初识Hadoop之概念认知篇

Hadoop作为大数据的支撑,那么我们会有一些疑问,什么是Hadoop,Hadoop能够做些什么,它的优点是什么,它是如何进行海量数据的操作的。相信这些疑问,一定在此时困扰着你,不要担心,下面我们一步一步的去认识Hadoop这个神奇的的小象!
起源
从1946年开始计算机的诞生,再到如今的2020年人工智能大数据时代,我们的数据一直在呈现级数似的增长,在过去的十几年来看,可能不是特别的明显,但是近几年的数据量,我们称之为海量数据都感觉无法定义它的庞大了。特别是在今年的疫情面前,我们人类,我们中国的大数据的作用,为我们的疫情防控做出来凸出的贡献,相信大家无论是在新闻还是网络上面都是特别的清楚——人工智能——大数据——AI这些新时代下的科技产物,造福者我们每一个人类!
然而在从基础的文件数据开始再到现在的数据仓库,我们的进步无时无刻都在激励着我们一代又一代的IT之人才。2011年5月提出了“大数据”的概念。
大数据的几个特点:
1.数据量大
2.数据类型多
3.处理速度低(1秒定律)
4.价值密度低:比如教室里面的监控器,每一天都在开启,但是真正的发挥作用的时候,也就只有在发现“美好的事物”之后,才会有所价值。
Google的“三驾马车”改变了传统的认知
依靠Google公司的三篇论文,GFS,MapReduce,BigTab,神奇的火花就这样碰撞的产生了,为我们的大数据技术奠定了有力的基础,具有划时代的意义。
GFS思想
分布式文件系统有两个基本的组成部分,一个是客户端,一个是服务端。我们发现服务端的硬盘和安全性不够明显,这个时候我们的GFS就解决了这个问题。
我们会增加一个管理节点,去管理这些存放数据的主机。存放数据的主机我们称之为数据节点,而上传的文件会按照固定的大小进行分块。数据节点上保存的数据块,而非独立的文件。数据块的冗余默认为3.
上传文件时,客户端会首先连接管理节点,管理节点会生成数据块的信息,包括文件名,大小,上传时间,数据块的位置信息等。这些信息成为文件的元数据,它会保存在管理节点。客户端获取了这些元数据之后,就会开始把数据块一个一个的上传。客户端把数据块先上传到第一个数据节点,然后在管理节点的管理下,通过水平复制,复制和分配到其他节点(主机),最终就达到了,冗余度的要求。
数据块
存储在hdfs中的最小单位
默认大小128M
元数据
