使用 Python、SQLite 和 SQLAlchemy 进行数据管理1 |【生长吧!Python!】

目录
所有程序都以一种或另一种形式处理数据,并且许多程序需要能够从一次调用到下一次调用保存和检索该数据。Python、SQLite和SQLAlchemy为您的程序提供数据库功能,允许您将数据存储在单个文件中,而无需数据库服务器。
您可以使用多种格式的平面文件获得类似的结果,包括 CSV、JSON、XML,甚至自定义格式。平面文件通常是人类可读的文本文件——尽管它们也可以是二进制数据——具有可由计算机程序解析的结构。下面,您将探索使用 SQL 数据库和平面文件进行数据存储和操作,并学习如何确定哪种方法适合您的程序。
在本教程中,您将学习如何使用:
- 用于数据存储的平面文件
- 用于改进对持久数据的访问的SQL
- 用于数据存储的SQLite
- SQLAlchemy将数据作为 Python 对象处理
使用平面文件进行数据存储
甲平面文件是包含数据没有内部层次结构,并且通常没有对外部文件的引用的文件。平面文件包含人类可读的字符,对于创建和读取数据非常有用。因为它们不必使用固定的字段宽度,所以平面文件通常使用其他结构来使程序能够解析文本。
例如,逗号分隔值 (CSV)文件是纯文本行,其中逗号字符分隔数据元素。每行文本代表一行数据,每个逗号分隔值是该行中的一个字段。逗号分隔符表示数据值之间的边界。
Python 擅长读取和保存到文件。能够使用 Python 读取数据文件允许您在以后重新运行应用程序时将其恢复到有用的状态。能够将数据保存在文件中允许您在用户和应用程序运行的站点之间共享来自程序的信息。
在程序可以读取数据文件之前,它必须能够理解数据。通常,这意味着数据文件需要具有某种结构,应用程序可以使用该结构来读取和解析文件中的文本。
下面是一个名为 的 CSV 文件author_book_publisher.csv,由本教程中的第一个示例程序使用:
first_name,last_name,title,publisher
Isaac,Asimov,Foundation,Random House
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Tom,Clancy,The Hunt For Red October,Berkley
Tom,Clancy,Patriot Games,Simon & Schuster
Stephen,King,It,Random House
Stephen,King,It,Penguin Random House
Stephen,King,Dead Zone,Random House
Stephen,King,The Shining,Penguin Random House
John,Le Carre,"Tinker, Tailor, Soldier, Spy: A George Smiley Novel",Berkley
Alex,Michaelides,The Silent Patient,Simon & Schuster
Carol,Shaben,Into The Abyss,Simon & Schuster第一行提供了一个以逗号分隔的字段列表,这些字段是其余行中数据的列名。其余行包含数据,每行代表一条记录。
注意:虽然作者、书籍和出版商都是真实的,但书籍和出版商之间的关系是虚构的,并且是为了本教程的目的而创建的。
接下来,您将了解使用上述 CSV 等平面文件处理数据的一些优点和缺点。
平面文件的优点
处理平面文件中的数据易于管理且易于实施。以人类可读的格式保存数据不仅有助于使用文本编辑器创建数据文件,而且有助于检查数据并查找任何不一致或问题。
许多应用程序可以导出由文件生成的数据的平面文件版本。例如,Excel可以从电子表格导入或导出 CSV 文件。如果您想共享数据,平面文件还具有自包含和可传输的优点。
几乎每种编程语言都有工具和库,可以更轻松地处理 CSV 文件。Python 具有内置csv模块和强大的Pandas模块,这使得处理 CSV 文件成为一种有效的解决方案。
平面文件的缺点
随着数据变大,使用平面文件的优势开始减弱。大文件仍然是人类可读的,但编辑它们以创建数据或查找问题变得更加困难。如果您的应用程序将更改文件中的数据,那么一种解决方案是将整个文件读入内存,进行更改,然后将数据写入另一个文件。
使用平面文件的另一个问题是,您需要在文件语法中明确创建和维护数据部分与应用程序之间的任何关系。此外,您需要在应用程序中生成代码以使用这些关系。
最后一个复杂问题是,您想要与之共享数据文件的人还需要了解您在数据中创建的结构和关系并对其采取行动。要访问信息,这些用户不仅需要了解数据的结构,还需要了解访问数据所需的编程工具。
平面文件示例
示例程序examples/example_1/main.py使用该author_book_publisher.csv文件来获取其中的数据和关系。此 CSV 文件维护着作者列表、他们已出版的书籍以及每本书的出版商。
注意:示例中使用的数据文件在project/data目录中可用。在project/build_data生成数据的目录中还有一个程序文件。如果您更改数据并希望恢复到已知状态,则该应用程序很有用。
要访问本节和整个教程中使用的数据文件,请单击以下链接:
