Python 爬虫之 Scrapy

Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令 pip install Scrapy 即可。
Scrapy 比较吸引人的地方是:我们可以根据需求对其进行修改,它提供了多种类型的爬虫基类,如:BaseSpider、sitemap 爬虫等,新版本提供了对 web2.0 爬虫的支持。
1 Scrapy 介绍

1.1 组成
-
Scrapy Engine(引擎):负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯,信号、数据传递等。
-
Scheduler(调度器):负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载 Scrapy Engine(引擎) 发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理。
-
Spider(爬虫):负责处理所有 Responses,从中解析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器)。
-
Item Pipeline(管道):负责处理 Spider 中获取到的 Item,并进行后期处理,如:详细解析、过滤、存储等。
-
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件,如:设置代理、设置请求头等。
-
Spider Middlewares(Spider 中间件):一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件,如:自定义 request 请求、过滤 response 等。
总的来说就是:Spider 和 Item Pipeline 需要我们自己实现,Downloader Middlewares 和 Spider Middlewares 我们可以根据需求自定义。
1.2 流程梳理
1)Spider 将需要发送请求的 URL 交给 Scrapy Engine 交给调度器;
2)Scrapy Engine 将请求 URL 转给 Scheduler;
3)Scheduler 对请求进行排序整理等处理后返回给 Scrapy Engine;
4)Scrapy Engine 拿到请求后通过 Middlewares 发送给 Downloader;
5)Downloader 向互联网发送请求,在获取到响应后,又经过 Middlewares 发送给 Scrapy Engine。
6)Scrapy Engine 获取到响应后,返回给 Spider,Spider 处理响应,并从中解析提取数据;
7)Spider 将解析的数据经 Scrapy Engine 交给 Item Pipeline, Item Pipeline 对数据进行后期处理;
8)提取 URL 重新经 Scrapy Engine 交给Scheduler 进行下一个循环,直到无 URL 请求结束。
1.3 Scrapy 去重机制
Scrapy 提供了对 request 的去重处理,去重类 RFPDupeFilter 在 dupefilters.py 文件中,路径为:Python安装目录\Lib\site-packages\scrapy ,该类里面有个方法 request_seen 方法,源码如下:
def request_seen(self, request):
# 计算 request 的指纹
fp = self.request_fingerprint(request)
# 判断指纹是否已经存在
if fp in self.fingerprints:
# 存在
return True
# 不存在,加入到指纹集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
它在 Scheduler 接受请求的时候被调用,进而调用 request_fingerprint 方法(为 request 生成一个指纹),源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
在上面代码中我们可以看到
fp = hashlib.sha1()
...
cache[include_headers] = fp.hexdigest()
它为每一个传递过来的 URL 生成一个固定长度的唯一的哈希值。再看一下 __init__ 方法,源码如下:
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
我们可以看到里面有 self.fingerprints = set() 这段代码,就是通过 set 集合的特点(set 不允许有重复值)进行去重。
去重通过 dont_filter 参数设置,如图所示

