法律行业python教程——利用python批量制作律师函

最近在给律师同行准备交流的素材,同时在业务上,也遇到一个课题,A顾问公司是我的客户,经常会集中统计拖欠其货款的公司名单,委托我批量发送律师函进行催款。一次做十几二十份律师函,而且重复工作做的耗时且乏味。该单位业务类型单一,我想是否可以利用一下python工具,制作批量化的律师函,既能提升效率,也为后期的服务减少工作消耗。
废话不多说,直接上干货。
首先电脑里得提前先安装好python3和pycharm,这个前提操作不作赘述。先介绍一下我们这里要用的python库——python-docx,是一个专门操作office docx文档的库,注意是docx文档,不是doc文档,doc文档和docx文档是不一样的,docx文档本质上是一个压缩文件。当然目前office2007和以后的版本都是docx格式,也是目前的通用主流,想必没人电脑里操作文档首选office2003了吧。当然了,我们也可以使用win32com库来进行操作,但是这个库最大的问题是只能运行于windows系统,然而我们好多律师小伙伴也会在mac平台上工作(即使好多购买mac的小伙伴偷偷把系统装回了windows)。
第一步:准备工作:
安装python-docx和lxml库。
在Pycharm中File -> Settings ->Project Interpreter
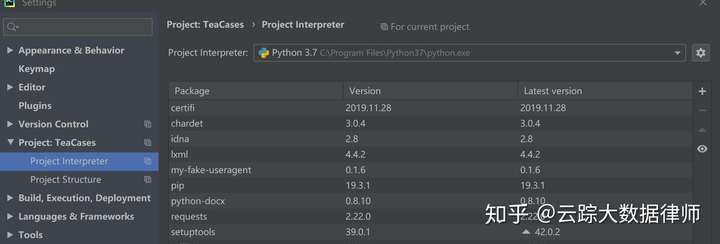 最右边的加号点进去,搜索这两个库安装即可
最右边的加号点进去,搜索这两个库安装即可
第二步:新建py文件,导入库文件
#encoding:utf-8
from docx import Document
from docx.oxml.ns import qn
from docx.shared import Pt
import re #python正则表达式的库第三步:找一份该公司的律师函,作为模板,下标出来的地方,意味着这些部分是每份律师函根据对象不同需要调整的地方。

第四步:将下标部分内容进行替换,替换为特殊字符作为标记,中英文符号都可以(建议不要使用“.()[]\”等特殊字符)。这里我使用的我名字的缩写大写:YYJ。模板文件改好后,我将其另存为命名为“律师函C.docx”。这就是我们后面我们要批量进行复制的父文件。