下载示例代码: 单击此处获取您将用于了解本教程中 SQLite 和 SQLAlchemy 数据管理的代码。
上面显示的 CSV 文件是一个非常小的数据文件,仅包含少数作者、书籍和出版商。您还应该注意有关数据的一些事情:
-
作者斯蒂芬·金和汤姆·克兰西不止一次出现,因为他们出版的多本书都出现在数据中。
-
作者斯蒂芬金和赛珍珠的同一本书由多个出版商出版。
这些重复的数据字段在数据的其他部分之间创建关系。一位作者可以写多本书,一位出版商可以与多位作者合作。作者和出版商与个别书籍共享关系。
author_book_publisher.csv文件中的关系由在数据文件的不同行中多次出现的字段表示。由于这种数据冗余,数据代表的不仅仅是一个二维表。当您使用该文件创建 SQLite 数据库文件时,您将看到更多内容。
示例程序examples/example_1/main.py使用嵌入在author_book_publisher.csv文件中的关系来生成一些数据。它首先列出了作者列表和每个人所写的书籍数量。然后,它会显示一个出版商列表以及每个人都出版过书籍的作者数量。
它还使用该treelib模块来显示作者、书籍和出版商的树状层次结构。
最后,它将一本新书添加到数据中,并在新书到位的情况下重新显示树层次结构。这是main()该程序的入口函数:
def main():
"""The main entry point of the program"""
# Get the resources for the program
with resources.path(
"project.data", "author_book_publisher.csv"
) as filepath:
data = get_data(filepath)
# Get the number of books printed by each publisher
books_by_publisher = get_books_by_publisher(data, ascending=False)
for publisher, total_books in books_by_publisher.items():
print(f"Publisher: {publisher}, total books: {total_books}")
print()
# Get the number of authors each publisher publishes
authors_by_publisher = get_authors_by_publisher(data, ascending=False)
for publisher, total_authors in authors_by_publisher.items():
print(f"Publisher: {publisher}, total authors: {total_authors}")
print()
# Output hierarchical authors data
output_author_hierarchy(data)
# Add a new book to the data structure
data = add_new_book(
data,
author_name="Stephen King",
book_title="The Stand",
publisher_name="Random House",
)
# Output the updated hierarchical authors data
output_author_hierarchy(data)上面的 Python 代码执行以下步骤:
- 第 4 到 7
author_book_publisher.csv行将文件读入 pandas DataFrame。 - 第 10 到 13 行打印每个出版商出版的书籍数量。
- 第 16 到 19 行打印了与每个出版商相关联的作者数量。
- 第 22行将图书数据输出为按作者排序的层次结构。
- 第 25 到 30行将一本新书添加到内存结构中。
- 第 33行将图书数据输出为按作者排序的层次结构,包括新添加的图书。
运行此程序会生成以下输出:
$ python main.py
Publisher: Simon & Schuster, total books: 4
Publisher: Random House, total books: 4
Publisher: Penguin Random House, total books: 2
Publisher: Berkley, total books: 2
Publisher: Simon & Schuster, total authors: 4
Publisher: Random House, total authors: 3
Publisher: Berkley, total authors: 2
Publisher: Penguin Random House, total authors: 1
Authors
├── Alex Michaelides
│ └── The Silent Patient
│ └── Simon & Schuster
├── Carol Shaben
│ └── Into The Abyss
