark
大部分从事大数据的工程师是先了解Spark进而再去选择学习Scala的,因为Spark是用Scala开发的。现在Spark是大数据领域的杀手级应用框架,只要搭建了大数据平台,都会大量使用Spark来处理和分析数据,而要想学好Spark,Scala这一关必须是要过的。顺便说一句,Kafka也是基于Scala开发的。
2、无缝对接大数据生态组件
众所周知,大数据生态的大部分组件都是java语言开发的。而Scala是一门基于JVM的语言,可以与java无缝混编,因此可以很好地融合到大数据生态圈。
3、适合大数据处理与机器学习
Scala的语法简洁而富有表达力,更容易掌握。Scala将面向对象与函数式编程相结合,功能强大且简练,非常适合用于处理各种数据。因此,在大数据处理与机器学习中占有重要的地位。
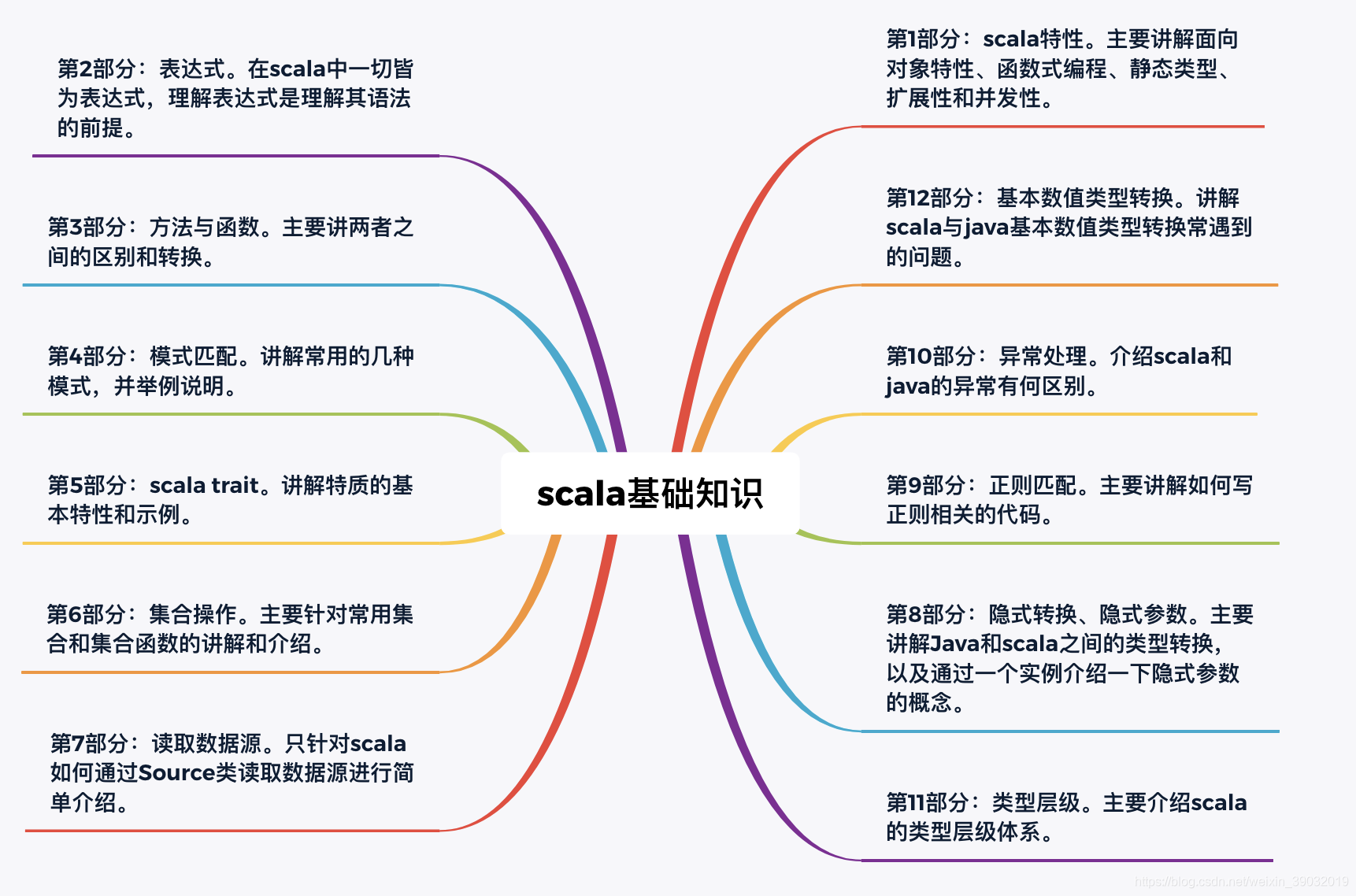
针对大数据分析师必须掌握的scala基础知识,本文的讲解思路如下:
第1部分:scala特性。主要讲解面向对象特性、函数式编程、静态类型、扩展性和并发性。
第2部分:表达式。在scala中一切皆为表达式,理解表达式是理解其语法的前提。
第3部分:方法与函数。主要讲两者之间的区别和转换。
第4部分:模式匹配。讲解常用的几种模式,并举例说明。
第5部分:scala trait。讲解特质的基本特性和示例。
第6部分:集合操作。主要针对常用集合和集合函数的讲解和介绍。
第7部分:读取数据源。只针对scala如何通过Source类读取数据源进行简单介绍。
第8部分:隐式转换、隐式参数。主要讲解Java和scala之间的类型转换,以及通过一个实例介绍一下隐式参数的概念。
第9部分:正则匹配。主要讲解如何写正则相关的代码。
第10部分:异常处理。介绍scala和java的异常有何区别。
第11部分:类型层级。主要介绍scala的类型层级体系。
第12部分:基本数值类型转换。讲解scala与java基本数值类型转换常遇到的问题。
scala基础知识
一、Scala特性
面向对象特性
Scala是一种纯面向对象的语言,彻底贯彻万物皆对象理念。对象的类型和行为是由类和特质来描述的。Scala引入特质(trait)来改进Java的对象模型,使得可以通过混入特质的方式,扩展类的功能。
函数式编程
Scala也是一种函数式语言,函数也能当成值来传递。Scala提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化。Scala的case class及其内置的模式匹配相当于函数式编程语言中常用的代数类型。
静态类型
Scala拥有一个强大表达能力的类型系统,通过编译时检查,保证代码的安全性和一致性。Scala具备类型推断的特性,这使得开发者可以不去额外标明重复的类型信息,让代码看起来更加整洁易读。
扩展性
Scala的设计秉承一项事实,即在实践中,某个领域特定的应用程序开发往往需要特定于该领域的语言扩展。Scala提供了许多独特的语言机制,可以以库的形式轻易无缝添加新的语言结构。
二、表达式
在scala中,一切皆为表达式。scala非常推崇表达式语法,因为表达式语法,对函数式编程是非常友好的。对开发者而言,表达式语法,使得代码非常简洁易读。
举个例子,我们在定义方法时,会和声明变量一样,使用等号(=)连接,等号左侧是函数名、参数列表和返回值类型(可以省略),而等号右边便是一个由大括号({})包裹的多行表达式。
表达式,是一定会有返回值的。在java中使用void来声明无返回值的方法,而在scala里,这种情况也会有返回值,会返回一个Unit,这是一个特定的值,表示忽略方法的返回值。
三、方法与函数
初学scala时,往往会觉得方法和函数的概念有些模糊,在使用中可能会搞不清楚到底该使用方法还是函数。那怎么区分呢?关键是看这个函数是否在类中定义,在类中定义就是方法,所以Scala 方法是类的一部分。Scala 中的函数则是一个完整的对象,可以赋给一个变量。不过,在scala中,方法和函数是可以相互转化的。下面我们重点说下,如何把方法转为函数。
方法转函数
上文中提到任何方法都是在声明一个表达式,所以将方法转为函数也就非常简单了,相当于是把方法指向的表达式,又重新赋给了一个函数变量,这就是显式转化。还有另外一种写法,是通过偏应用函数的方式,将方法转化为一个新的函数,称作隐式转化。
1)隐式转化
val f2 = f1 _
2)显式转化
val f2: (Int) => Int = f1
四、模式匹配