查看fsimage
整个文件系统命名空间(包括块到文件和文件系统属性的映射)
hdfs oiv -i 要查看的文件名 -o输出的文件名 -p XML
查看edites
文件系统元数据发生的每个更改
hdfs oev -i 要查看的文件名 -o输出的文件名
namenode启动过程
加载fsimage
加载edites
进行检查点保存
等待datanode汇报块信息
datanode启动后
扫描本地块的信息
汇报给namenode
心跳机制
GFS Master与每个服务器通信(保证它是活的),这样就满足了最大化数据的可靠性和可用性
MapReduce思想
主要介绍它的“分而治之”的思想,首先我们介绍一个网页级别,对于多个网页(几亿份),作为一个矩阵的运算已经无法满足了,那么怎么办了,我们就采用对每个小的矩阵块进行计算,之后这样的不断的叠加,最后的运算和汇总结果。其实这个思想比较的具有时代化的超越性,不管是在计算机的运用里面,还是在我们日常的学习和生活中“分散任务,汇总结果”是最实用的。
BigTable思想
igTable 最基本的思想是把所有的数据都存入一张表。BigTable 的思想,利于海量数据的检索,在大数据时代可以显著提高数据的查询效率,但是对数据的新增,修改,删除是不利的。
HDFS
HDFS是Hadoop项目的核心子项目,是分布式计算中的储存管理的基础。
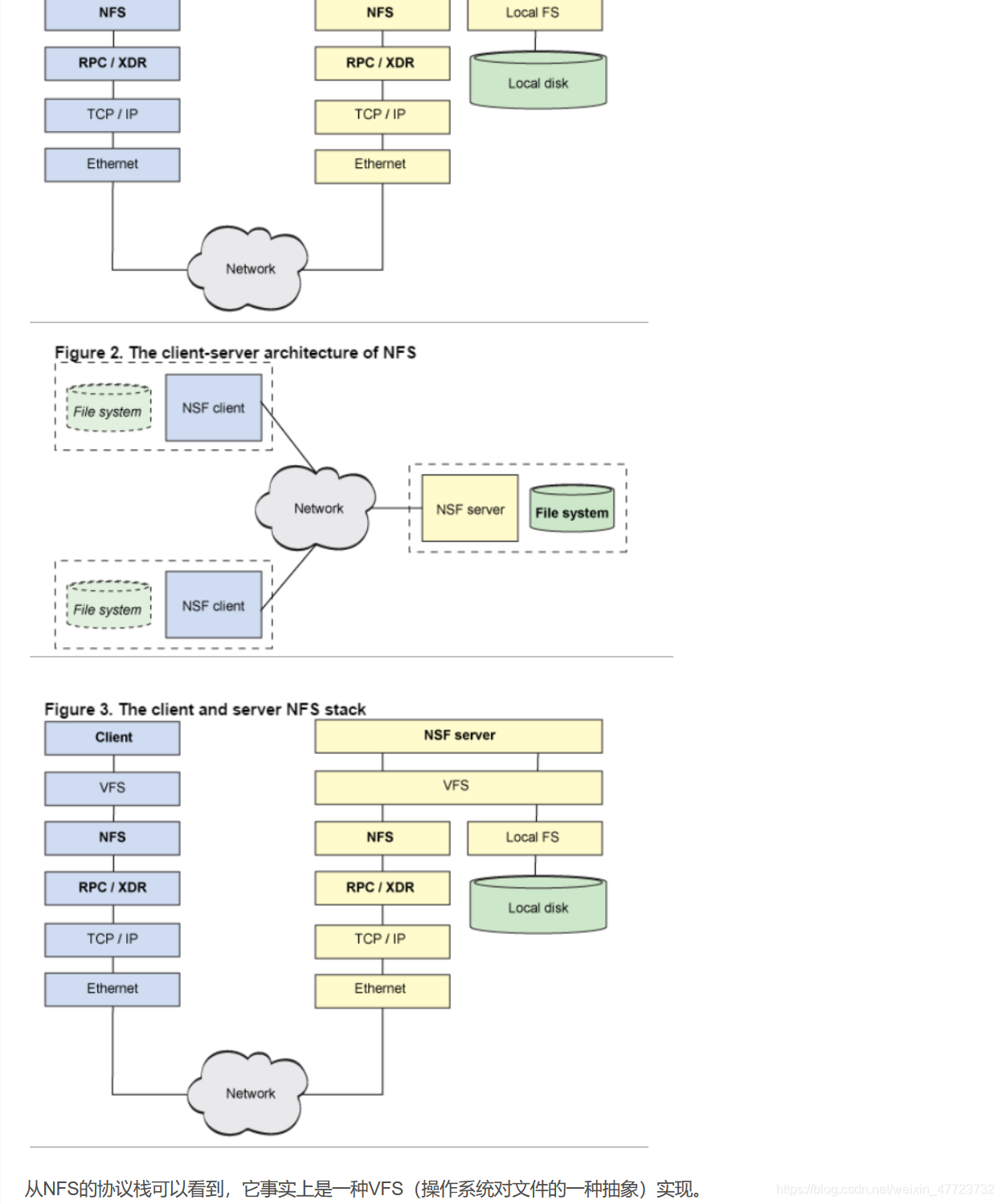
HDFS,是Hadoop Distributed File System的简称,是Hadoop抽象文件系统的一种实现。Hadoop抽象文件系统可以与本地系统、Amazon S3等集成,甚至可以通过Web协议(webhsfs)来操作。HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力。
对于机架感与副本冗余储存策略:比如我们的副本一保存在机架1上,处于安全考虑我们的副本2会和副本一保存在不同的机架上,这里我们保存在机架2上,对于副本三我们应该保存在和副本二一样的机架上面,这个是处于效率的考虑,假设我们的副本二损坏了,那么就近原则从同一个机架的其他主机获取。
Hadoop的特点
1.高可靠性
2.高扩展性
3.高效性
4.高容错性
Hadoop生态圈