│ └── Simon & Schuster
├── Isaac Asimov
│ └── Foundation
│ └── Random House
├── John Le Carre
│ └── Tinker, Tailor, Soldier, Spy: A George Smiley Novel
│ └── Berkley
├── Pearl Buck
│ └── The Good Earth
│ ├── Random House
│ └── Simon & Schuster
├── Stephen King
│ ├── Dead Zone
│ │ └── Random House
│ ├── It
│ │ ├── Penguin Random House
│ │ └── Random House
│ └── The Shining
│ └── Penguin Random House
└── Tom Clancy
├── Patriot Games
│ └── Simon & Schuster
└── The Hunt For Red October
└── Berkley上面的作者层次结构在输出中出现了两次,其中添加了史蒂芬金的The Stand,由兰登书屋出版。上面的实际输出已经过编辑,仅显示第一个层次结构输出以节省空间。
main()调用其他函数来执行大部分工作。它调用的第一个函数是get_data():
def get_data(filepath):
"""Get book data from the csv file"""
return pd.read_csv(filepath)此函数接收 CSV 文件的文件路径,并使用 pandas 将其读入pandas DataFrame,然后将其传回给调用者。这个函数的返回值成为传递给组成程序的其他函数的数据结构。
get_books_by_publisher()计算每个出版商出版的书籍数量。生成的熊猫系列使用熊猫GroupBy功能按发布者分组,然后根据标志进行排序ascending:
def get_books_by_publisher(data, ascending=True):
"""Return the number of books by each publisher as a pandas series"""
return data.groupby("publisher").size().sort_values(ascending=ascending)get_authors_by_publisher() 与之前的功能基本相同,但对于作者:
def get_authors_by_publisher(data, ascending=True):
"""Returns the number of authors by each publisher as a pandas series"""
return (
data.assign(name=data.first_name.str.cat(data.last_name, sep=" "))
.groupby("publisher")
.nunique()
.loc[:, "name"]
.sort_values(ascending=ascending)
)add_new_book()在 Pandas DataFrame 中创建一本新书。该代码会检查作者、书籍或出版商是否已经存在。如果没有,那么它会创建一本新书并将其附加到 Pandas DataFrame:
def add_new_book(data, author_name, book_title, publisher_name):
"""Adds a new book to the system"""
# Does the book exist?
first_name, _, last_name = author_name.partition(" ")
if any(
(data.first_name == first_name)
& (data.last_name == last_name)
& (data.title == book_title)
& (data.publisher == publisher_name)
):
return data
# Add the new book
return data.append(
{
"first_name": first_name,
"last_name": last_name,
"title": book_title,
"publisher": publisher_name,
},
ignore_index=True,
)output_author_hierarchy()使用嵌套for循环遍历数据结构的级别。然后它使用该treelib模块输出作者、他们出版的书籍以及出版这些书籍的出版商的分层列表:
def output_author_hierarchy(data):
"""Output the data as a hierarchy list of authors"""
authors = data.assign(
name=data.first_name.str.cat(data.last_name, sep=" ")
)
authors_tree = Tree()
