热点复现|谁是最赚钱的港股企业?

最近,各种介绍爬虫的文章火爆公众号。让我们在ModelArts上做些复现,来看看谁是最赚钱的港股企业吧。一方面,爬虫也能爬取A股交易信息;另一方面,财务数据也是量化投资应该考虑的重要方面。因此,本文可以与上一期结合,进行更多维度的量化研究。考虑到A股财务数据来源广泛,本文以港股为例,有兴趣做A股量化研究的小伙伴可以自己去尝试。
1. 网页分析
首先,让我们进入东方财务网站并点击港股  选择港股市场下的全部港股
选择港股市场下的全部港股  可以看到港股的代码是5位的数字
可以看到港股的代码是5位的数字 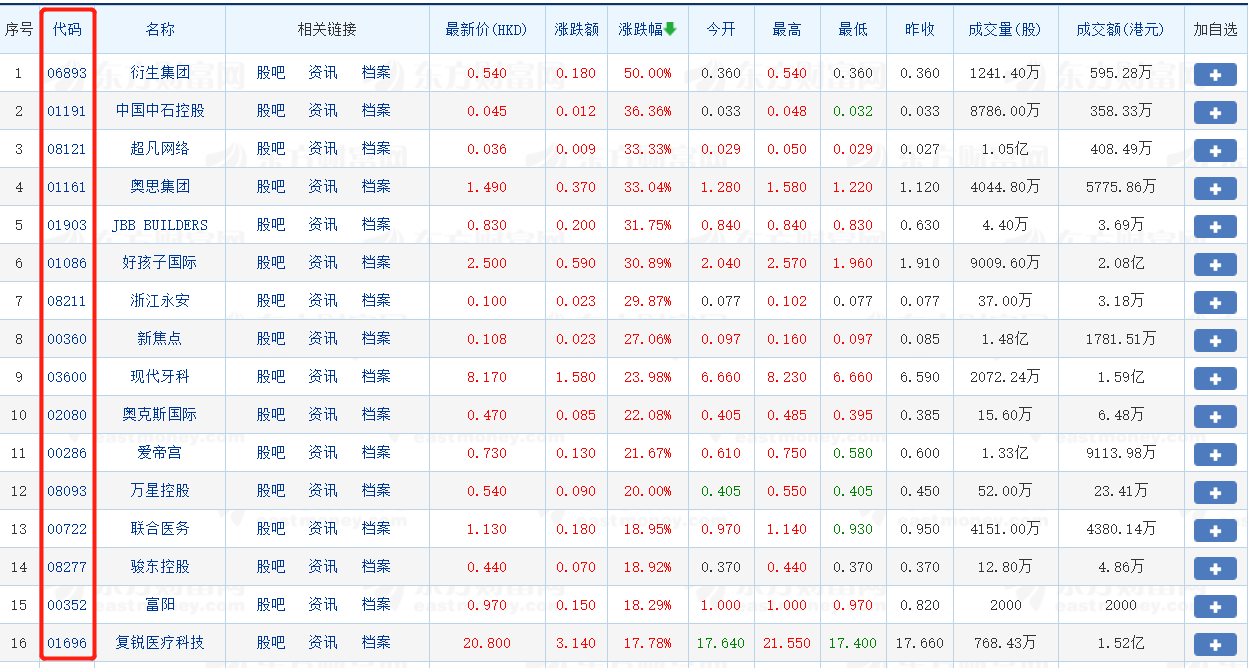 任选一个股票,点击财务分析
任选一个股票,点击财务分析  按Crtl+Shift+i打开开发者工具
按Crtl+Shift+i打开开发者工具 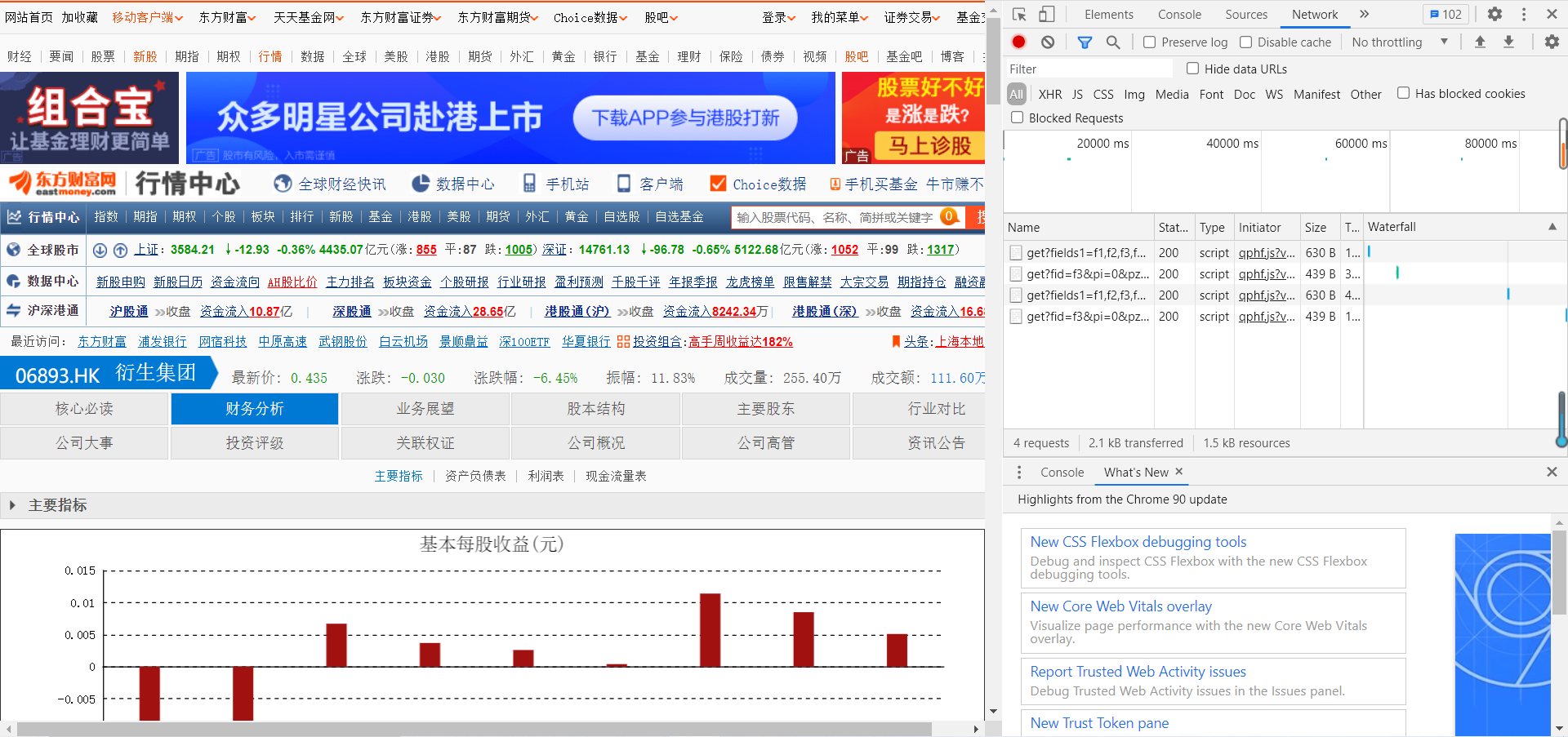 点击资产负债表
点击资产负债表  再点击按年度
再点击按年度 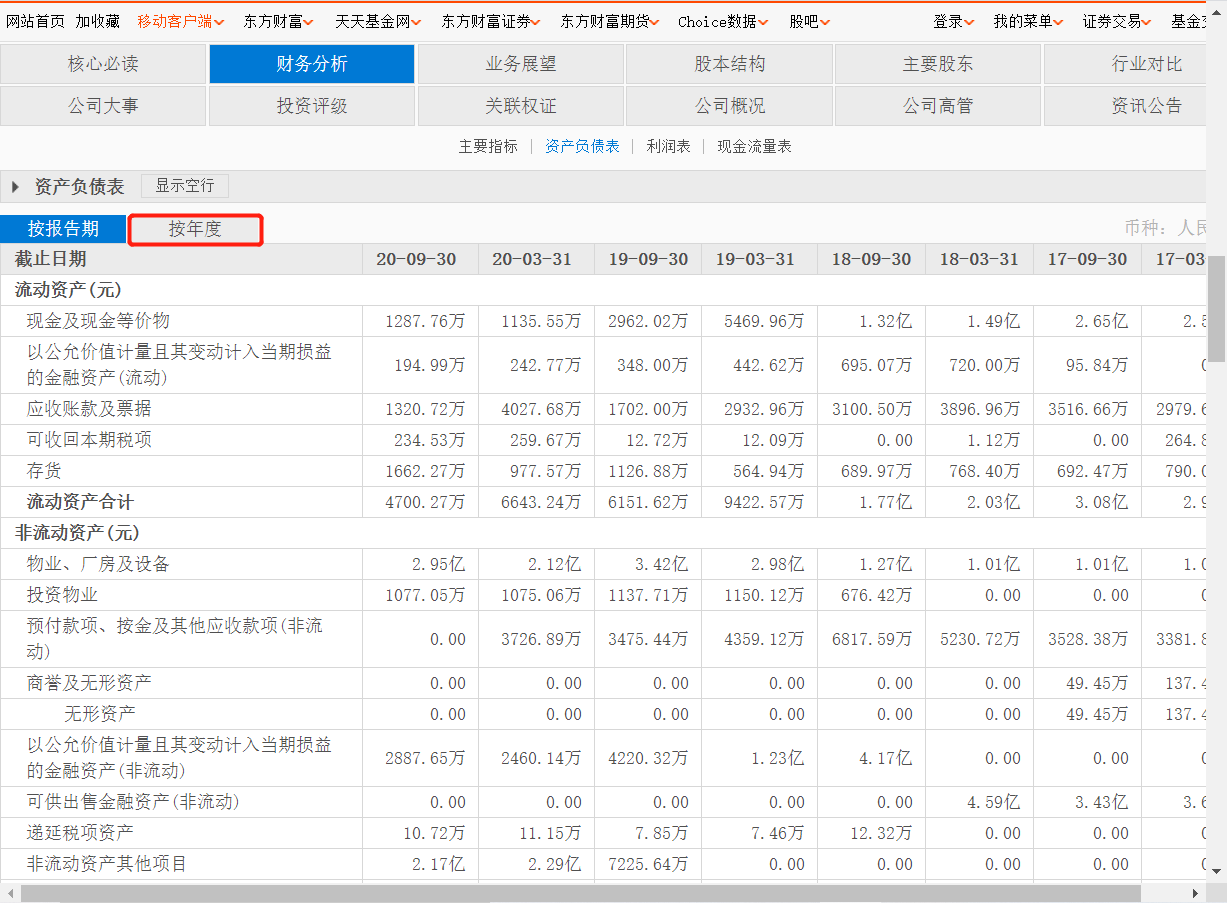 可以看到年度资产负债表的数据来源于以下get方法
可以看到年度资产负债表的数据来源于以下get方法 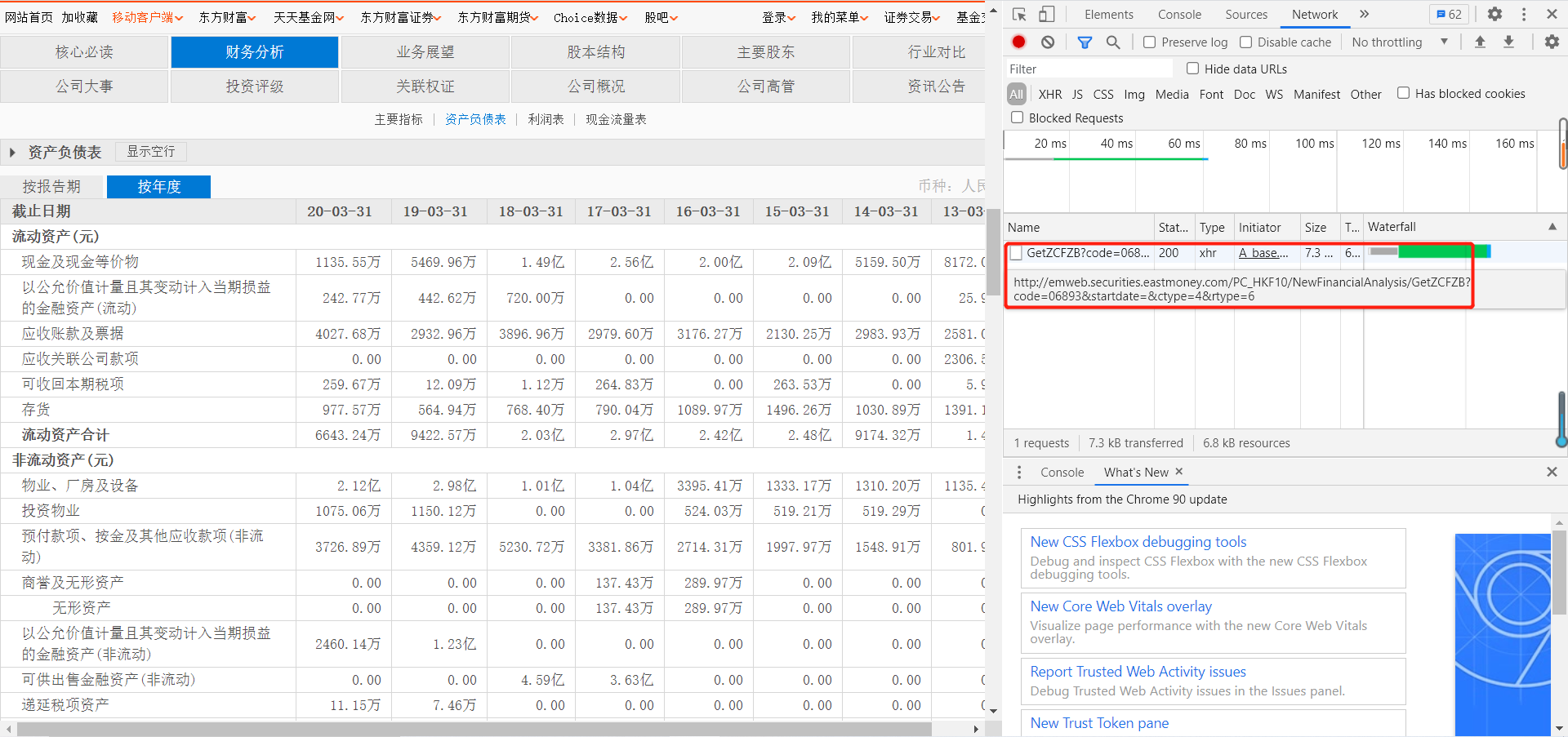
