Hadoop 入门教程

【摘要】 Hadoop 入门教程
Hadoop 教程
1. 前期准备
- IDEA安装
- JDK安装
- IDEA中JDK配置
- VMware安装
- Hadoop 虚拟机
- 待补充
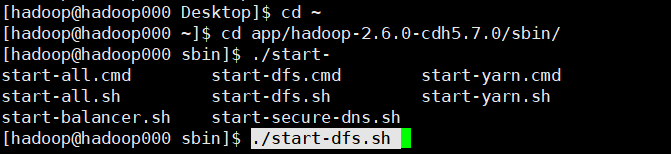
2. HDFS启动
cd app/hadoop-2.6.0-cdh5.7.0/sbin/
./start-dfs.sh
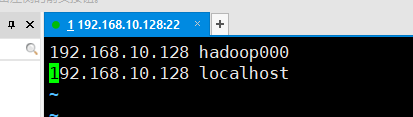
3. Hadoop启动失败解决方法
- 重新编辑本机的hosts文件
sudo vim /etc/hosts - 将
hadoop000与localhost均改为本机ip


4. Hadoop Shell命令
- 浏览器可视化文件系统
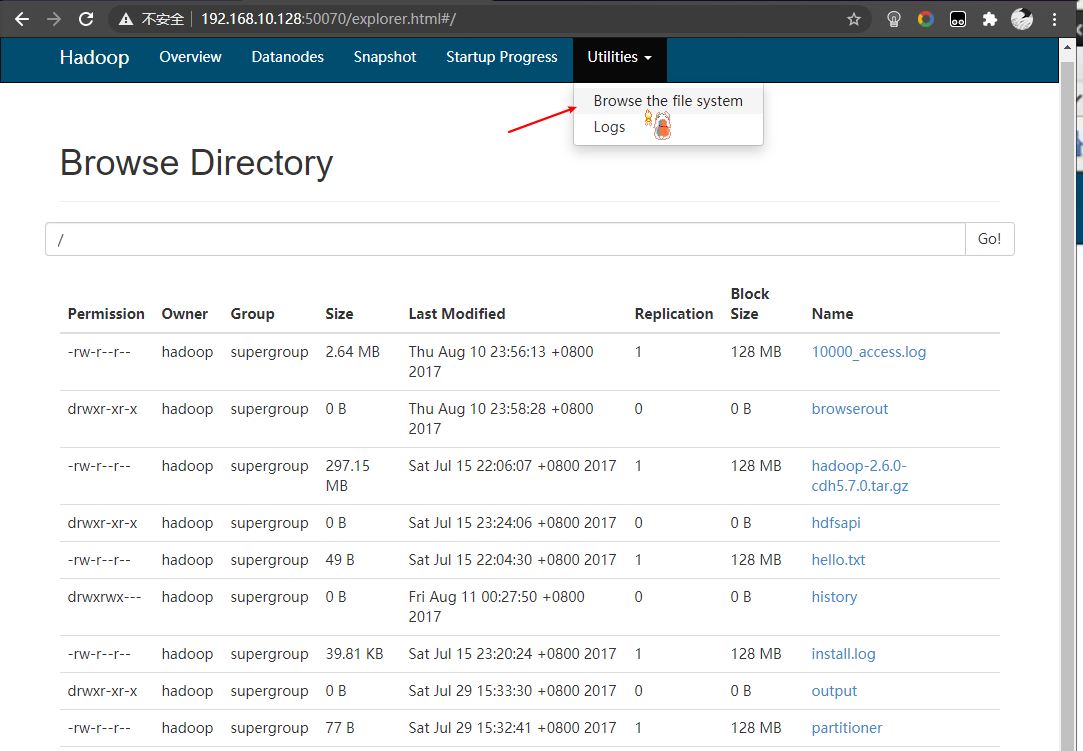
- 路径遍历
- hadoop fs -ls [路径]
- 查看文件
- hadoop fs -cat [文件路径]
- eg:hadoop fs -cat /hadoopruochen/test/ruochen.txt
- 新建文件夹
- hadoop fs -mkdir -p [路径]
- -p:递归新建
- eg:hadoop fs -mkdir -p /hadoopruochen/test
- 传文件到 Hadoop
- hadoop fs -put [文件路径] [hadoop路径]
- eg:hadoop fs -put ruochen.txt /hadoopruochen/test
- 下载 Hadoop 文件到本地
- hadoop fs -get [hadoop文件路径] [本地路径]
- eg:hadoop fs -get /hadoopruochen/test/ruochen.txt haha.txt
- 移动文件
- hadoop fs -mv [源路径] [目的路径]
- eg:hadoop fs -mv /hadoopruochen/test/ruochen.txt /user
- 删除文件
- hadoop fs -rm [-r] [文件]