authors_tree.create_node("Authors", "authors")
for author, books in authors.groupby("name"):
authors_tree.create_node(author, author, parent="authors")
for book, publishers in books.groupby("title")["publisher"]:
book_id = f"{author}:{book}"
authors_tree.create_node(book, book_id, parent=author)
for publisher in publishers:
authors_tree.create_node(publisher, parent=book_id)
# Output the hierarchical authors data
authors_tree.show()此应用程序运行良好,并说明了 Pandas 模块可为您提供的强大功能。该模块提供了用于读取 CSV 文件和与数据交互的出色功能。
让我们继续使用 Python(作者和出版数据的 SQLite 数据库版本)创建一个功能相同的程序,并使用 SQLAlchemy 与该数据进行交互。
使用 SQLite 持久化数据
正如您之前看到的,author_book_publisher.csv文件中有冗余数据。例如,关于赛珍珠的《大地》的所有信息都列出了两次,因为这本书是由两个不同的出版商出版的。
想象一下,如果此数据文件包含更多相关数据,例如作者的地址和电话号码、出版日期和书籍的 ISBN,或者地址、电话号码,以及出版商的年收入。将为每个根数据项(如作者、书籍或出版商)复制此数据。
可以通过这种方式创建数据,但会非常笨拙。想想保持这个数据文件最新的问题。如果斯蒂芬·金想改名怎么办?您必须更新包含他姓名的多个记录,并确保没有错别字。
比数据重复更糟糕的是向数据添加其他关系的复杂性。如果您决定为作者添加电话号码,而他们有家庭电话号码、工作电话号码、手机号码或更多电话号码,该怎么办?您想要为任何根项目添加的每个新关系都会将记录数乘以该新关系中的项目数。
这个问题是数据库系统中存在关系的原因之一。数据库工程中的一个重要主题是数据库规范化,即分解数据以减少冗余和增加完整性的过程。当使用新类型的数据扩展数据库结构时,事先对其进行规范化可使对现有结构的更改最小化。
SQLite 数据库在 Python 中可用,根据SQLite 主页,它的使用量超过所有其他数据库系统的总和。它提供了一个功能齐全的关系数据库管理系统 (RDBMS),该系统使用单个文件来维护所有数据库功能。
它还具有不需要单独的数据库服务器即可运行的优点。数据库文件格式是跨平台的,任何支持 SQLite 的编程语言都可以访问。
所有这些都是有趣的信息,但它与使用平面文件进行数据存储有何关联?你会在下面找到!
创建数据库结构
将author_book_publisher.csv数据放入 SQLite 数据库的蛮力方法是创建一个与 CSV 文件结构匹配的表。这样做会忽略大量 SQLite 的功能。
关系数据库提供了一种将结构化数据存储在表中并在这些表之间建立关系的方法。他们通常使用结构化查询语言 (SQL)作为与数据交互的主要方式。这对 RDBMS 提供的内容过于简化,但对于本教程的目的来说已经足够了。
SQLite 数据库支持使用 SQL 与数据表进行交互。SQLite 数据库文件不仅包含数据,而且还具有与数据交互的标准化方式。这种支持嵌入在文件中,这意味着任何可以使用 SQLite 文件的编程语言也可以使用 SQL 来处理它。
使用 SQL 与数据库交互
SQL 是一种声明性语言,用于创建、管理和查询数据库中包含的数据。声明性语言描述的是要完成什么,而不是如何完成。稍后在创建数据库表时,您将看到 SQL 语句的示例。
使用 SQL 构建数据库
要利用 SQL 的强大功能,您需要对author_book_publisher.csv文件中的数据应用一些数据库规范化。为此,您需要将作者、书籍和出版商分开到单独的数据库表中。
从概念上讲,数据以二维表结构存储在数据库中。每个表由记录行组成,每个记录由包含数据的列或字段组成。
字段中包含的数据是预定义的类型,包括文本、整数、浮点数等。CSV 文件不同,因为所有字段都是文本,必须由程序解析才能为其分配数据类型。
表中的每条记录都定义了一个主键,以便为记录提供唯一标识符。主键类似于Python 字典中的键。数据库引擎本身通常为插入到数据库表中的每条记录生成主键作为递增的整数值。
尽管主键通常由数据库引擎自动生成,但并非必须如此。如果存储在字段中的数据在该字段中表中的所有其他数据中是唯一的,则它可以是主键。例如,包含书籍数据的表可以使用书籍的 ISBN 作为主键。
使用 SQL 创建表
以下是使用 SQL 语句在 CSV 文件中创建代表作者、书籍和出版商的三个表的方法:
CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR,
last_name VARCHAR
);
CREATE TABLE book (
book_id INTEGER NOT NULL PRIMARY KEY,