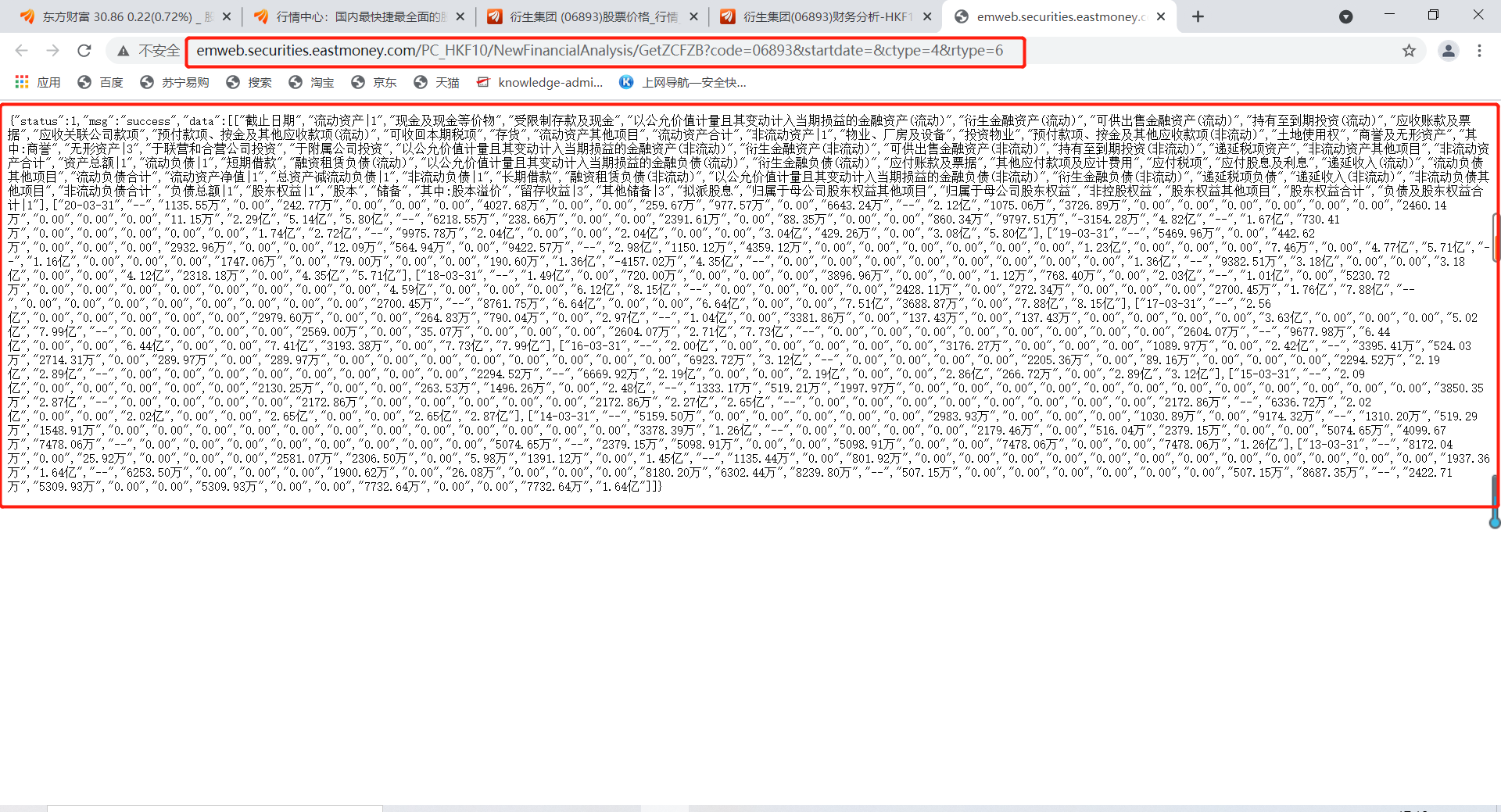 可以看到url里有一个五位数的港股代码,只需要将它改成另一个代码,就能获得另一家港股的资产负债数据
可以看到url里有一个五位数的港股代码,只需要将它改成另一个代码,就能获得另一家港股的资产负债数据  利润表和现金流量表也有同样的情况,小伙伴们可以自己尝试。
利润表和现金流量表也有同样的情况,小伙伴们可以自己尝试。
2. 数据爬取
接下来是代码时刻,让我们在ModelArts上把2019年年度财务数据爬下来
2.1. 爬取案例
先让我们用衍生集团来尝试下最近一个年度财务数据的爬取
导入需要的包
import urllib.request
import json
import pandas as pd
初始化代码
scode = '06893'
生成get方法需要的url
url ='http://emweb.securities.eastmoney.com/PC_HKF10/NewFinancialAnalysis/GetZCFZB?code=' + scode + '&startdate=&ctype=4&rtype=6'
调用get
a = urllib.request.urlopen(url)