模式匹配是检查某个值是否匹配某一个模式的机制。它是Java中的switch语句的升级版,同样可以用于替代一系列的 if/else 语句,以下介绍几种常用的模式匹配:常量模式、变量模式、通配符模式。
常量模式
常量模式匹配,就是在模式匹配中匹配常量。
object ConstantPattern{ def main(args:Array[String]) :Unit = { //模式匹配结果作为函数返回值 def patternShow(x : Any) = x match { //常量模式 case 5 => "五" case true => "真" case "test" => "字符串" case null => "null值" case Nil => "空列表" //变量模式 case x => "变量" //通配符模式 case _ => "通配符" } }}
变量模式和通配符模式,都可以匹配任意值,他们之间的区别是,变量模式匹配成功后,该变量中会存储匹配成功的值,在后续的代码中还可以引用,而通配符模式匹配成功后,不能再引用匹配到的值。另外要注意的是,由于模式匹配是按顺序匹配的,因此变量模式和通配符模式要写在表达式的最后面。
类型匹配模式
可以匹配输入变量的类型。
object TypePattern{ def main(args:Array[String]) :Unit = { //类型匹配模式 def typePattern(t : Any) = t match { case t : String => "String" case t : Int => "Intger" case t : Double => "Double" case _ => "Other Type" } }}
case class模式
构造器模式指的是,直接在case语句后面接类构造器,匹配的内容放置在构造器参数中。
object CaseClassPattern{ def main(args:Array[String]) :Unit = { //定义一个Person实例 val p = new Person("nyz",27) //case class 模式 def constructorPattern(p : Person) = p match { case Person(name,age) => "name =" + name + ",age =" + age case _ => "Other" } }}
模式守卫
为了让匹配更加具体,可以使用模式守卫,也就是在模式后面加上if判断语句。
object ConstantPattern{ def main(args:Array[String]) :Unit = { //模式匹配结果作为函数返回值 def patternShow(x : Any) = x match { //模式守卫 case x if(x == 5) => "守卫" //通配符模式 case _ => "通配符" } }}
Option匹配
在Scala中Option类型样例类用来表示可能存在或也可能不存在的值(Option的子类有Some和None)。Some包装了某个值,None表示没有值。
class OptionDemo { val map = Map (("a",18),("b",81)) //get方法返回的类型就是Option[Int] map.get("b") match { case some(x) => println(x) case None => println("不存在") }}
五、Scala Trait(特质)
Scala Trait(特质) 相当于 Java 的接口,但实际上它比接口的功能强大。与接口不同的是,它还可以定义属性和方法的实现。
一般情况下Scala的类只能够继承单一父类,但可以使用with关键字混入多个 Trait(特质) 。不过,如果一个scala类没有父类,那么它混入的第一个特质需要使用extends关键字,之后混入的特质使用with关键字。
Trait(特质) 定义的方式与类相似,但它使用的关键字是 trait,如下所示:
trait Equal { def isEqual(x: Any): Boolean def isNotEqual(x: Any): Boolean = !isEqual(x)}
以上特质(Equal)由两个方法组成:isEqual 和 isNotEqual。isEqual 方法没有定义方法的实现,isNotEqual定义了方法的实现。子类继承特质可以实现未被实现的方法。
