临近秋招,老油条带你一键爬取阿里、百度、字节大厂面试真题!!!

前言
本文爬虫源码已由 GitHub https://github.com/2335119327/PythonSpider 已经收录(内涵更多本博文没有的爬虫,有兴趣的小伙伴可以看看),之后会持续更新,欢迎Star。
博主 常年游荡于牛客面经区,总结了字节、阿里、百度、腾讯、美团等等大厂的高频考题,但是今天,我教大家如何进行面经爬取,如果能帮到各位小伙伴,麻烦一件三连多多支持,感激不敬!!!
本次爬取以Java面经为例,学会的小伙伴可以按照规律爬取牛客任意面经


教学
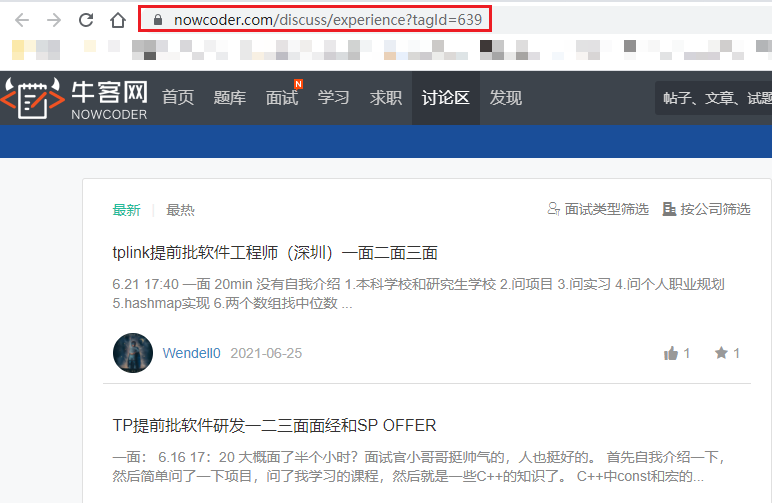
进入Java面经区,打开控制台刷新请求
可以发现,发送浏览器中的URL,得到的响应内容是没有面经的,那么面经的数据从何而来???不要着急,那么多请求我们接着看!
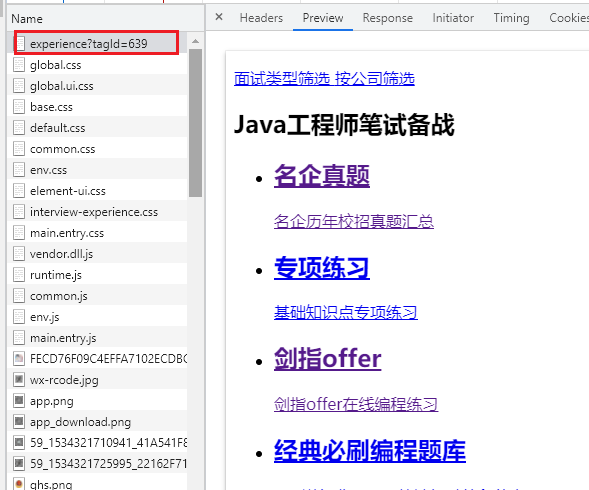
往下滑,可以看见带json的请求,经验告诉我就是这个请求
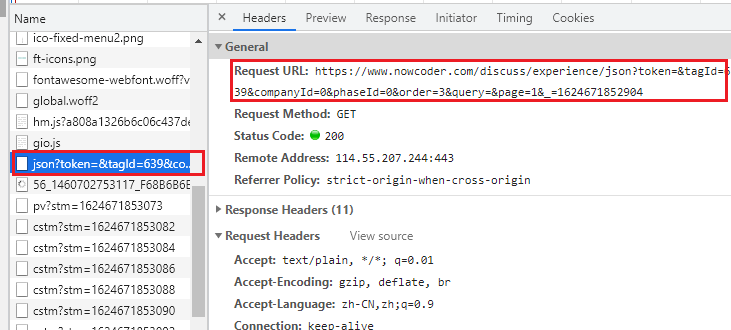
复制该URL,我们去浏览器请求该URL,可发现我们得到了面经的数据