解码、转化为DataFrame格式并打印
html = a.read().decode('utf-8')
result = json.loads(html)
if len(result1['data']):
data = pd.DataFrame(result['data'][1:], columns = result['data'][0])
data
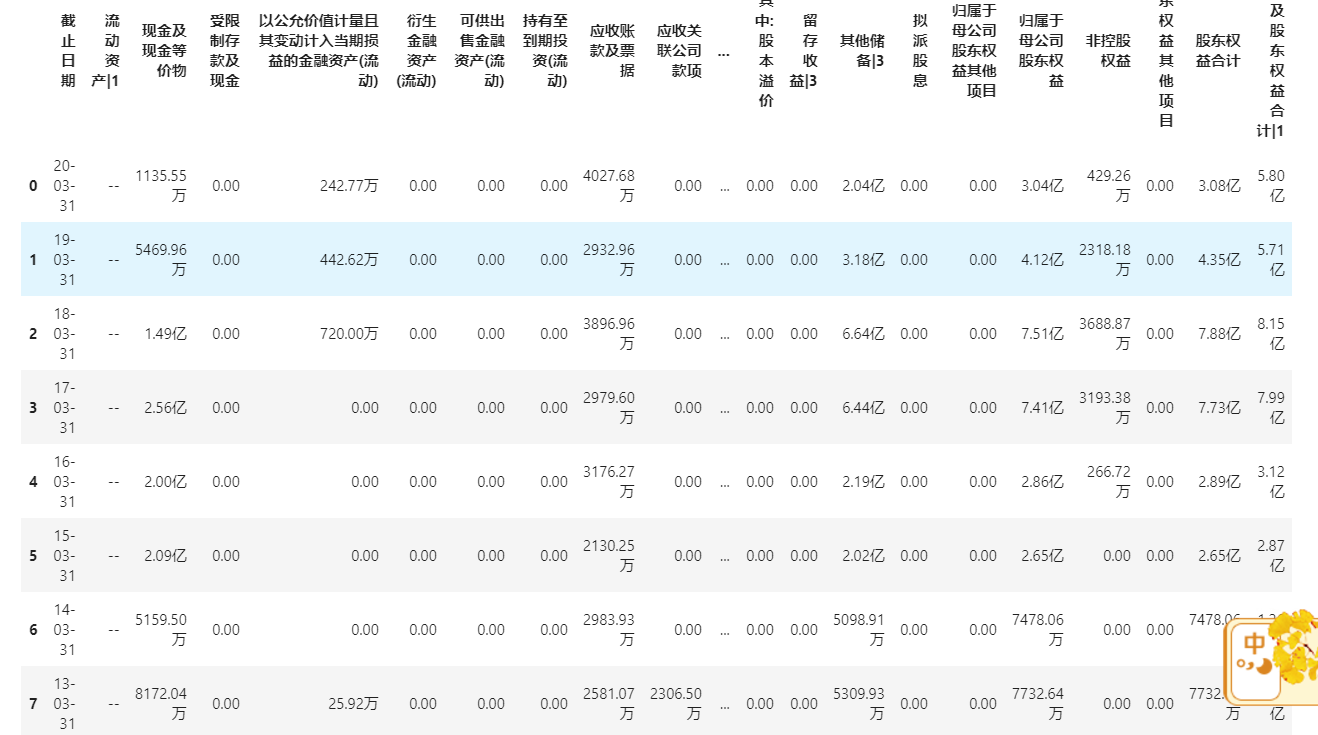 可以看到衍生集团居然还没有公布20年年报。
可以看到衍生集团居然还没有公布20年年报。
让我们换一家,以新焦点为样本。我们先重复以上操作
scode = '00360'
url ='http://emweb.securities.eastmoney.com/PC_HKF10/NewFinancialAnalysis/GetZCFZB?code=' + scode + '&startdate=&ctype=4&rtype=6'
html = urllib.request.urlopen(url).read().decode('utf-8')
result = json.loads(html)
if len(result['data']):