- eg:hadoop fs -rm /hadoopruochen
- eg:hadoop fs -rm -r /hadoopruochen
5. Java 操作 HDFS API
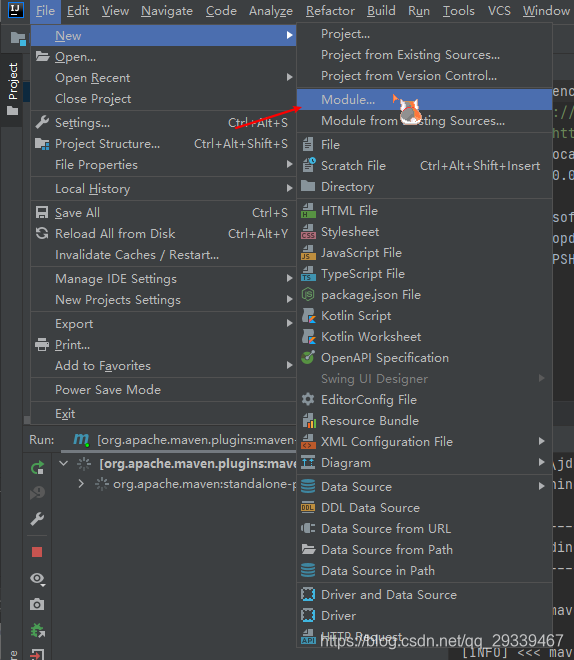
5.1. 新建项目
- 新建一个空项目,我这里起名为
BigData
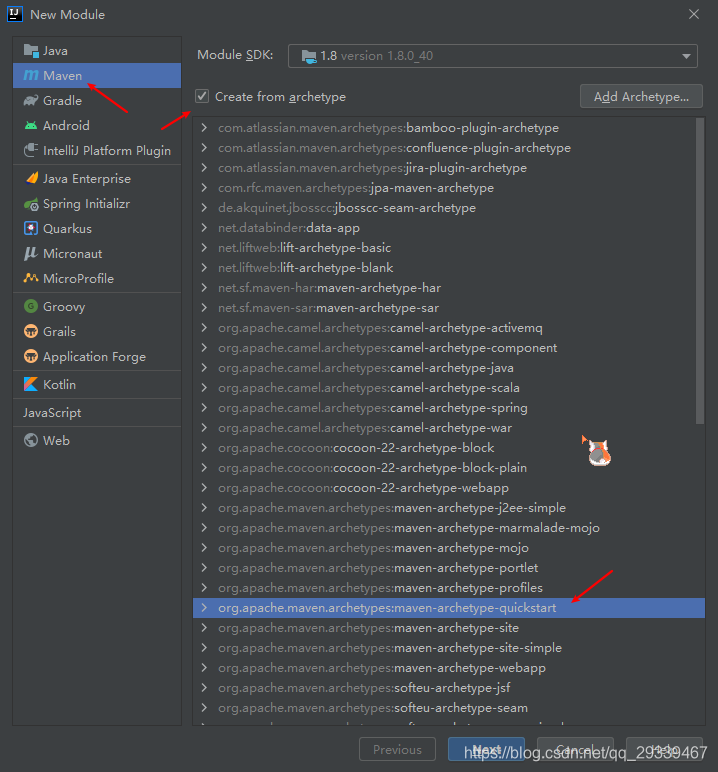
- 新建一个module
- Finish 即可
pom.xml如下

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.neusoft</groupId>
<artifactId>hadoopdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hadoopdemo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!-- 添加hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
5.2. 测试
5.2.1 新建文件夹
- 接下来,我们使用 Java 连接 hdfs,并新建一个文件夹
- 在test下新建
HDFSApp.java,如下
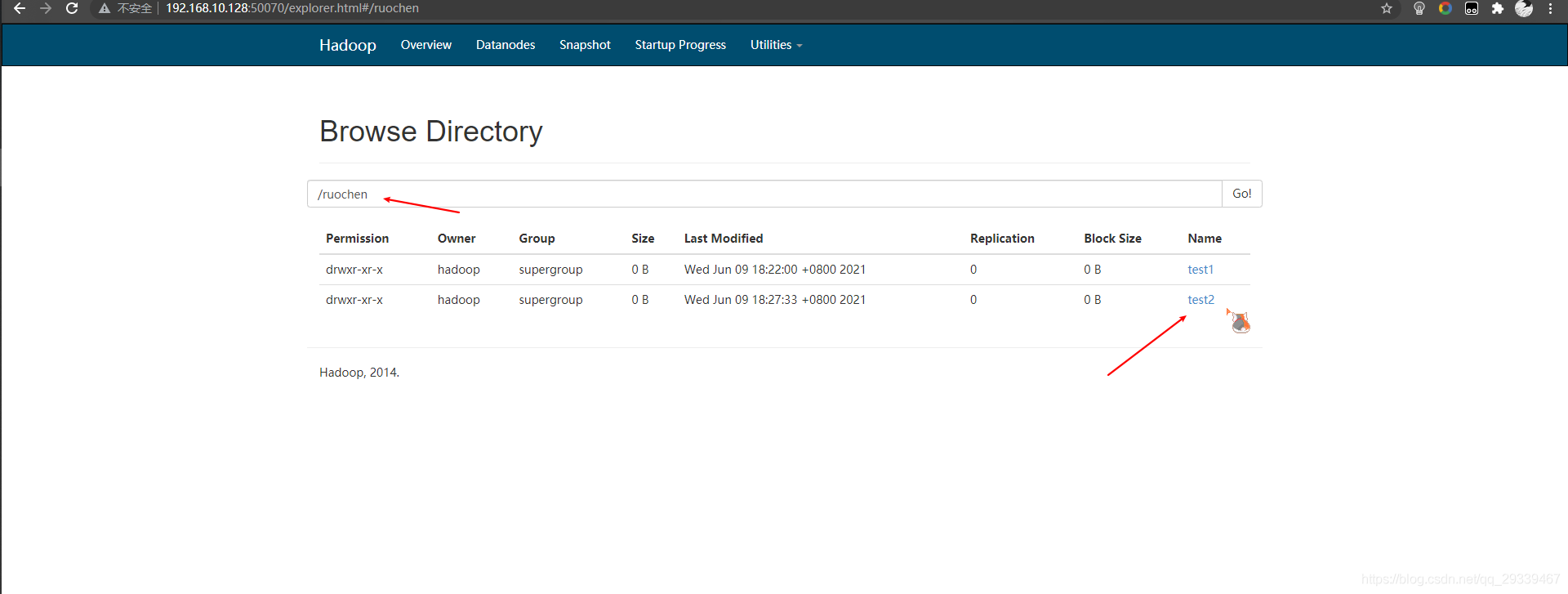
- 通过测试方法连接HDFS,并新建一个
/ruochen/test2文件夹,代码如下package com.neusoft.hdfs; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import org.apache.hadoop.conf.Configuration; import java.net.URI; public class HDFSApp { Configuration configuration = null; FileSystem fileSystem = null; public static final String HDFS_PATH = "hdfs://192.168.10.128:8020"; @Test public void mkdir() throws Exception { fileSystem.mkdirs(new Path("/ruochen/test2")); } // Java 连接hdfs 需要先建立一个连接 // 测试方法执行之前要执行的操作 @Before public void setUp() throws Exception { System.out.println("开始建立与HDFS的连接"); configuration = new Configuration(); fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "hadoop"); } // 测试之后要执行的代码 @After public void tearDown() { configuration = null; fileSystem = null; System.out.println("关闭与HDFS的连接"); } } - 然后运行
mkdir()函数,运行完后我们可以看到已经新建了一个文件夹

5.2.2 新建文件
- 新建文件代码如下
// 创建文件 @Test public void create() throws Exception { Path path = new Path("/ruochen/test1/hello.txt"); FSDataOutputStream outputStream = fileSystem.create(path); outputStream.write("hello world".getBytes()); outputStream.flush(); outputStream.close(); } - 运行结束后,我们通过shell脚本查看一下

5.2.3 修改文件名称
- Java代码如下
// rename文件 @Test public void rename() throws Exception { Path oldPath = new Path("/ruochen/test1/hello.txt"); Path newPath = new Path("/ruochen/test1/xixi.txt"); fileSystem.rename(oldPath, newPath); } - 运行结果如下

