Java---XML的解析(2)-DOM4J解析/Xpath

Dom4j:
Dom SUN
dom在加载时,将所有元素全部加载内存
DOM4j - 第三方。
Dom4j是一个开源、灵活的XML API。
目前很多开源框架如struts,hibernate都使用dom4j做为解析其xml的工具。
支持文档的读写功能和Xpath快速查询操作。
这个需要我们自己把它的包导入myeclipse中的。
准备DOM4j:
包:dom4j.x.jar
包结构:
org.dom4j
类
org.dom4j.io.SAXReader – xml文档解析器
org.dom4j.Document、Element – 文档对像
需要知道的 Element的一些方法
Element.element(“name”) –此元素下的第一个name元素。
Element.elementIterator(“name”) – 此元素下的所有name元素。返回Iterator
Element.getText() – 返回元素包含的文本。
Element.getAttribute(“name”) – 返回名称为name的属性。
Element.addElement(“name”); - 添加一个name元素,同时返回name元素本身。
org.dom4j.io.XMLWriter – 将Document写出的对像。
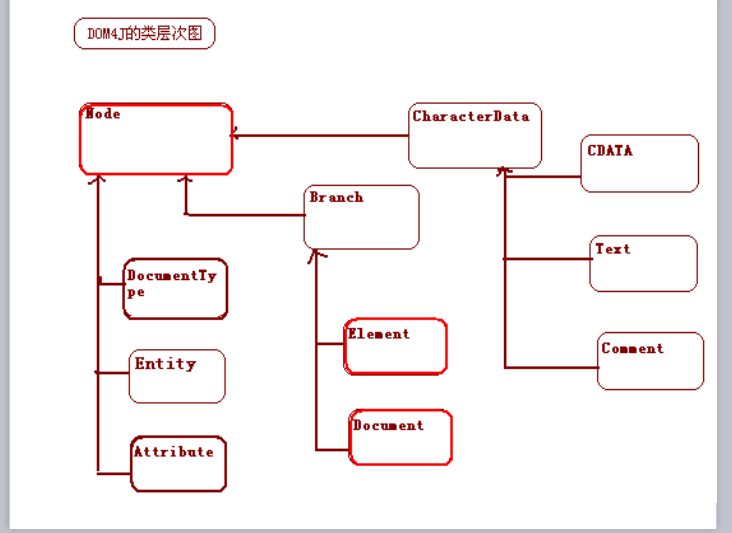
DOM4J的层次图:
使用UTF-8编码,解决中文乱码:
//声明编码格式
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
//保存(XMLWriter默认情况下即是使用UTF-8编码。所以,如果使用OutputStream保存,且正好是UTF-8编码,则不必担心乱码问题)
XMLWriter xml = new XMLWriter(new FileOutputStream("./src/xml/a.xml"),format);
xml.write(doc);
Dom4j-保存节点-处理中文乱码:
在JavaIO中,writer总是本地编码格式处理数据。即GB2312 所有,使用writer写出数据有可能会发生一些问题,如保存不完整,或是乱码: XMLWriter writer = new XMLWriter(new FileWriter(“a.xml”)); //写出数据 writer.write(doc); 所以,建议在写出数据时,使用OutputStream保存数据。
记住:删除一个节点时,要用它的父节点删除它。
添加或修改属性的方法:addAttribute
Dom4j-从没有到有生成一个新的xml:
//通过DocumentHelper在内存中创建一个Document
Document doc = DocumentHelper.createDocument();
doc.setXMLEncoding(“UTF-8”);//XML的编码格式
//生成一个节点,生成的第一个节点也是根节点,此方法只使用一次
Element root = doc.addElement(“users”);
- 1
- 2
- 3
- 4
- 5
Xpath
XML PATH Language。
可以实现快速查询。
XPATH包含
XPath 使用路径表达式在 XML 文档中进行导航 。
XPath 包含一个标准函数库
准备Xpath的包:
jaxen.jar
Xpath通过以下方法使用
dom.selectNodes – 返回一个 List对像