data = pd.DataFrame(result['data'][1:], columns = result['data'][0])
data
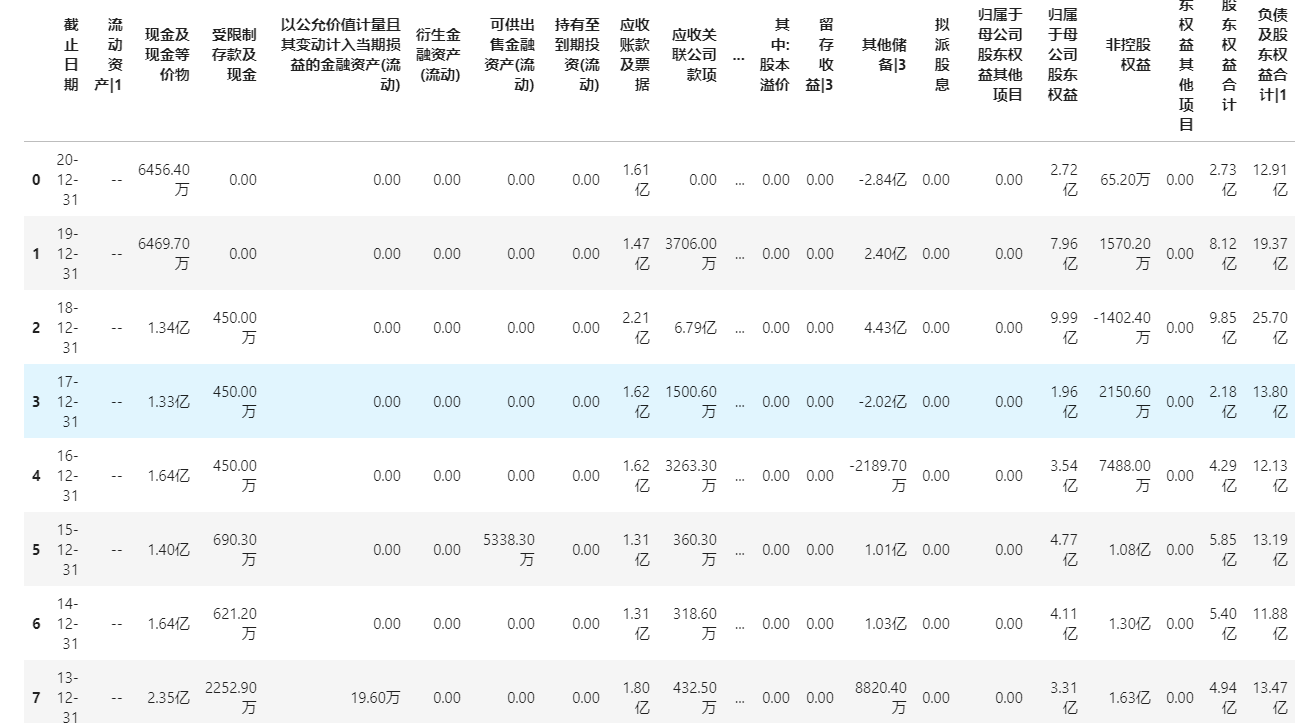 可以看到新焦点已经公布了20年年报,我们写入代码并截取年报
可以看到新焦点已经公布了20年年报,我们写入代码并截取年报
data['scode'] = scode
data = data.loc[0:0, :]
data
将上述过程包装成函数,并且只考虑已经发布20年年报的港股
def getdata(url, seccode):
try:
html = urllib.request.urlopen(url % seccode).read().decode('utf-8')
except:
return '代码不存在'
result = json.loads(html)
if result['data'] is None or not len(result['data']):
return '还没有数据'
data = pd.DataFrame(result['data'][1:], columns = result['data'][0])
data['scode'] = seccode
data = data.loc[data['截止日期']=='20-12-31', :]