以下演示了特质的完整实例:
trait Equal { def isEqual(x: Any): Boolean def isNotEqual(x: Any): Boolean = !isEqual(x)}
class Point(xc: Int, yc: Int) extends Equal { val x: Int = xc val y: Int = yc def isEqual(obj: Any) = obj.isInstanceOf[Point] && obj.asInstanceOf[Point].x == x}
object Test { def main(args: Array[String]) { val p1 = new Point(2, 3) val p2 = new Point(2, 4) val p3 = new Point(3, 3)
println(p1.isNotEqual(p2)) println(p1.isNotEqual(p3)) println(p1.isNotEqual(2)) }}
执行以上代码,输出结果为:
$ scalac Test.scala $ scala -cp . Testfalsetruetrue
六、集合操作
常用集合
通过下面的代码,可以了解常用集合的创建方式
// 定义整型 List,其元素以线性方式存储,可以存放重复对象。val x = List(1,2,3,4)
// 定义 Set,其对象不按特定的方式排序,并且没有重复对象。val x = Set(1,3,5,7)
// 定义 Map,把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。val x = Map("one" -> 1, "two" -> 2, "three" -> 3)
// 创建两个不同类型元素的元组,元组是不同类型的值的集合val x = (10, "Bigdata")
// 定义 Option,表示有可能包含值的容器,也可能不包含值。val x:Option[Int] = Some(5)
集合函数
工作中操作 Scala 集合时,一般会进行两类操作:转换操作(transformation )和行动操作(action)。第一种操作类型将集合转换为另一个集合,第二种操作类型返回某些类型的值。
1)最大值和最小值
先从行动函数开始。在序列中查找最大或最小值是一个极常见的需求。
先看一下简单的例子。
val numbers = Seq(11, 2, 5, 1, 6, 3, 9) numbers.max //11 numbers.min //1
对于这种简单数据集合,Scala的函数式特性显露无疑,如此简单的取到了最大值和最小值。再来看一个数据集合复杂的例子。
case class Book(title: String, pages: Int) val books = Seq( Book("Future of Scala developers", 85), Book("Parallel algorithms", 240), Book("Object Oriented Programming", 130), Book("Mobile Development", 495)) //下面代码返回Book(Mobile Development,495)books.maxBy(book => book.pages) //下面代码返回Book(Future of Scala developers,85)books.minBy(book => book.pages)
minBy & maxBy方法解决了复杂数据的问题。
2)筛选-Filter
对集合进行过滤,返回满足条件的元素的新集合,比如过滤一组数据中的偶数。
val numbers = Seq(1,2,3,4,5,6,7,8,9,10) numbers.filter(n => n % 2 == 0)//上面返回Seq(2,4,6,8,10)
获取页数大于300页的书。
val books = Seq( Book("Future of Scala developers", 85), Book("Parallel algorithms", 240), Book("Object Oriented Programming", 130), Book("Mobile Development", 495))