author_id INTEGER REFERENCES author,
title VARCHAR
);
CREATE TABLE publisher (
publisher_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR
);请注意,没有文件操作,没有创建变量,也没有保存它们的结构。这些语句仅描述了所需的结果:创建具有特定属性的表。数据库引擎决定如何执行此操作。
创建并使用author_book_publisher.csv文件中的作者数据填充此表后,您可以使用 SQL 语句访问它。以下语句(也称为查询)使用通配符 ( *) 获取author表中的所有数据并输出:
SELECT * FROM author;您可以使用sqlite3命令行工具与目录中的author_book_publisher.db数据库文件进行交互project/data:
$ sqlite3 author_book_publisher.db一旦 SQLite 命令行工具在数据库打开的情况下运行,您就可以输入 SQL 命令。这是上面的 SQL 命令及其输出,然后是.q退出程序的命令:
sqlite> SELECT * FROM author;
1|Isaac|Asimov
2|Pearl|Buck
3|Tom|Clancy
4|Stephen|King
5|John|Le Carre
6|Alex|Michaelides
7|Carol|Shaben
sqlite> .q请注意,每个作者在表中仅存在一次。与 CSV 文件不同,其中一些作者有多个条目,在这里,每个作者只需要一个唯一的记录。
使用 SQL 维护数据库
SQL 提供了通过插入新数据和更新或删除现有数据来处理现有数据库和表的方法。下面是将新作者插入author表中的示例 SQL 语句:
INSERT INTO author
(first_name, last_name)
VALUES ('Paul', 'Mendez');这个SQL语句插入值“ Paul”和“ Mendez”到相应的列first_name和last_name的的author表。
请注意,author_id未指定该列。因为该列是主键,所以数据库引擎生成值并将其作为语句执行的一部分插入。
更新数据库表中的记录是一个简单的过程。例如,假设斯蒂芬·金想以他的笔名理查德·巴赫曼出名。这是更新数据库记录的 SQL 语句:
UPDATE author
SET first_name = 'Richard', last_name = 'Bachman'
WHERE first_name = 'Stephen' AND last_name = 'King';SQL 语句定位'Stephen King'使用条件语句的单个记录WHERE first_name = 'Stephen' AND last_name = 'King',然后使用新值更新first_name和last_name字段。SQL 使用等号 ( =) 作为比较运算符和赋值运算符。
您还可以从数据库中删除记录。这是从author表中删除记录的示例 SQL 语句:
DELETE FROM author
WHERE first_name = 'Paul'
AND last_name = 'Mendez';此 SQL 语句从author表中删除单行,其中first_name等于'Paul'且last_name等于'Mendez'。
删除记录时要小心!您设置的条件必须尽可能具体。条件过于宽泛可能会导致删除的记录数超出您的预期。例如,如果条件仅基于行first_name = 'Paul',那么所有名字为 Paul 的作者都将从数据库中删除。
注意:为了避免意外删除记录,许多应用程序根本不允许删除。相反,该记录有另一列指示它是否在使用中。此列可能被命名active并包含一个计算结果为 True 或 False 的值,指示在查询数据库时是否应包括该记录。
例如,下面的 SQL 查询将获取 中所有活动记录的所有列some_table:
SELECT
*
FROM some_table
WHERE active = 1;
SQLite 没有Boolean 数据类型,因此该active列由一个整数表示,其值为0或1以指示记录的状态。其他数据库系统可能有也可能没有本机布尔数据类型。
完全有可能直接在代码中使用 SQL 语句在 Python 中构建数据库应用程序。这样做会将数据作为列表列表或字典列表返回到应用程序。
使用原始 SQL 是处理由查询返回到数据库的数据的一种完全可以接受的方式。但是,与其这样做,不如直接使用 SQLAlchemy 来处理数据库。
建立关系
您可能会发现数据库系统的另一个功能比数据持久性和检索更强大和有用,那就是关系。支持关系的数据库允许您将数据分解为多个表并在它们之间建立连接。
中数据author_book_publisher.csv文件表示通过复制数据的数据和关系。数据库通过将数据分成三个表author—— book、 和publisher—— 并在它们之间建立关系来处理这个问题。
将您想要的所有数据放在 CSV 文件中的一个位置后,为什么要将其分解为多个表?创建并重新组合在一起不是更多的工作吗?这在一定程度上是正确的,但是使用 SQL 分解数据并将其重新组合在一起的优势可能会赢得您的青睐!
