Python构建代理池,突破IP的封锁爬取海量数据(附项目源码)

【摘要】 测了75个,大概50个可以用。 质量也比较高,可以尝试构建代理池,从此不用为被封ip烦恼了。
个人公众号 yk 坤帝
后台回复 ip代理 获取源代码
熟悉爬虫的朋友都知道,高质量的ip非常重要。
那么我们如何快速获得ip呢,今天我就带大家使用爬虫来获取免费的ip。(亲自测试,获取到的代理百分之八十可用)
1. 打开网站首页
可以看到每页有15个数据。咱们的目的很简单,就是要这15x5条ip和对应端口号。完了我们再去筛选那些ip是可用的。
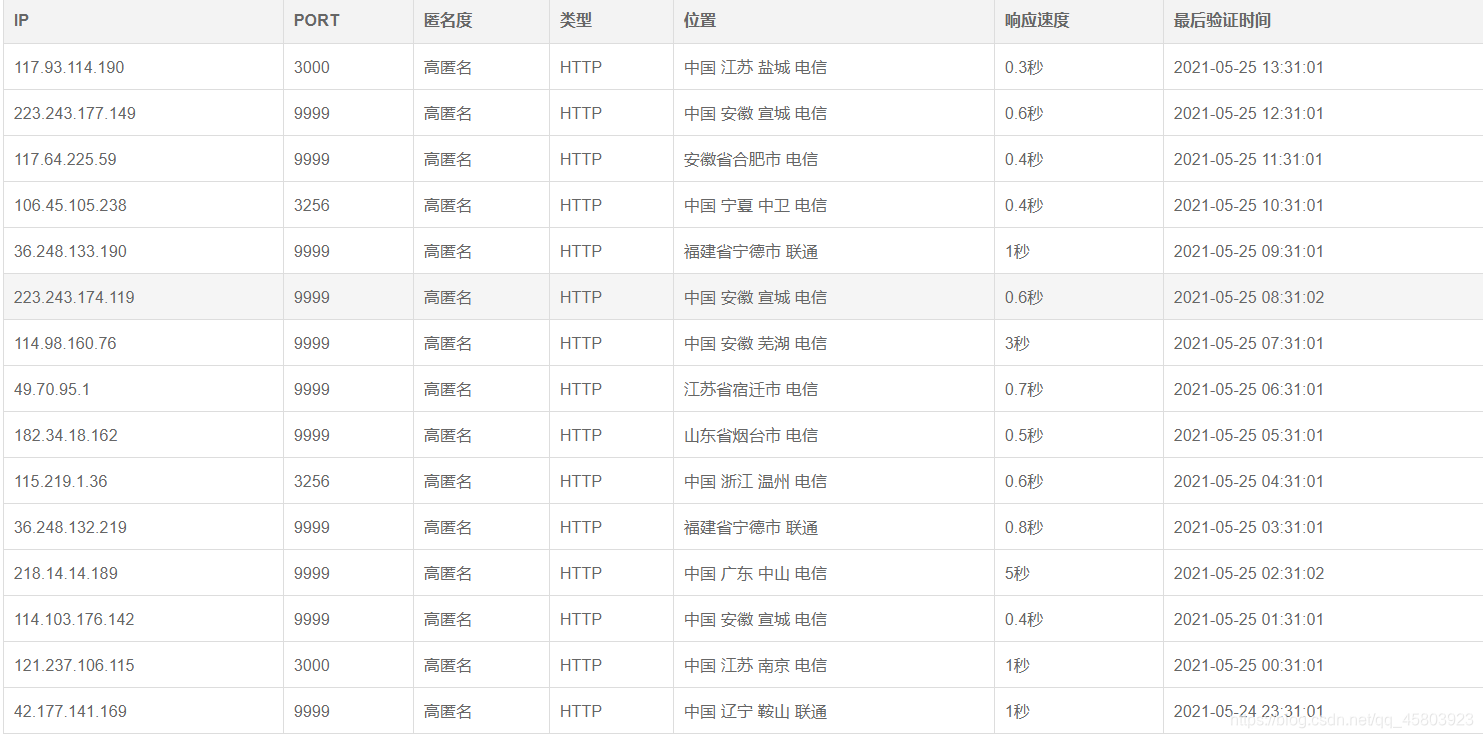
所有的页数(这里爬取5页,学习所用)
2. 我们打开浏览器模式模式
分析页面看到这些ip信息都位于tr标签内,所以我么可以使用xpath来获取这些信息。
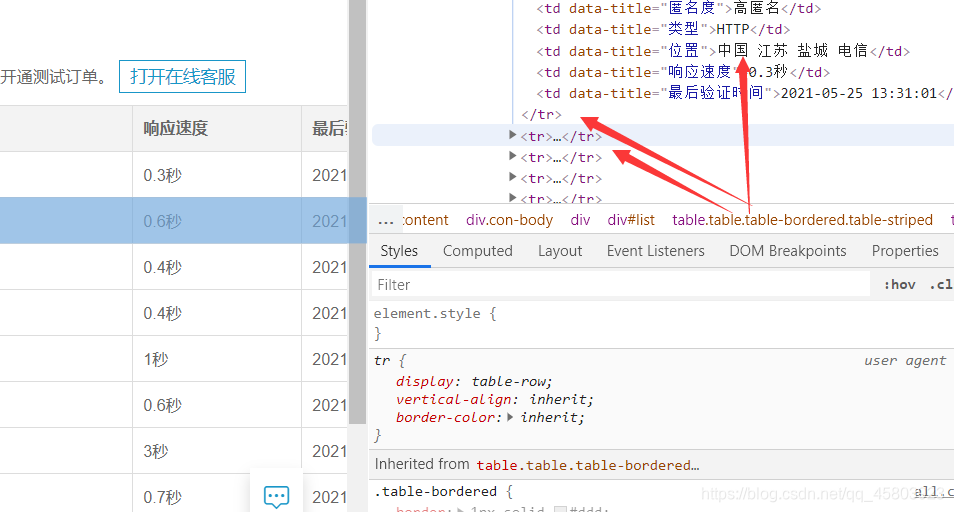
trs = tree.xpath('//*[@id="list"]/table/tbody/tr')
3. 获取到当前页面所有ip信息
获取到当前页面所有ip信息之后我们就可以使用for循环获取tr标签内部具体的ip和端口号。
for tr in trs:
ip_num = tr.xpath('./td[1]/text()')[0]
ip_port = tr.xpath('./td[2]/text()')[0]
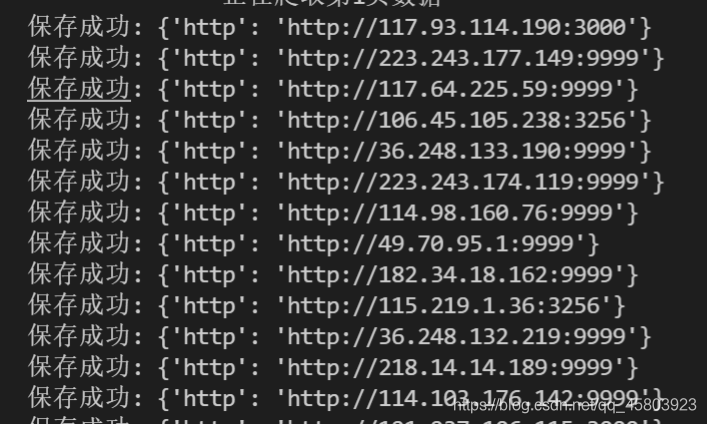