if len(data):
return data
return '没有20年报表'
2.2. 爬取所有港股财务数据
直接上代码
#初始化三个财务表DataFrame
#每个股票需要爬取三个报表,所以初始化url列表
urls = ['http://emweb.securities.eastmoney.com/PC_HKF10/NewFinancialAnalysis/GetZCFZB?code=%s&startdate=&ctype=4&rtype=6',
'http://emweb.securities.eastmoney.com/PC_HKF10/NewFinancialAnalysis/GetLRB?code=%s&startdate=&ctype=4&rtype=6',
'http://emweb.securities.eastmoney.com/PC_HKF10/NewFinancialAnalysis/GetXJLLB?code=%s&startdate=&ctype=4&rtype=6']
#初始化三表
zcfzb = pd.DataFrame()
lrb = pd.DataFrame()
xjllb = pd.DataFrame()
#初始化港股代码表,虽然可以找到接口或爬取到列表,我们也可以简单罗列1-99999,通过尝试性爬取来去掉不正确的代码
for seccode in range(1, 100000):
seccode = str(seccode).zfill(5)
#获取资产负债表数据
data = getdata(urls[0], seccode)
#如果获取到资产负债表数据,写入zcfzb
if not isinstance(data, str):
#如果资产负债表没有数据,初始化列名
if not len(zcfzb):
zcfzb = data[data['截止日期']=='']
zcfzb.loc[len(zcfzb), :] = data.loc[0, :]
#获取利润表数据
data = getdata(urls[1], seccode)
#如果获取到数据,写入lrb
if not isinstance(data, str):
#如果利润表没有数据,初始化列名
if not len(lrb):
lrb = data[data['截止日期']=='']
lrb.loc[len(lrb), :] = data.loc[0, :]
#获取现金流量表数据
data = getdata(urls[2], seccode)
#如果获取到数据,写入xjllb
if not isinstance(data, str):