5.2.4 查看文件
- Java代码如下
// 查看文件 @Test public void cat() throws Exception { Path path = new Path("/ruochen/test1/xixi.txt"); FSDataInputStream inputStream = fileSystem.open(path); IOUtils.copyBytes(inputStream, System.out, 1024); inputStream.close(); } - 运行结果

5.2.5 上传文件
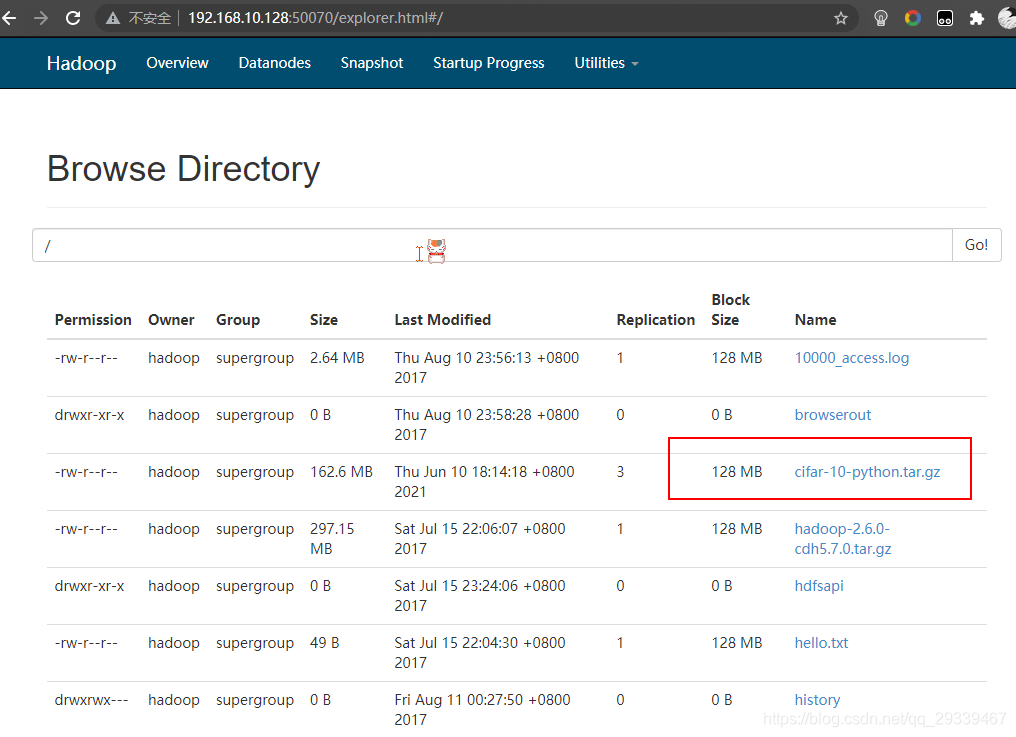
- Java 代码如下
// 上传文件 @Test public void upload() throws Exception { Path localPath = new Path("cifar-10-python.tar.gz"); Path hdfsPath = new Path("/"); fileSystem.copyFromLocalFile(localPath, hdfsPath); } - 运行完成后,我们可以看到 hdfs 已经成功显示刚才上传的文件
5.2.6 下载文件
- Java 代码
// 下载文件 @Test public void download() throws Exception { Path hdfsPath = new Path("/hadoop-2.6.0-cdh5.7.0.tar.gz"); Path localPath = new Path("./down/hadoop-2.6.0-cdh5.7.0.tar.gz"); fileSystem.copyToLocalFile(false, hdfsPath, localPath, true); } - 运行完后我们可以看到当前目录 down 下已经有了刚刚下载的文件
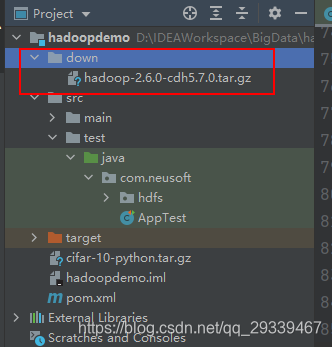
