ML之FE:对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘

【摘要】 ML之FE:对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
目录
对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
输出结果
实现代码
对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
输出结果
&n...
ML之FE:对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
目录
对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
输出结果
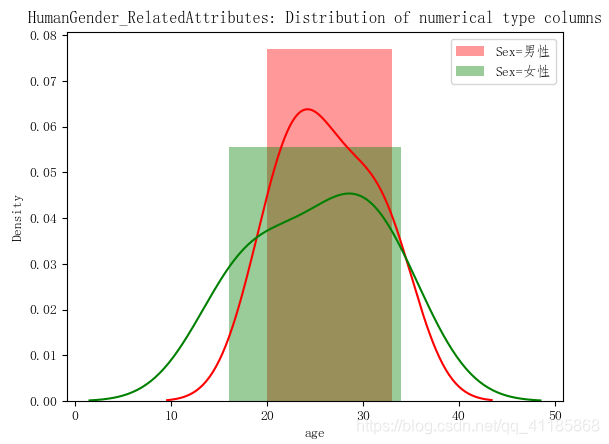
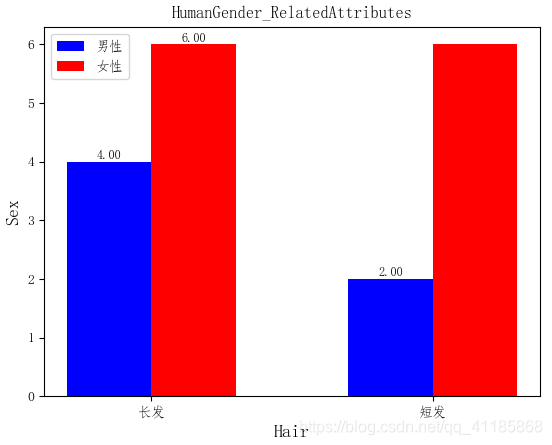
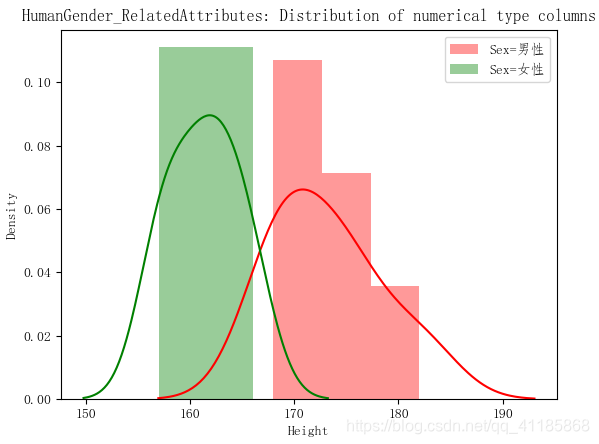
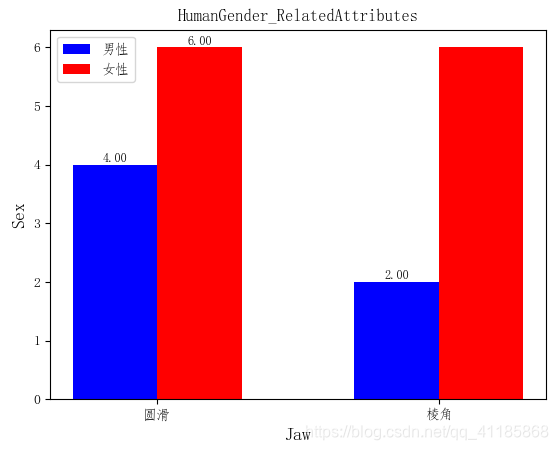
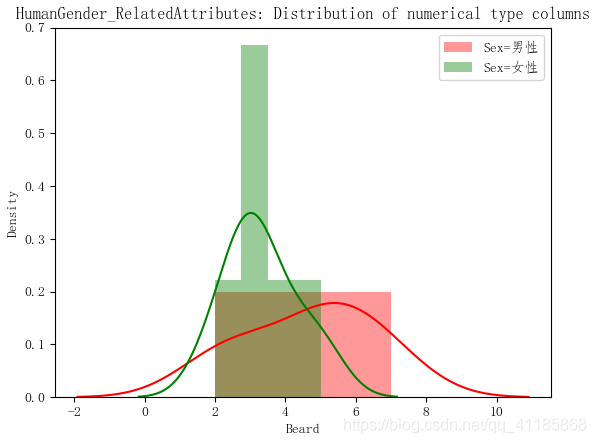
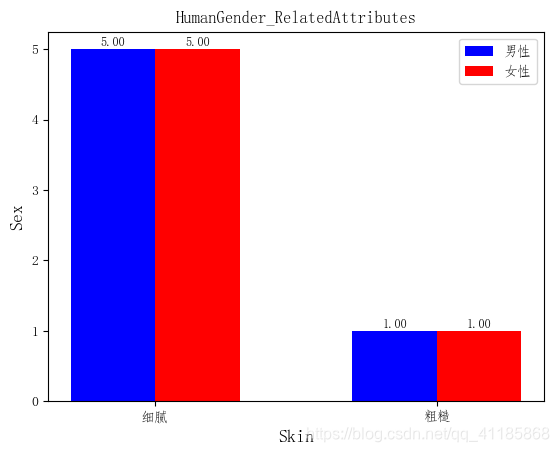
实现代码
-
# coding: utf8
-
import pandas as pd
-
import matplotlib.pyplot as plt
-
-
-
# ML之FE:对人类性别相关属性数据集进行数据特征分布可视化分析与挖掘
-
-
-
#1、定义数据集
-
# 头发(长发/短发)、身高、下巴(棱角/圆滑)、胡长(mm)、皮肤、体重
-
contents={"name": ['Mary', 'Bob', 'Lisa', 'Tom', 'Alan', 'Jason','Sophia', 'Aiden', 'Sarah', 'Miqi', 'Temp01', 'Temp02'],
-
"age": [ 16, 24, 19, 20, 33, 23, 29, 31, 34, 24, 27, 30],
-
"Hair": ['长发', '短发', '长发', '短发', '长发', '短发', '长发', '长发', '长发', '长发', '短发', '长发'],
-
"Height": [158, 175, 162, 170, 175, 168, 166, 169, 164, 157, 182, 161],
-
"Jaw": ['圆滑', '棱角', '圆滑', '棱角', '圆滑', '圆滑', '圆滑', '棱角', '圆滑', '圆滑', '棱角', '圆滑'],
-
"Beard": [2, 7, 3, 5, 2, 3, 5, 6, 3, 4, 5, 3],
-
"Skin": ['细腻', '粗糙', '细腻', '粗糙', '细腻', '粗糙', '细腻', '粗糙', '细腻', '细腻', '粗糙', '粗糙'],
-
"Weight": [99, 143, 105, 135, 120, 160, 95, 145, 125, 112, 155, 100],
-
"Sex": ['女性', '男性', '女性', '男性', '男性', '男性', '女性', '男性', '女性', '女性', '男性', '女性'],
-
}
-
data_frame = pd.DataFrame(contents)