一对多关系
一个一个一对多的关系就像是一个客户订购的物品在线。一个客户可以有多个订单,但每个订单属于一个客户。该author_book_publisher.db数据库在作者和图书的形式一到一对多的关系。每个作者可以写很多本书,但每本书都是由一个作者写的。
正如您在上面的表创建中看到的,这些独立实体的实现是将每个实体放入一个数据库表中,一个用于作者,一个用于书籍。但是这两个表之间的一对多关系是如何实现的呢?
请记住,数据库中的每个表都有一个字段被指定为该表的主键。上面的每个表都有一个使用以下模式命名的主键字段:<table name>_id。
book上面显示的表包含author_id引用该author表的字段 。该author_id字段在作者和书籍之间建立了一对多的关系,如下所示:

上图是一个使用JetBrains DataGrip应用程序创建的简单实体关系图 (ERD),显示了表格和带有各自主键和数据字段的框。两个图形项添加有关关系的信息:authorbook
-
黄色和蓝色小键图标分别表示表的主键和外键。
-
连接
book到的箭头author表示基于表中的author_id外键的book表之间的关系。
当您向book表中添加新书时,数据包括表中author_id现有作者的值author。通过这种方式,一个作者写的所有书籍都有一个回溯到那个唯一作者的查找关系。
现在你有单独的作者和书籍表,你如何使用它们之间的关系?SQL 支持所谓的JOIN操作,您可以使用它来告诉数据库如何连接两个或多个表。
下面的 SQL 查询使用 SQLite 命令行应用程序将author和book表连接在一起:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> b.title AS book_title
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Foundation
Pearl Buck|The Good Earth
Tom Clancy|The Hunt For Red October
Tom Clancy|Patriot Games
Stephen King|It
Stephen King|Dead Zone
Stephen King|The Shining
John Le Carre|Tinker, Tailor, Soldier, Spy: A George Smiley Novel
Alex Michaelides|The Silent Patient
Carol Shaben|Into The Abyss上面的 SQL 查询通过使用两者之间建立的关系连接表来从 author 和 book 表收集信息。SQL 字符串连接将作者的全名分配给 alias author_name。查询收集的数据按last_name字段升序排序。
SQL 语句中有一些需要注意的地方。首先,作者在单列中按全名显示,并按姓氏排序。此外,由于一对多关系,作者多次出现在输出中。对于他们在数据库中编写的每本书,作者的姓名都是重复的。
通过为作者和书籍创建单独的表并建立它们之间的关系,您减少了数据中的冗余。现在,您只需在一个地方编辑作者的数据,该更改就会出现在访问数据的任何 SQL 查询中。
多对多关系
author_book_publisher.db数据库中存在作者和出版商之间以及书籍和出版商之间的多对多关系。一个作者可以与多个出版商合作,一个出版商可以与多个作者合作。同样,一本书可以由多个出版商出版,一个出版商可以出版多本书。