6. Java 实现 WordCount
这里要注意在
main下操作,test下是用来测试的
-
新建一个
WordCountApp类
-
Java 代码如下
package com.neusoft; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 词频统计 */ public class WordCountApp { /** * map 阶段 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 分 String line = value.toString(); // 拆分 String[] s = line.split(" "); for (String word : s) { // 输出 context.write(new Text(word), one); } } } /** * reduce 阶段 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; // 合并统计 for (LongWritable value : values) { // 求和 sum += value.get(); } context.write(key, new LongWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration, "wordcount"); job.setJarByClass(WordCountApp.class); // 设置 map 相关参数 FileInputFormat.setInputPaths(job, new Path(args[0])); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 设置 reduce 相关参数 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(MyReducer.class); job.setOutputValueClass(LongWritable.class); Path outPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if (fileSystem.exists(outPath)) { // 删除文件 fileSystem.delete(outPath, true); System.out.println("输出路径已存在, 已被删除"); } FileOutputFormat.setOutputPath(job, outPath); // 控制台输出详细信息 // 输出:1 不输出:0 System.exit(job.waitForCompletion(true) ? 0 : 1); } } -
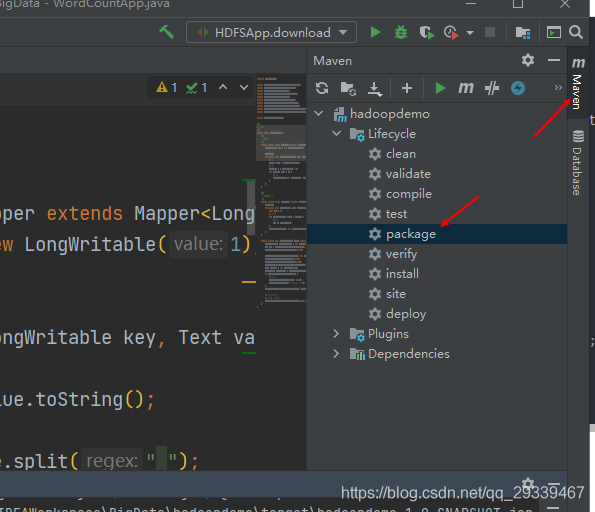
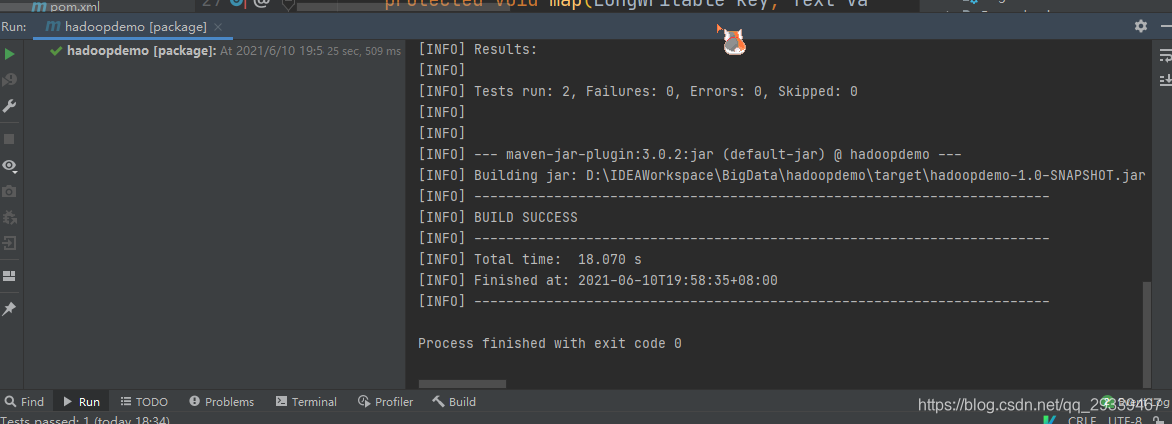
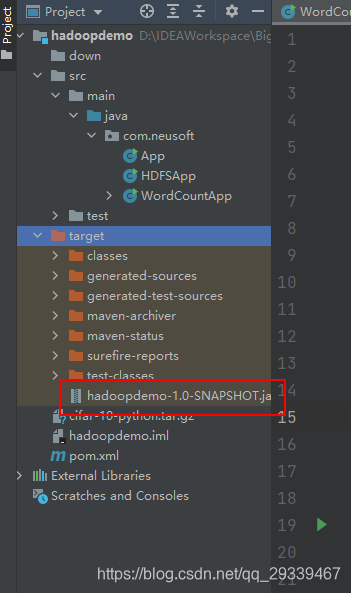
打包程序
-
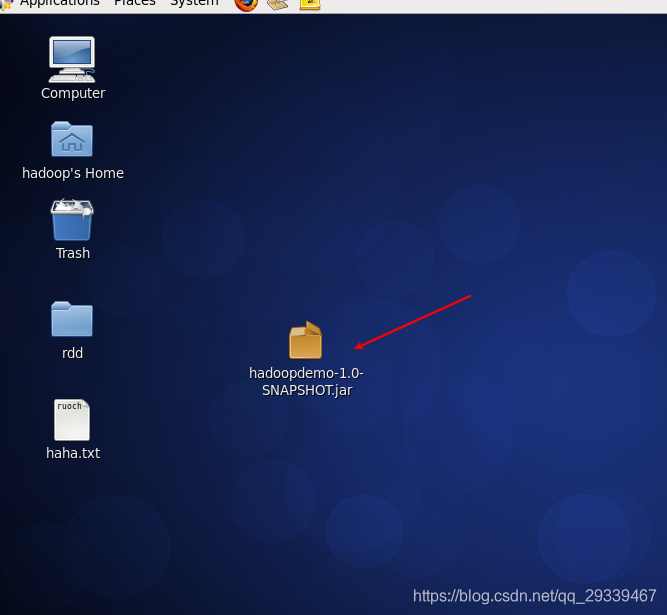
打包完成后,将 jar 包上传到 hadoop 虚拟机
-
首先通过shell命令将输出文件夹删除,不然重复执行会报错
hadoop fs -rm -r /output/wc -
然后执行下列操作
hadoop jar hadoopdemo-1.0-SNAPSHOT.jar com.neusoft.WordCountApp hdfs://hadoop000:8020/ruochenchen.txt hdfs://hadoop000:8020/output/wchadoop jar hadoopdemo-1.0-SNAPSHOT.jar com.neusoft.WordCountApp
输入文件输出文件 -
然后我们可以看到作业中有显示
-
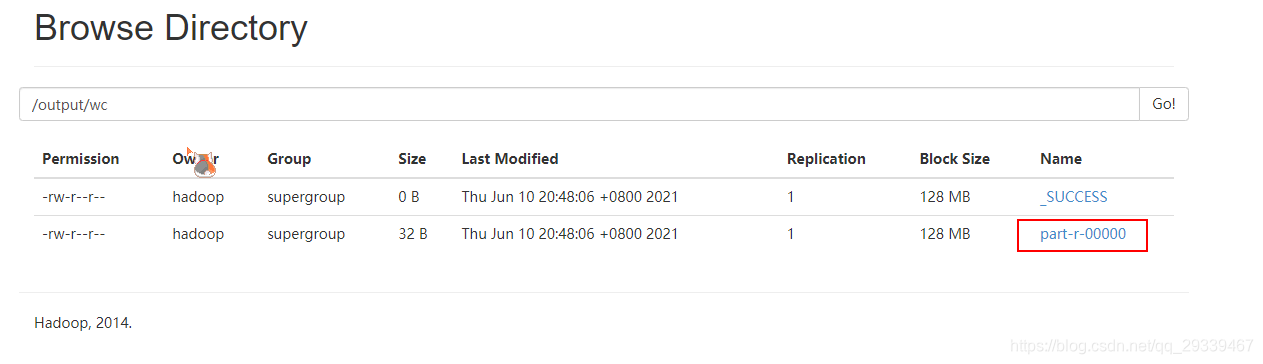
通过
cat命令可以查看一下输出的文件
hadoop fs -cat /output/wc/part-r-00000




【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)