#如果现金流量表没有数据,初始化列名
if not len(xjllb):
xjllb = data[data['截止日期']=='']
xjllb.loc[len(xjllb), :] = data.loc[0, :]
3. 数据分析
先来观察下港股代码
','.join(list(lrb.scode.astype(str)))
 可以看到,除了80737,港股代码实际上在1-9999之间。而进一步分析也可以发现80737实际上并不是港股代码。 观察营业收入的数据
可以看到,除了80737,港股代码实际上在1-9999之间。而进一步分析也可以发现80737实际上并不是港股代码。 观察营业收入的数据
lrb_data = lrb[['营业收入(计算)', 'scode']]
lrb_data
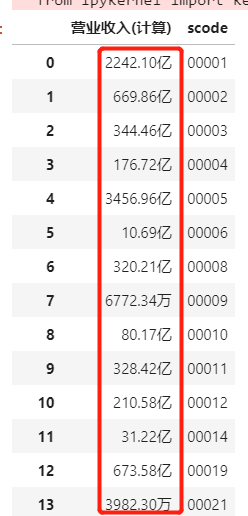
可以发现营业收入是string型,且单位并不统一。因此首先统一单位
def str2float(s):
if isinstance(s, str):
if s.endswith('万亿'):
return float(s[:-2]) * 1000000000000
if s.endswith('亿'):