books.filter(book => book.pages >= 300)//上面返回Seq(Book("Mobile Development", 495))
还有一个与 filter类似的方法是 filterNot,也就是筛选出不满足条件的对象。
3)Flatten
它的作用是将多个集合展开,组成一个新的集合,举例说明。
val abcd = Seq('a', 'b', 'c', 'd')val efgj = Seq('e', 'f', 'g', 'h')val ijkl = Seq('i', 'j', 'k', 'l')val mnop = Seq('m', 'n', 'o', 'p')val qrst = Seq('q', 'r', 's', 't')val uvwx = Seq('u', 'v', 'w', 'x')val yz = Seq('y', 'z') val alphabet = Seq(abcd, efgj, ijkl, mnop, qrst, uvwx, yz)
alphabet.flatten
执行后返回下面的集合:
List('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z')
4)集合运算函数
集合运算即差集、交集和并集操作。
val num1 = Seq(1, 2, 3, 4, 5, 6)val num2 = Seq(4, 5, 6, 7, 8, 9) //返回List(1, 2, 3)num1.diff(num2) //返回List(4, 5, 6)num1.intersect(num2) //返回List(1, 2, 3, 4, 5, 6, 4, 5, 6, 7, 8, 9)num1.union(num2)
//合并后再去重,返回List(1, 2, 3, 4, 5, 6, 7, 8, 9)num1.union(num2).distinct
5)map函数
map 函数的逻辑是遍历集合并对每个元素调用传入的函数进行处理。
val numbers = Seq(1,2,3,4,5,6) //返回List(2, 4, 6, 8, 10, 12)numbers.map(n => n * 2) val chars = Seq('a', 'b', 'c', 'd') //返回List(A, B, C, D)chars.map(ch => ch.toUpper)
6)flatMap
它将map & flatten组合起来,请看下面的操作。
val abcd = Seq('a', 'b', 'c', 'd') //List(A, a, B, b, C, c, D, d)abcd.flatMap(ch => List(ch.toUpper, ch))
从结果可以看出来是先做的map,然后做的flatten
7)forall & exists
forall是对整个集合做判断,当集合中的所有元素都满足条件时,返回true。而exists则是只要有一个元素满足条件就返回true。
val numbers = Seq(3, 7, 2, 9, 6, 5, 1, 4, 2) //返回turenumbers.forall(n => n < 10) //返回falsenumbers.forall(n => n > 5)
//返回truenumbers.exists(n => n > 5)
七、读取数据源
读取外部数据源是开发中很常见的需求,如在程序中读取外部配置文件并解析,获取相应的执行参数。这里只针对scala如何通过Source类读取数据源进行简单介绍。
-
import scala.io.Source
-
-
object ReadFile {
//读取ClasPath下的配置文件 val file = Source.fromInputStream(this.getClass.getClassLoader.getResourceAsStream("app.conf"))
//一行一行读取文件,getLines()表示读取文件所有行 def readLine: Unit ={ for(line <- file.getLines()){ println(line) } } //读取网络上的内容 def readNetwork: Unit ={ val file = Source.fromURL("http://www.baidu.com") for(line <- file.getLines()){ println(line) } }