dont_filter 为 False 开启去重,为 True 不去重。
2 实现过程
制作 Scrapy 爬虫需如下四步:
- 创建项目 :创建一个爬虫项目
- 明确目标 :明确你想要抓取的目标(编写 items.py)
- 制作爬虫 :制作爬虫开始爬取网页(编写 xxspider.py)
- 存储内容 :设计管道存储爬取内容(编写 pipelines.py)
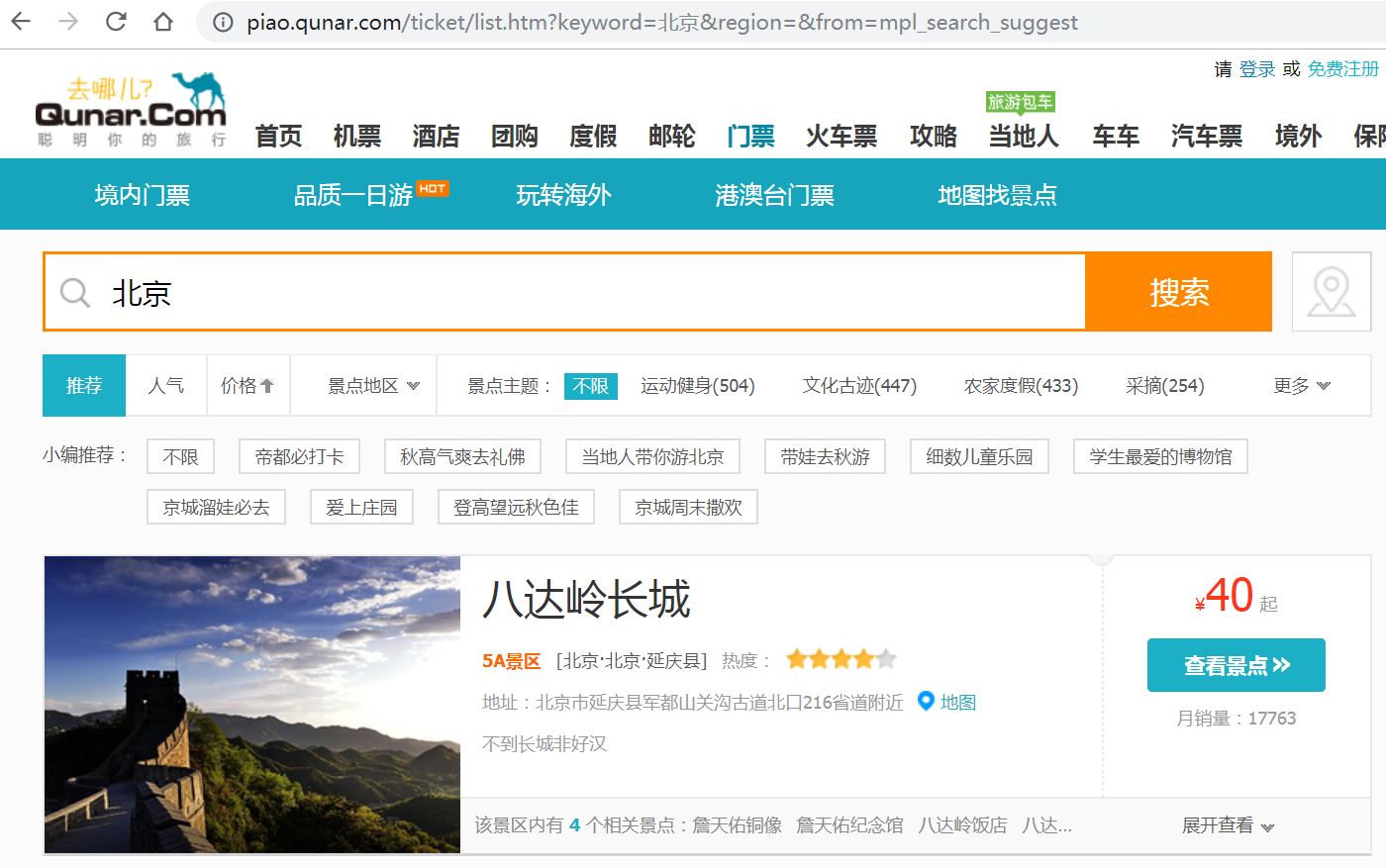
我们以爬取去哪儿网北京景区信息为例,如图所示:
2.1 创建项目
在我们需要新建项目的目录,使用终端命令 scrapy startproject 项目名 创建项目,我创建的目录结构如图所示:
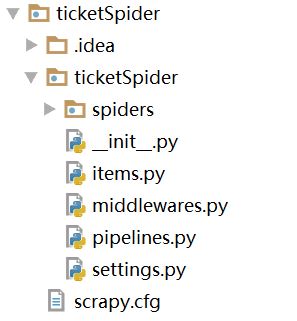
- spiders 存放爬虫的文件
- items.py 定义数据类型
- middleware.py 存放中间件
- piplines.py 存放数据的有关操作
- settings.py 配置文件
- scrapy.cfg 总的控制文件
2.2 定义 Item
Item 是保存爬取数据的容器,使用的方法和字典差不多。我们计划提取的信息包括:area(区域)、sight(景点)、level(等级)、price(价格),在 items.py 定义信息,源码如下:
import scrapy
class TicketspiderItem(scrapy.Item):
area = scrapy.Field()
sight = scrapy.Field()
level = scrapy.Field()
price = scrapy.Field()
pass
2.3 爬虫实现
在 spiders 目录下使用终端命令 scrapy genspider 文件名 要爬取的网址 创建爬虫文件,然后对其修改及编写爬取的具体实现,源码如下:
import scrapy
from ticketSpider.items import TicketspiderItem
class QunarSpider(scrapy.Spider):
name = 'qunar'
allowed_domains = ['piao.qunar.com']
start_urls = ['https://piao.qunar.com/ticket/list.htm?keyword=%E5%8C%97%E4%BA%AC®ion=&from=mpl_search_suggest']
def parse(self, response):
sight_items = response.css('#search-list .sight_item')
for sight_item in sight_items:
item = TicketspiderItem()
item['area'] = sight_item.css('::attr(data-districts)').extract_first()
item['sight'] = sight_item.css('::attr(data-sight-name)').extract_first()
item['level'] = sight_item.css('.level::text').extract_first()
item['price'] = sight_item.css('.sight_item_price em::text').extract_first()
yield item
# 翻页
next_url = response.css('.next::attr(href)').extract_first()
if next_url:
next_url = "https://piao.qunar.com" + next_url
yield scrapy.Request(
next_url,
callback=self.parse
)
简单介绍一下:
- name:爬虫名
- allowed_domains:允许爬取的域名
- atart_urls:爬取网站初始请求的 url(可定义多个)
- parse 方法:解析网页的方法
- response 参数:请求网页后返回的内容
yield
在上面的代码中我们看到有个 yield,简单说一下,yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,占用内存小。
爬虫伪装
通常需要对爬虫进行一些伪装,关于爬虫伪装可通过Python 爬虫伪装做一下简单了解,这里我们使用一个最简单的方法处理一下。
- 使用终端命令
pip install scrapy-fake-useragent安装 - 在 settings.py 文件中添加如下代码:
DOWNLOADER_MIDDLEWARES = {
# 关闭默认方法
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 开启
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
2.4 保存数据
我们将数据保存到本地的 csv 文件中,csv 具体操作可以参考:CSV 文件读写,下面看一下具体实现。
首先,在 pipelines.py 中编写实现,源码如下:
import csv
class TicketspiderPipeline(object):
def __init__(self):
self.f = open('ticker.csv', 'w', encoding='utf-8', newline='')
self.fieldnames = ['area', 'sight', 'level', 'price']
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close(self, spider):
self.f.close()
然后,将 settings.py 文件中如下代码:
ITEM_PIPELINES = {
'ticketSpider.pipelines.TicketspiderPipeline': 300,
}
放开即可。
2.5 运行
我们在 settings.py 的同级目录下创建运行文件,名字自定义,放入如下代码:
from scrapy.cmdline import execute
execute('scrapy crawl 爬虫名'.split())
这个爬虫名就是我们之前在爬虫文件中的 name 属性值,最后在 Pycharm 运行该文件即可。

- 点赞
- 收藏
- 关注作者
评论(0)