但是,面经是JSON格式,我们可以复制到在线json解析工具去查看,如下

可以看到data下的discussPosts下保存着所有的帖子即面经信息
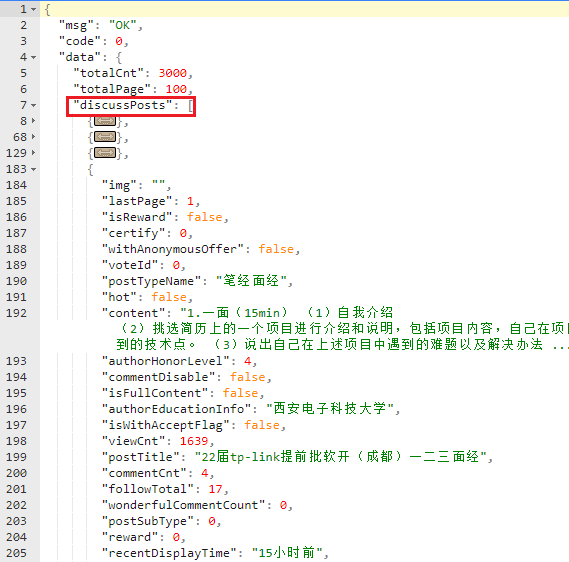
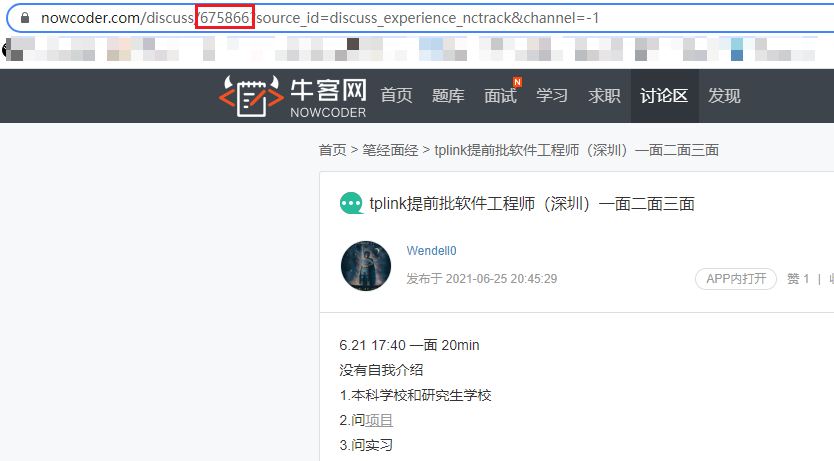
但是这个json不像我以前见到的,这个json串没有直接保存帖子详情页的URL,但是我们可以提供过访问路径发现规律

可以看见访问路径有个675866,就是对应json串中的postId,而后面的参数是可以省略的
小技巧
想必单页面经是肯定不能满足各位小伙伴的,那么如果进行多页爬取呢,不要着急,我来为大家总结规律,也希望小伙伴们能一键三连哦!!!

一样的套路,如下图是C++区域的面经JSON字符串,应该不用我多教了吧

完整代码
麻烦各位小伙伴关注公众号,后台回复【爬取大厂面试题】即可获得完整源码😁😁😁
后续公众号也会只需发布优质博文,不容爬虫小伙伴们错过哦!🤣

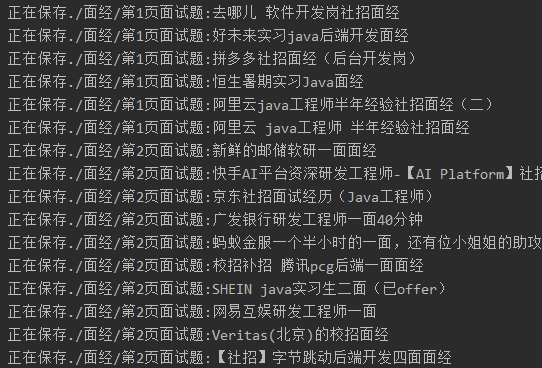
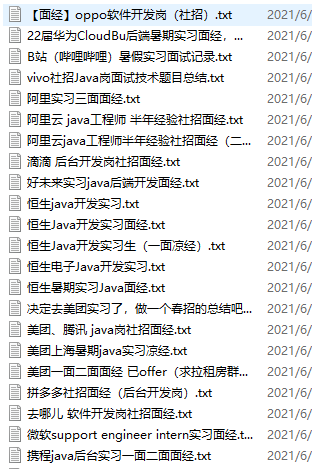
结果展示

最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以==一键三连哦!==,感谢支持,我们下次再见~~~
本文爬虫源码已由 GitHub https://github.com/2335119327/PythonSpider 已经收录(内涵更多本博文没有的爬虫,有兴趣的小伙伴可以看看),之后会持续更新,欢迎Star。

- 点赞
- 收藏
- 关注作者
评论(0)