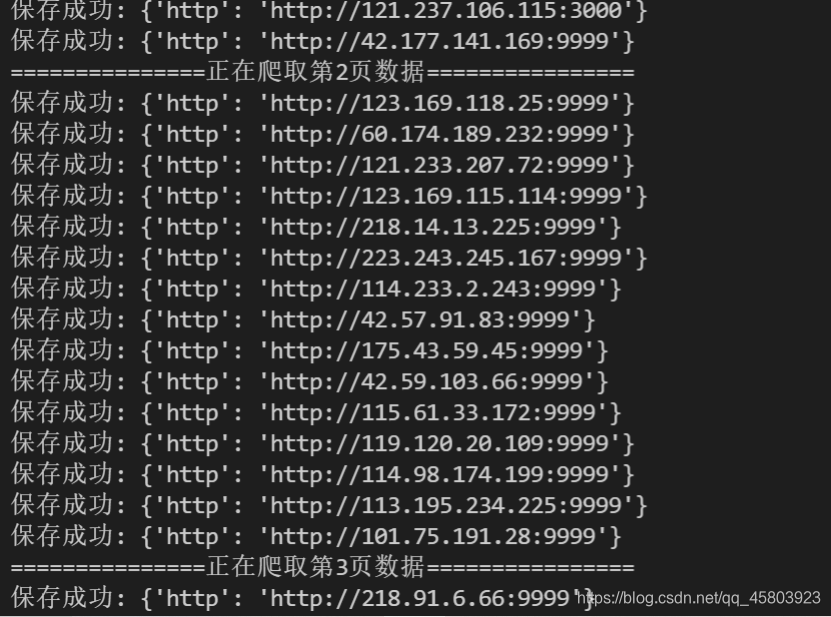
4. 接下来就使用for循环获取15x5条数据。
for page in range(1,6):
time.sleep(1)
print(f'===============正在爬取第{page}页数据================')
url = f'https://www.kuaidaili.com/free/inha/{page}/'
5. 测试可用性
现在所有的ip都已经获取到了,能不能用还是未知数,所以我们试着有这些ip登陆一下百度页面,检测其可用性。
for ip in proxies_list:
try:
response = requests.get(url = 'https://www.baidu.com',proxies = ip,timeout = 0.1)
if response.status_code == 200:
can_use.append(ip)
except:
print('当前的代理:',ip,'请求超时,检测不合格')
else:
print('当前的代理:',ip,'检测合格')
检测结果如下:

打造属于自己的ip代理池(从此再也不怕爬虫ip被封了)亲测可用
测了75个,大概50个可以用。 质量也比较高,可以尝试构建代理池,从此不用为被封ip烦恼了。
个人公众号 yk 坤帝
后台回复 ip代理 获取源代码

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)