-
print(type(data_frame))
-
-
data_name = 'HumanGender_RelatedAttributes'
-
col_cat='Jaw'
-
label_name='Sex'
-
-
-
for col in data_frame.columns[1:-2]:
-
if data_frame[col].dtypes in ['object']:
-
print(col)
-
# T1、采用函数
-
col_cats=[col,label_name]
-
# SNCountPlot(col_cats,data_frame,imgName='')
-
-
# T2、自定义函数???
-
x_subname = list(data_frame[col].value_counts().to_dict().keys())
-
label_y1 = list(data_frame[label_name].value_counts().to_dict().keys())[0]
-
label_y2 = list(data_frame[label_name].value_counts().to_dict().keys())[1]
-
y1=list(data_frame[data_frame[label_name]==label_y1][col].value_counts().to_dict().values())
-
y2=list(data_frame[data_frame[label_name]==label_y2][col].value_counts().to_dict().values())
-
print(x_subname)
-
print(label_y1,label_y2)
-
print(y1,y2)
-
-
# # T2、自定义函数???
-
# y01Lists,y02Lists=[],[]
-
# for x in x_subname:
-
# if x not in data_frame[data_frame[label_name]==label_y2][col].value_counts(dropna=False).to_dict().keys():
-
# pass
-
# else:
-
#
-
# y01=data_frame[data_frame[label_name]==label_y1][col].value_counts(dropna=False).to_dict()[x]
-
# y02=data_frame[data_frame[label_name]==label_y2][col].value_counts(dropna=False).to_dict()[x]
-
# y01Lists.append(y01)
-
# y02Lists.append(y02)
-
# print(y01Lists,y02Lists)
-
-
-
DoubleBarAddText(y1,y2, col,label_name, x_subname,label_y1,label_y2,data_name)
-
else:
-
Num_col_Plot2_ByLabels(data_name,data_frame,label_name,col)
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/116563364

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)