return float(s[:-1]) * 100000000
if s.endswith('万'):
return float(s[:-1]) * 10000
return float(s)
lrb_data['营业收入'] = lrb_data['营业收入(计算)'].apply(str2float)
lrb_data
很遗憾的是这种写法会造成内存不足,除了升级内存,只能改写代码。
只需要将
lrb_data['营业收入'] = lrb_data['营业收入(计算)'].apply(str2float)
改写成
lrb_data['营业收入'] = 0
for i in lrb_data.index:
lrb_data.loc[i, '营业收入'] = str(lrb_data.loc[i, '营业收入(计算)'])
接下来,用一行代码我们就能看到谁是最赚钱的港股企业了
lrb_data.sort_values(by='营业收入', ascending=False).reset_index()
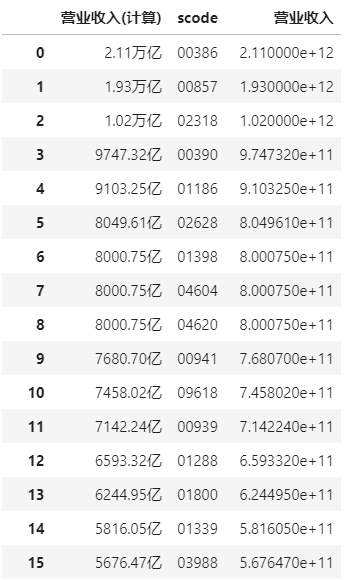
至此,我们爬取并简单分析了港股财务数据,找到了2020年最赚钱的港股企业,做量化研究的时候可以尝试把各种财务指标引入量化模型。

- 点赞
- 收藏
- 关注作者
评论(0)