//读取给定的字符串-多用于调试 val source = Source.fromString("test") }
八、隐式转换
隐式转换是Scala中一种非常有特色的功能,是其他编程语言所不具有的,可以实现将某种类型的对象转换为另一种类型的对象。数据分析工作中,最常使用到的就是java和scala集合之间的互相转换,转换以后就可以调用另一种类型的方法。scala提供了scala.collection.JavaConversions类,只要引入此类中相应的隐式转化方法,在程序中就可以用相应的类型来代替要求的类型。
如通过以下转换,scala.collection.mutable.Buffer自动转换成了java.util.List。
import scala.collection.JavaConversions.bufferAsJavaListscala.collection.mutable.Buffer => java.util.List
同样,java.util.List也可以转换成scala.collection.mutable.Buffer。
import scala.collection.JavaConversions.asScalaBufferjava.util.List => scala.collection.mutable.Buffer
所有可能的转换汇总如下,双向箭头表示可互相转换,单箭头则表示只有左边可转换到右边。
import scala.collection.JavaConversions._
scala.collection.Iterable <=> java.lang.Iterablescala.collection.Iterable <=> java.util.Collectionscala.collection.Iterator <=> java.util.{ Iterator, Enumeration }scala.collection.mutable.Buffer <=> java.util.Listscala.collection.mutable.Set <=> java.util.Setscala.collection.mutable.Map <=> java.util.{ Map, Dictionary }scala.collection.concurrent.Map <=> java.util.concurrent.ConcurrentMap
scala.collection.Seq => java.util.Listscala.collection.mutable.Seq => java.util.Listscala.collection.Set => java.util.Setscala.collection.Map => java.util.Mapjava.util.Properties => scala.collection.mutable.Map[String, String]
隐式参数
所谓隐式参数,指的是在函数或者方法中,定义使用implicit修饰的参数。当调用该函数或方法时,scala会尝试在变量作用域中找到一个与指定类型相匹配的使用implicit修饰的对象,即隐式值,注入到函数参数中函数体使用。示例如下:
class SayHello{ def write(content:String) = println(content)}implicit val sayHello=new SayHello
def saySomething(name:String)(implicit sayHello:SayHello){ sayHello.write("Hello," + name)}
saySomething("Scala")
//打印 Hello,Scala
值得注意的是,隐式参数是根据类型匹配的,因此作用域中不能同时出现两个相同类型的隐式变量,否则编译时会抛出隐式变量模糊的异常。
九、正则匹配
正则的概念、作用和规则都在上一篇《大数据分析工程师入门--1.Java基础》中已经完整的讲述了,这里将通过示例来讲解下在scala中正则相关代码怎么写:
定义
val TEST_REGEX = "home\\*(classification|foundation|my_tv)\\*[0-9-]{0,2}([a-z_]*)".r
使用