在数据库中处理这种情况比一对多关系更复杂,因为这种关系是双向的。多对多关系是由作为两个相关表之间桥梁的关联表创建的。
关联表至少包含两个外键字段,分别是两个关联表的主键。此 SQL 语句创建与author和publisher表相关的关联表:
CREATE TABLE author_publisher (
author_id INTEGER REFERENCES author,
publisher_id INTEGER REFERENCES publisher
);SQL语句创建一个新author_publisher表引用现有的主键author和publisher表。该author_publisher表是建立作者和出版商之间关系的关联表。
因为关系是在两个主键之间,所以不需要为关联表本身创建主键。两个相关键的组合为一行数据创建了一个唯一标识符。
和以前一样,您使用JOIN关键字将两个表连接在一起。将author表连接到publisher表是一个两步过程:
JOIN在author用表author_publisher的表。JOIN在author_publisher用表publisher的表。
该author_publisher关联表提供了通过该大桥JOIN的两个表连接。这是一个示例 SQL 查询,返回作者和出版书籍的出版商列表:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> p.name AS publisher_name
...> FROM author a
...> JOIN author_publisher ap ON ap.author_id = a.author_id
...> JOIN publisher p ON p.publisher_id = ap.publisher_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Random House
Pearl Buck|Random House
Pearl Buck|Simon & Schuster
Tom Clancy|Berkley
Tom Clancy|Simon & Schuster
Stephen King|Random House
Stephen King|Penguin Random House
John Le Carre|Berkley
Alex Michaelides|Simon & Schuster
Carol Shaben|Simon & Schuster上述语句执行以下操作:
-
第 1 行开始一条
SELECT语句以从数据库中获取数据。 -
第 2 行
author使用表的a别名从表中选择名字和姓氏,并使用author空格字符将它们连接在一起。 -
第 3 行选择别名为 的发布者名称
publisher_name。 -
第 4 行使用该
author表作为检索数据的第一个源并将其分配给别名a。 -
第 5 行是上面概述的将
author表连接到表的过程的第一步publisher。它使用别名ap的author_publisher关联表,并且执行JOIN操作以将连接ap.author_id外键参照a.author_id在主键author表。 -
第 6 行是上述两步过程中的第二步。它使用别名
p的publisher表,并执行一个JOIN操作,以涉及的ap.publisher_id外键参照p.publisher_id在主键publisher表。 -
第 7 行按作者的姓氏按字母升序对数据进行排序,并结束 SQL 查询。