dom.selectSingleNode – 返回一个Node对像
//以下选择所有的user节点,处理不带命名空间的安以下原则
List<Element> list = doc.selectNodes("//user");
System.err.println(list.size());
//以下选择所有name节点
list = doc.selectNodes("//name");//或从要开始:/users//name
System.err.println(list.size());
//以下选择所在带有country属性的节点
list = doc.selectNodes("//user[@country]");
System.err.println(list.size());
//选择国家是 EN的节点,可以使用以下方法查询用户登录
//如果country不能重复则可以使用selectSingleNode
//使用双引号或单引号都可以://user
Node node = doc.selectSingleNode("//user[@country=\"EN\"]");
System.err.println(node);
Xpath通过查询子元素的值,区别主要元素:
如:XML文档如下:
<books>
<book id=“A001”> <name>Oracle编程基础</name> <price>89.99</price>
</book>
</books>
查询包含Oracle一词的所有book元素。
//book[name=‘Oracle’] //精确查询子元素name的值为Oracle的book元素
//以下是模糊查询
//book[contains(name,’Oracle’)]
//也可以将name元素的值转成小写
//book[contains(fn:lower-case(name),’oracle’]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
这个稍微了解一下:
Xpath处理带有命名空间的XML文档:
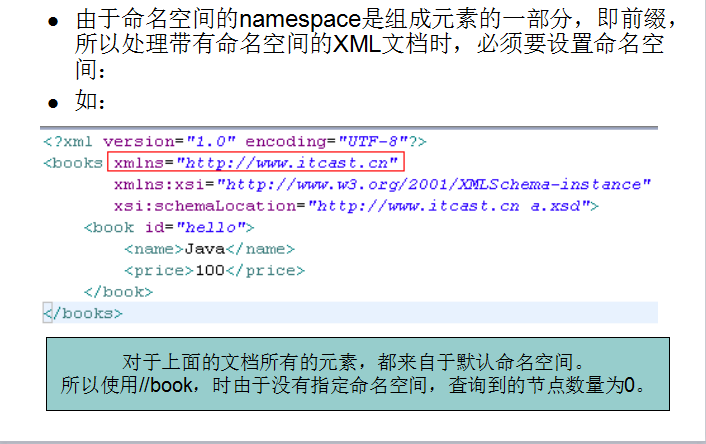
SAXReader sax = new SAXReader();
//声明一个map用于保存命名空间
Map<String,String> uris = new HashMap<String, String>();
//给命名空间取一个别名
uris.put("a", "http://www.itcast.cn");
//设置命名空间后再读取xml文档
sax.getDocumentFactory().setXPathNamespaceURIs(uris);
Document dom = sax.read("./xml2/a.xml");
//然后使用带有命名空间的前缀查询即可。
dom.selectNodes(“//a:book”);
//带有属性的查询同前
dom.selectNodes(//a:book[@id]
//带有元素的查询必须要添加命名空间的前缀
dom.seletNodes(“//a:book[a:name=‘oralce’]”); //查询子元素值为oracle的book元素
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
SAX,StAX读取速度快。都是JAXP的成员。
StAX-Iterator编程接口和Cursor编程接口。
Dom4j。Dom。都会将所有节点加载加载到内存中。CRUD非常方便。
Dom4j支持XPath.