//path是用来匹配的字符串TEST_REGEX findFirstMatchIn path match { case Some(p) => { //获取TEST_REGEX中的第一个括号里正则片段匹配到的内容 launcher_area_code = p.group(1) //获取TEST_REGEX中的第二个括号里正则片段匹配到的内容 launcher_location_code = p.group(2) }}
十、异常处理
学习过Java的同学对异常一定并不陌生,异常通常是程序执行过程中遇到问题时,用来打断程序执行的重要方式。关于异常处理的注意事项,在上一讲《大数据分析工程师入门--1.Java基础》里已经讲过了,这里就不再赘述了。我们重点来讲下scala和java在异常这个特性的设计上的不同。
1. 捕获异常的方式略有不同
java中是通过多个catch子句来捕获不同类型的异常,而在scala中是通过一个catch子句,加上模式匹配的类型匹配方式来捕获不同类型的异常。如下图所示:

2.scala没有checked异常
在java中,非运行时异常在编译期是会被强制检查的,要么写try...catch...处理,要么使用throws关键字,将异常抛给调用者处理。而在scala中,更推崇通过使用函数式结构和强类型来减少对异常及其处理的依赖。因此scala不支持检查型异常(checked exception)。
当使用scala调用java类库时,scala会把java代码中声明的异常,转换为非检查型异常。
3.scala在throw异常时是有返回值的
在scala的设计中,所有表达式都是有返回值的。那么,自然throw表达式也不例外,throw表达式的返回值为Nothing。由于Nothing类型是所有类型的子类型,因此throw表达式可以出现在任意位置,而不会影响到类型的推断。
十一、类型层级
在scala中,所有的值都是有类型的,包括数值型值和函数,比java更加彻底地贯彻了万物皆对象的理念。因此,scala有一套自己的类型层级,如下图所示:
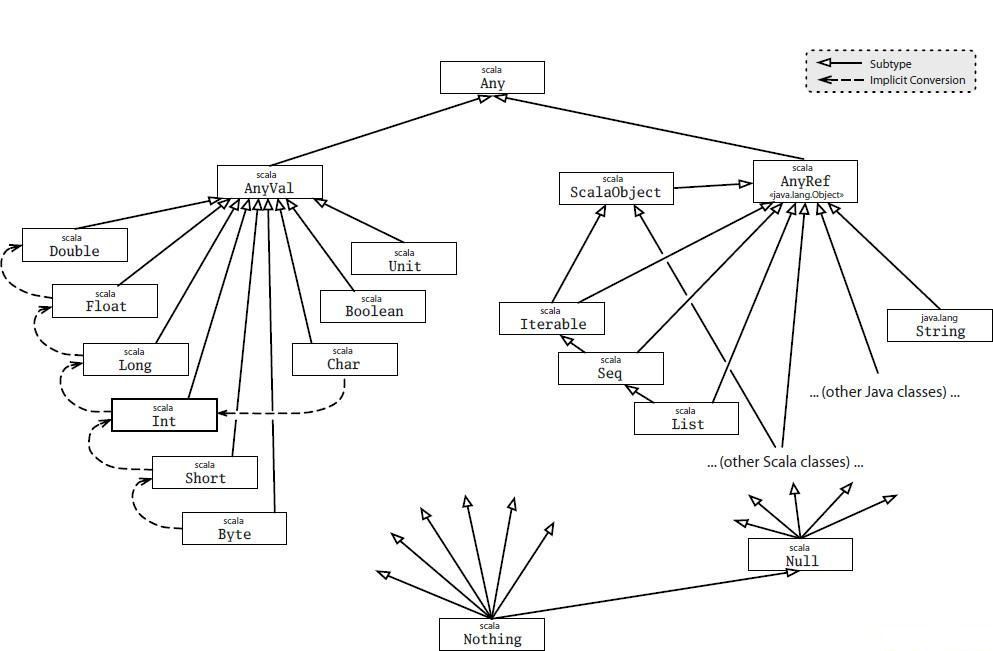
(图片来自于网络)
如图中所示,scala的顶级类是Any,下面包含两个子类,AnyVal和AnyRef,其中AnyVal是所有值类型的父类,其中包含一个特殊的值Unit;而AnyRef是所有引用类型的父类,所有java类型和非值类型的scala类型都是它的子类。其中,有两个比较特殊的底层子类型,一个是Null,它是所有引用类型的子类型,可以赋给任何引用类型变量;另一个是Nothing,它是所有类型的子类,因此既可以赋给引用类型变量,也可以赋给值类型变量。
十二、基本数值类型转换
在scala中,通常会自动进行java和scala之间基本数值类型的转换,并不需要单独去处理。所以,在我们的感受中,通常java和scala的基本数据类型是可以无缝衔接的。但是,有一种情况是例外的,那就是当你引用第三方的java类库,而在它的代码中接收参数是Object类型,之后又对传入对象的实际数值类型做判断时,通常会失败报错。
原因很简单,第三方java类库,使用java语言编写,它只认得java的类型。当接收参数为Object类型时,scala默认不会转换成java的数值类型,这样当判断对象的具体数值类型时,会出现不认识scala对象类型的异常。
解决方案也很简单,只需要在传入第三方类库方法前,手动包装成java类型即可。以下是代码示例,本例演示了DBUtils类库传入scala类型时的处理,只展示了部分代码:
//由于java和scala中的类型短名称重名,为避免歧义,进行了重命名import java.lang.{Long => JLong, Double => JDouble}//conn为数据库连接,sql为要执行的SQL语句queryRunner.update(conn, sql, new JLong(1L), new JDouble(2.2))
总结
本文结合实际工作经验,把scala中最常用到的一些知识点进行了梳理,要想成为一名初级大数据工程师,这些知识是必须要掌握的。

大数据俱乐部、数据与智能: https://blog.csdn.net/weixin_39032019/article/details/117997723
整理不易,评论、点赞、收藏是对我最大的支持!!!
文章来源: notomato.blog.csdn.net,作者:kissme丶,版权归原作者所有,如需转载,请联系作者。
原文链接:notomato.blog.csdn.net/article/details/118056290

- 点赞
- 收藏
- 关注作者
评论(0)