-
第 8 到 17 行是 SQL 查询的输出。
请注意,源author和publisher表中的数据是规范化的,没有数据重复。然而,返回的结果在回答 SQL 查询所需的地方有重复的数据。
上面的 SQL 查询演示了如何使用 SQLJOIN关键字来使用关系,但结果数据是author_book_publisher.csvCSV 数据的部分重新创建。完成创建数据库以分离数据的工作有什么好处?
这是另一个 SQL 查询,用于展示 SQL 和数据库引擎的强大功能:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> COUNT(b.title) AS total_books
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> GROUP BY author_name
...> ORDER BY total_books DESC, a.last_name ASC;
Stephen King|3
Tom Clancy|2
Isaac Asimov|1
Pearl Buck|1
John Le Carre|1
Alex Michaelides|1
Carol Shaben|1上面的 SQL 查询返回作者列表和他们写的书数。该列表首先按书籍数量降序排序,然后按作者姓名字母顺序排序:
-
第 1 行以
SELECT关键字开始 SQL 查询。 -
第 2 行选择作者的名字和姓氏,用空格字符分隔,并创建别名
author_name。 -
第 3 行计算每个作者写的书的数量,稍后
ORDER BY子句将使用它对列表进行排序。 -
第 4 行选择
author要从中获取数据的表并创建a别名。 -
第 5 行
book通过JOINto the连接到相关表author_id并b为该book表创建别名。 -
第 6 行使用
GROUP BY关键字生成聚合的作者和书籍总数数据。GROUP BY是对每个人进行分组author_name并控制COUNT()为该作者记录哪些书籍。 -
第 7 行首先按书数降序对输出进行排序,然后按作者的姓氏字母升序排序。
-
第 8 到 14 行是 SQL 查询的输出。
在上面的示例中,您利用 SQL 执行聚合计算并将结果排序为有用的顺序。让数据库根据其内置的数据组织能力执行计算通常比在 Python 中对原始数据集执行相同类型的计算更快。SQL 提供了使用嵌入在 RDBMS 数据库中的集合论的优势。
实体关系图
的实体关系图(ERD)为数据库的数据库或一部分的实体-关系模型的视觉描绘。的author_book_publisher.dbSQLite数据库足够小,整个数据库可以由图下面示出可视化:
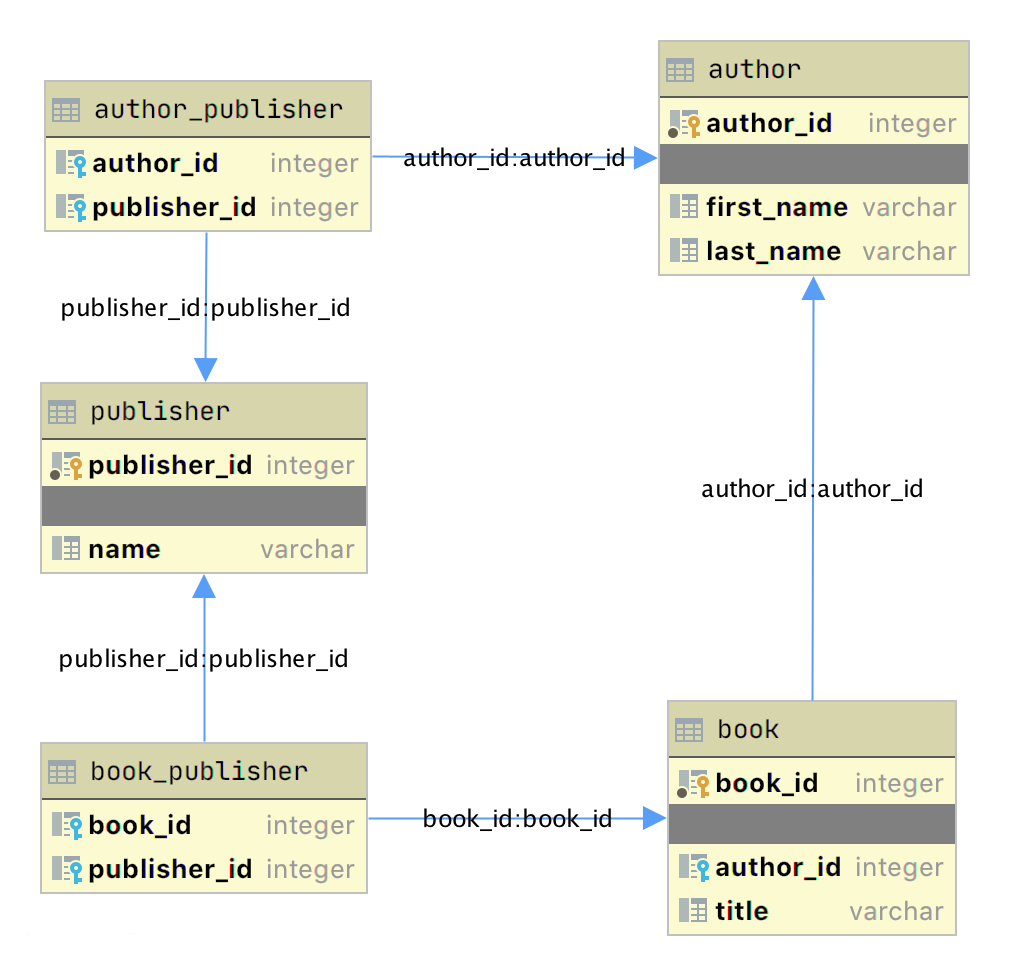
该图展示了数据库中的表结构以及它们之间的关系。每个框代表一个表并包含表中定义的字段,如果存在则首先指示主键。
箭头显示将一个表中的外键字段连接到另一个表中的字段(通常是主键)的表之间的关系。桌子上book_publisher有两个箭头,一个连接到book桌子,另一个连接到publisher桌子。箭头表示book和publisher表之间的多对多关系。该author_publisher表提供了author和之间的相同关系publisher。
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/278897

- 点赞
- 收藏
- 关注作者
评论(0)