演示代码:::
package cn.hncu.dom4j;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.Iterator;
import java.util.List;
import java.util.Scanner;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class Dom4jDemo { @Test public void readDemo() throws Exception{ //声明SAXReader核心读取(xml)类,并获得dom对象 SAXReader sax = new SAXReader(); Document dom = sax.read("xml5/users.xml"); //获取根节点 Element root = dom.getRootElement(); //获取里面的第一个子元素 Element user = root.element("user"); String id = user.attributeValue("id"); System.out.println(id); String name = user.element("name").getText();//获取子元素中的文本内容--法1 String age = user.elementText("age");//获取子元素中的文本内容--法2 System.out.println(name+","+age); } //显示(遍历)所有用户 @Test public void readAll() throws Exception{ SAXReader reader = new SAXReader(); Document document = reader.read("xml5/users.xml"); Element root = document.getRootElement(); Iterator<Element> it = root.elementIterator(); while(it.hasNext()){ Element e = it.next(); String id = e.attributeValue("id"); String name = e.elementText("name"); String age = e.element("age").getText(); System.out.println("id:"+id+",name:"+name+",age:"+age); } } //添加一个user元素 @Test public void addElement() throws Exception{ SAXReader sax= new SAXReader(); Document document = sax.read("xml5/users.xml"); Element root = document.getRootElement(); Element e = root.addElement("user"); e.addAttribute("id", "C003"); Element eName = e.addElement("name"); eName.setText("张三"); Element eAge = e.addElement("age"); eAge.setText("24"); //要把内存中的dom对象写到磁盘中 //法一---功能有限
// FileWriter fw = new FileWriter("xml5/users.xml");//输出到控制台
// document.write(fw);
// fw.close(); //法二---功能更强 OutputFormat format = OutputFormat.createCompactFormat(); format.setEncoding("utf-8"); XMLWriter writer = new XMLWriter(new FileWriter("xml5/users.xml"), format); //以指定的输出格式,把dom输出到指定的目的地(文件) writer.write(document); writer.close(); } //删除最后一个user元素 @Test public void delElement() throws Exception{ SAXReader reader = new SAXReader(); Document document = reader.read("xml5/users.xml"); Element root = document.getRootElement(); List<Element> list = root.elements(); Element e = list.get(list.size()-1); e.getParent().remove(e); //保存 XMLWriter writer = new XMLWriter(new FileWriter("xml5/users.xml")); writer.write(document); writer.close(); } //从零开始创建一个xml文档 @Test public void createNewXml() throws IOException, FileNotFoundException{ Document document = DocumentHelper.createDocument(); Element root = document.addElement("hncu"); root.addElement("department").addAttribute("id", "hncu001").addElement("xky").setText("信息科学与工程学院"); //保存 XMLWriter writer = new XMLWriter(new FileOutputStream("xml5/hncu.xml")); writer.write(document); writer.close(); } //xpath的用法 @Test public void xpathDemo() throws Exception{ SAXReader sax = new SAXReader(); Document dom = sax.read("xml5/contact.xml"); //String xpath = "/*/name";//第一个/表示当前元素 //String xpath="//contact/name";//选择contact下面的name(儿子) //String xpath="//aaa/preceding::*";//选择<aaa>前面的所有元素 String xpath="//*[@id]";//选择具有id属性的所有元素 Element root = dom.getRootElement(); System.out.println(root.getName()); List<Element> list = root.selectNodes(xpath); for(Element e:list){ System.out.println(e.getName()+"--"+e.getText()); } } //xpath用法 @Test public void xpathDemo2() throws Exception { SAXReader sax = new SAXReader(); Document dom = sax.read("xml5/contact.xml"); Scanner sc = new Scanner(System.in); String name =sc.next(); //name=name.toLowerCase(); String pwd = sc.next(); //String xpath="//user[@name][@pwd]";//选择同时包含name和pwd属性的user元素 //String xpath="//user[@name='Jack'][@pwd='1234']";//选择name='Jack'且pwd='1234'那个user元素 //String xpath="//user[@name='"+name+"'][@pwd='"+pwd+"']";//按照输入的name和ped查找那个user---name区分大小写 String xpath="//user[fn:lower-case(@name)='"+name+"'][@pwd='"+pwd+"']";//按照输入的name和ped查找那个user---name不区分大小写 System.out.println(xpath); List<Element> list = dom.selectNodes(xpath); for(Element e:list){ System.out.println(e.getName()); List<Element> eList = e.selectNodes("//contact/name"); for(Element e2:eList){ System.out.println(e2.getText()); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
文章来源: chenhx.blog.csdn.net,作者:谙忆,版权归原作者所有,如需转载,请联系作者。
原文链接:chenhx.blog.csdn.net/article/details/51832369

- 点赞
- 收藏
- 关注作者
评论(0)