第五步:编写逻辑代码:
rootPath = r"C:\坚果云\我的坚果云\综合其他\py_project\TeaCases\office\example2\\" #获取父文件所在根目录
file_c = rootPath + '律师函C.docx' #我的模板文件的根目录地址
#A是一个两层嵌套列表,每个子列表,代表的就是要将父文件中"YYJ"替换的内容。
A = [['河南大A环保工程有限公司', '2018年11月', '一', 'SLAH010273', '56000', '2018年8月', '07月29日'],
['江苏小B环保工程有限公司', '2017年10月', '贰', '分别为SLAH0102274、SLAH0102275、SLAH0102276', '76000', '2018年8月', '07月29日'],
['上海大C环保工程有限公司', '2016年9月', '三', 'SBAH0102274', '86000', '2016年12月', '07月29日'],
['北京小D环保工程有限公司', '2015年8月', '肆', 'SCDH0103274', '96500', '2015年8月', '07月29日'],
['四川小E环保工程有限公司', '2014年7月', '五', 'SDG0102375', '47000', '2014年8月', '07月29日'],
['杭州大F环保工程有限公司', '2013年6月', '六', 'SLAH0104276', '123000', '2013年8月', '07月29日'],
['东北小G环保工程有限公司', '2012年5月', '七', 'SLAH0105277', '416000', '2012年8月', '07月29日'],
['云南大L环保工程有限公司', '2011年4月', '八', 'SLAH0106279', '13000', '2011年7月', '07月29日'],
['河北小J环保工程有限公司', '2010年3月', '九', 'SLAH0107280', '46000', '2010年5月', '07月29日'],
['吉林大P环保工程有限公司', '2009年2月', '十', 'SLAH0101290', '12300', '2009年4月', '07月29日'],
['海南小K环保工程有限公司', '2008年1月', '十一', 'SLAH0102130', '421000', '2008年6月', '07月29日'],
]
#循环A列表,item代表A列表中每个元素
for item in A:
document = Document(file_c) #实例化Document对象,获取父文件地址,实例化为document
for x in item: # 遍历子列表中的元素
for y in document.paragraphs: #遍历父文件的每一个段落
check = re.search("YYJ", y.text, flags=re.M) #正则,检查当下段落是否含有“YYJ”
if check is not None:
y.text = y.text.replace('YYJ', x, 1) #如果含有"YYJ",则将“YYJ”替换为当下的子列表元素,只能替换一次
y.style.font.size = Pt(12) #该段落字体设置为12,就是小四的大小
break #跳出本循环
newName=rootPath+"律师函("+item[0]+").docx" #到这里,一份新律师函内容已经修改好了,将其命名
document.styles['Normal'].font.name = '楷体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') #全文设置为楷体
document.save(newName) #以新名字保存作为律师朋友,尤其是没有基础的律师朋友可能会读不懂。其实没有关系,实在读不懂会使用就可以了。如果有了一定的pyhon基础,其实就会觉得非常简单,无法就是调用第三方库的操作而已。python-dox这个库对中文的支持没有英文那么好,所以替换完的时候要设置下字体格式,因为我原文正文部分都是楷体小四。所以每次替换完我都要设置下该段落的字体大小,最后统一下全文的字体为楷体。这里设置全局字体是下面的代码,无需理解其原理,照抄即可。
document.styles['Normal'].font.name = '楷体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '楷体') #全文设置为楷体第六步:跑代码运行
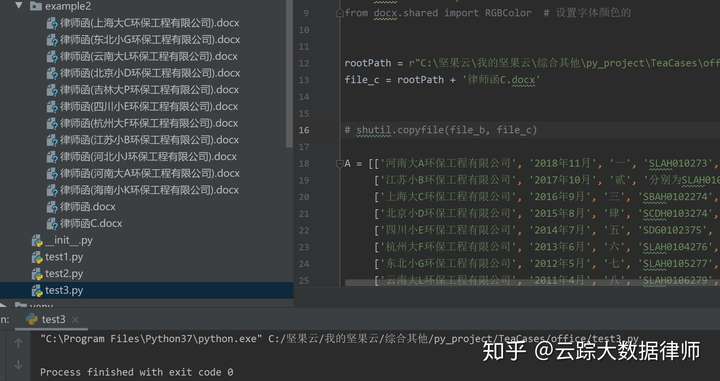
运行成功,打开部分文件检查一下,发现没有错误,工具顺利制作成功。今后该客户再有类似的需求,只需要将A列表改一下,剩下分分钟就搞定了。python就是这样,越是有规律可循,重复度越高的工作,效率提升越明显。是不是工具一次制作,终身使用呢。律师小伙伴们,是不是可以来尝尝鲜呢?
作者原创,非经授权拒绝转载,违者必究。
作者:虞元坚 上海正策律师事务所 律师 全栈网络工程师/法律大数据应用领域专家。擅长领域:争议解决与诉讼、与软件开发和互联网相关的知识产权、不正当竞争、经济犯罪、科技产业投融资等。欢迎关注法律大数据公众号,和律师朋友们都在使用的随身工具——律师云助理。


- 点赞
- 收藏
- 关注作者
评论(0)