用Python爬取图片

【摘要】 前言 有的时候,我们喜欢去网站浏览一些美图,或者是在平时工作学习中,需要一些好看的图片来作为素材,亦或是无聊的时候想要打发时间,去放松放松,这个时候难道你还在一张一张的点开链接,去浏览吗?我想在这个数据爆发的时代,这样做是不是有点费时间了,下面我们就来看看一波操作!让你一饱眼福…
导入库 导入一些爬虫需要的第三库,是我们爬虫首先的一步:
from bs4 impor...
前言
有的时候,我们喜欢去网站浏览一些美图,或者是在平时工作学习中,需要一些好看的图片来作为素材,亦或是无聊的时候想要打发时间,去放松放松,这个时候难道你还在一张一张的点开链接,去浏览吗?我想在这个数据爆发的时代,这样做是不是有点费时间了,下面我们就来看看一波操作!让你一饱眼福…
导入库
导入一些爬虫需要的第三库,是我们爬虫首先的一步:
from bs4 import BeautifulSoup
import requests
import os
import re
- 1
- 2
- 3
- 4
这些库,以及后面涉及的一些知识点,我在这里就不一一介绍了,后面我会在《初识爬虫之系列篇》,详细的讲解这些基础知识的,本次就是一个实战篇,让大家了解一些东西,实战篇我会在该专栏里面发布,结构化我的文章,这样自己以后也方便查阅。
找到网址
urlHead = 'https://photo.fengniao.com/'
url = 'https://photo.fengniao.com/pic_43591143.html'
- 1
- 2
- 3
请求网址
def getHtmlurl(url): # 获取网址 try: r = requests.get(url) # 解决解析乱码问题 r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
解析并保存
def getpic(html): # 获取图片地址并下载,再返回下一张图片地址 # 指定BeautifulSoup的解析器为:html.parser soup = BeautifulSoup(html, 'html.parser') # all_img = soup.find('div', class_='imgBig').find_all('img') all_img = soup.find('a', class_='downPic') img_url = all_img['href'] reg = r'<h3 class="title overOneTxt">(.*?)</h3>' # r'<a\sclass=".*?"\starget=".*?"\shref=".*?">(.*)</a>' # 正则表达式 reg_ques = re.compile(reg) # 编译一下正则表达式,运行的更快 image_name = reg_ques.findall(html) # 匹配正则表达式 urlNextHtml = soup.find('a', class_='right btn') urlNext = urlHead + urlNextHtml['href'] print('正在下载:' + img_url) root = 'E:\Python实验位置\图片\缓存' path = root + image_name[0] + '.jpg' try: # 创建或判断路径图片是否存在并下载 if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(img_url) with open(path, 'wb') as f: f.write(r.content) f.close() print("图片下载成功") else: print("文件已存在") except: print("爬取失败") return urlNext
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
结构化函数
def main(): html = (getHtmlurl(url)) print(html) return getpic(html)
- 1
- 2
- 3
- 4
主函数
# 主函数
# 下载100图片!!!
if __name__ == '__main__': for i in range(1, 100): url = main()
- 1
- 2
- 3
- 4
- 5
- 6
一般思路
1.请求网址
2.获取网址
3.解析网页
4.保存数据
不要小瞧这些步骤,如果要详细的了解还是需要一些实践的,在现在的爬虫技术里面,有很多需要注意的东西,比如反爬技术,延时,代理,这些都是我们需要了解的,切记不要在网络上随便复制一些代码,自己去运行,这样很有把自己的电脑IP封杀。
下面我们来看看效果如何吧!
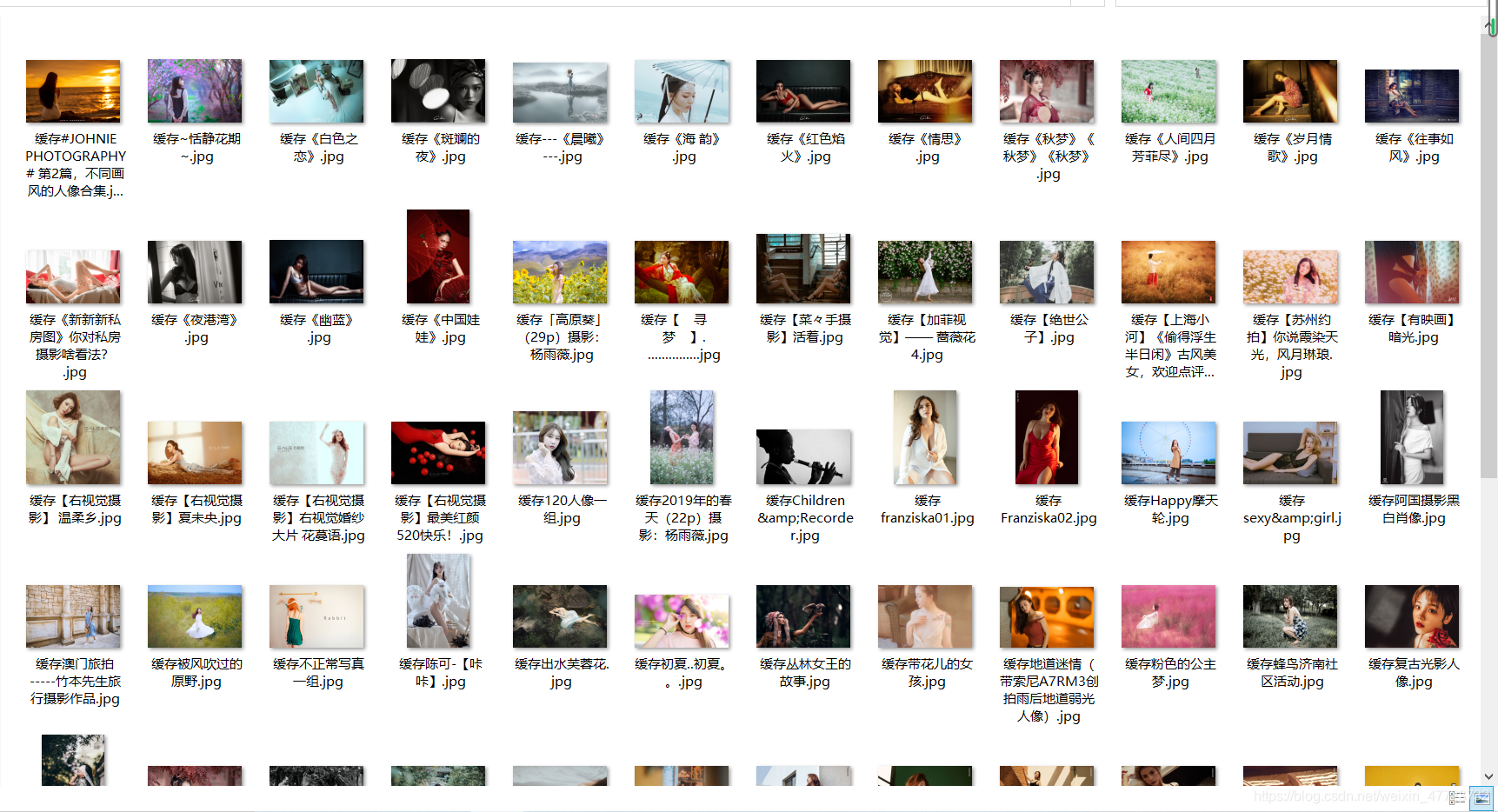
这个代码只要自己去删减一些东西就可以,自己使用了,如果有需要的话,可以留言!

文章来源: wxw-123.blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:wxw-123.blog.csdn.net/article/details/107784060

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)