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
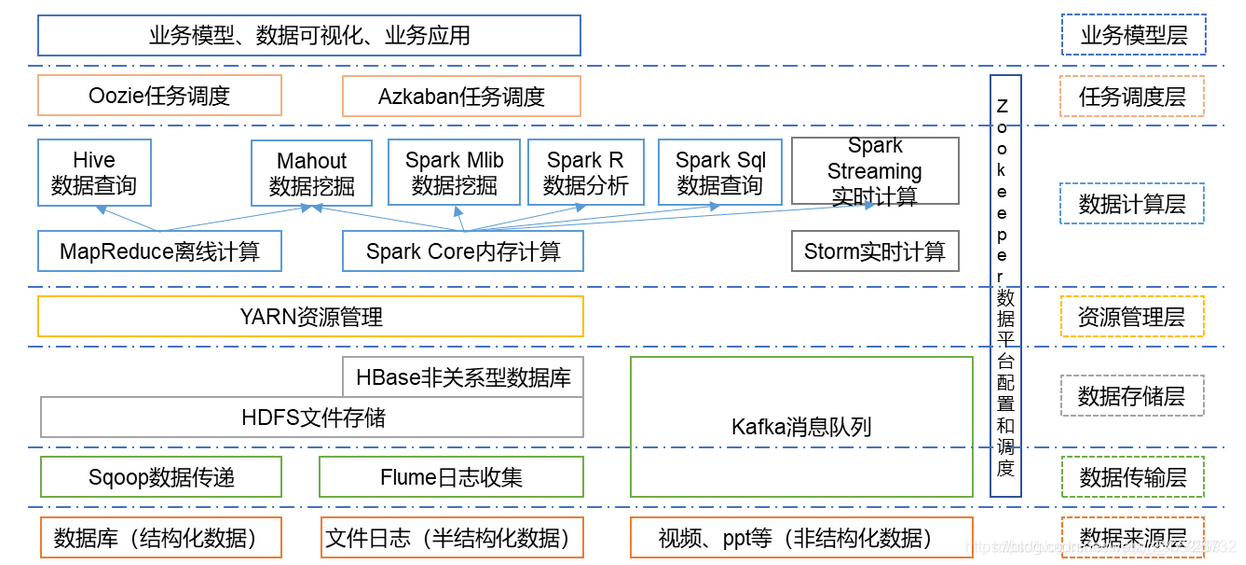
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
Hadoop不适合应用于实时查询的事件
Hadoop的安装和环境搭建配置
HDFS(分布式文件系统)
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
client:切分文件,访问HDFS时,首先与NameNode交互,获取目标文件的位置信息,然后与DataNode交互,读写数据
DataNode:slave节点,存储实际数据,并汇报状态信息给NameNode,默认一个文件会备份3份在不同的DataNode中,实现高可靠性和容错性。
Secondary NameNode:辅助NameNode,实现高可靠性,定期合并fsimage和fsedits,推送给NameNode;紧急情况下辅助和恢复NameNode,但其并非NameNode的热备份。
安装好之后,我们先启动Hadoop
start-all.sh
- 1
等待之后输入
jps
- 1
查看即可,就会出现上面的不同运行机制
HDFS不适合的应用类型
1) 低延时的数据访问
对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时HBase更适合低延时的数据访问。
2)大量小文件
文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
3)多方读写,需要任意的文件修改
HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer)。
这里只是简单的介绍一下Hadoop里面的HDFS,后期我们详细的介绍的。
每文一语
只要选择了开始,就不要停止脚步,沿途的风景再美好,也无法和终点的景色相媲美!
文章来源: wxw-123.blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:wxw-123.blog.csdn.net/article/details/108628704

- 点赞
- 收藏
- 关注作者
评论(0)