MySQL-事务+索引

事务*
事务(Transaction)原则:ACID原则:原子性(Atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)
原子大小,目标一致,一入即隔离,持久有力(脏读,幻读。。。)
原子性:针对同一事务。要么都成功,要么都失败。
一致性:事务查找前后状态一致。最终一致性。事务前后的数据完整性要保证一致。
隔离性:针对多个用户同时操作,主要排除其他事务对本次事务的影响,有一个隔离的关系。为每一个用户开启一个事务,事务间互不干扰。
持久性:事务结束后的数据不随外界原因导致数据丢失。事务没有提交就恢复原状,事务提交,按提交之后为准。事务一但提交不可逆,被持久化到数据库中(事务提交)。
**问题:**隔离失败–隔离级别:
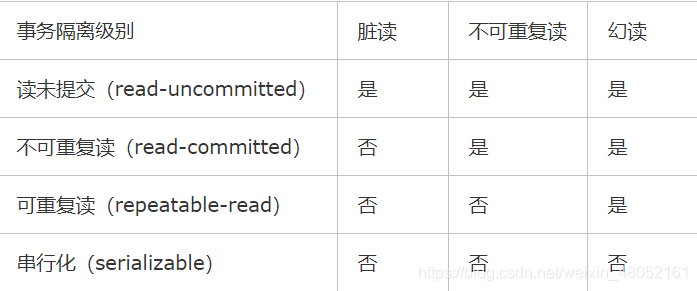
脏读:一个事务读取了另一个事务未提交的数据。数据没提交
不可重复读:一个事务读取数据时,多次读取结果不同。数据变了
虚读(幻读):一个事务内读取到别的事务插入的数据,导致前后读取不一致。多了一行。数据多了
不可重复读都是已有的数据发生改变,幻读是指读入了另一个事务新插入的数据。
Mysql是默认开启事务提交的。
SET autocommit = 0; # 自动提交事务关闭close
SET autocommit = 1; # 自动提交事务开启open(默认default)
# 手动处理
SET autocommit = 0;
# 事务开启
START TRANSACTION # 标记一个事务的开始,从这个之后的sql都在同一个事务内
INSERT xx
INSERT xx
# 提交 持久化(成功success)
COMMIT
# 回滚 回到原来的验证(失败fail)
ROLLBACK
# 事务结束
SET autocommit = 1;
SAVEPOINT 保存点名 # 设置一个事务的保存点save Archive
ROLLBACK TO SAVEPOINT 保存点名 # 回滚到保存点Archive
# commit或者rollback代表事务结束
RELEASE SAVEPOINT 保存点名 #release释放,撤销保存点 delete Archive
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
实践转账
create database[if not exists] shop CHARACTER SET utf8 COLLATE utf8_general_ci; # COLLATE校对字符集
USE shop
CREATE TABLE `accout`(
`id` INT(3) NOT NULL AUTO_INCREMENT, `name` VARCHAR(30) NOT NULL, `money` DECIMAL(9,2) NOT NULL, PRIMARY KEY (`id`)
)Engine=INNODB DEFAULT CHARSET=utf8;
INSERT INTO account(`name`, `money`) VALUES ('A',2000.00),('B',3300.00);
#转账
SET autocommit = 0; #关闭自动提交
START TRANSACTION;# 开启事务
UPDATE account SET money=money-500 WHERE `name` = 'A';
UPDATE account SET money=money+500 WHERE `name` = 'B';
COMMIT; # 提交事务,被持久化了
ROLLBACK; # 回滚没有用了
SET autocommit = 1; #关闭自动提交
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
模拟实现不同隔离级别下产生的一致性相关问题
select @@tx_isolation; # 查看隔离级别
# 更改隔离级别
set [global | session] transaction isolation level read uncommitted; # 其中global是全局会话,session是当前会话
# Read Uncommited,在READ-UNCOMMITED下第二个会话可以查看到第一个会话的未提交的内容
set [global | session] transaction isolation level read committed;
# READ COMMITTED(读已提交),该隔离级别下解决了未提交数据不能查看的问题。在该隔离级别下,如果进行update操作会导致前后查询的结果不一致,即产生脏数据
set [global | session] transaction isolation level REPEATABLE READ;
# REPEATABLE READ(可重复读),解决了脏读的问题。在MySQL的RR级别下也解决了幻读的问题(两次查询的行数不同)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
MySQL的锁机制
1)隔离级别越高,性能越差,这是由于在MySQL中是通过锁机制来解决存在的问题。
2)锁机制:共享锁(读锁 Shared Lock)、排它锁(写锁 Exclusive Lock)、间隙锁(Record Lock)、表锁
按照粒度:行锁(Innodb支持)、表锁
3)串行化的实现
读的时候加共享锁,不能写
写的时候加排他锁,阻塞其它事务的读取和写入
4)读已提交和可重复读
底层采用MVCC(多版本并发控制协议)
5)间隙锁则分为两种:Gap Locks和Next-Key Locks。Gap Locks会锁住两个索引之间的区间,比如select * from User where id>3 and id<5 for update,就会在区间(3,5)之间加上Gap Locks。(解决幻读问题)
6)增删改加排它锁,查询不会加锁
只能通过在select语句后显式加lock in share mode或者for update来加共享锁或者排它锁。
索引
获取数据的数据结构,通过索引可以更快的获取sql里面的结果。
那么为什么mysql索引要用b+树原因如下:
- B+树能显著减少IO次数,提高效率
- B+树的查询效率更加稳定,因为数据放在叶子节点
- B+树能提高范围查询的效率,因为叶子节点指向下一个叶子节点
分类
- 主键索引(PRIMARY KEY)
- 唯一标识,主键不可重复,只能有一个,可以多个列共同组成联合主键,但是不建议联合主键。
- PRIMARY KEY (列名)
- 唯一索引(UNIQUE KEY)
- 避免重复的列出现,唯一索引可以重复,多个列都可以作为标识 唯一索引。一个列(字段)中的避免有重复数据
- UNIQUE KEY 索引名 (列名)
- 常规索引(KEY/INDEX)
- 默认的,index,key关键字设置
- KEY 索引名 (列名)
- 全文索引(FullText)
- 在特定的数据库引擎下采样,MyISAM
- 快速定位数据
# 显示所有索引信息
SHOW INDEX FROM student;
# 添加全文索引
ALTER TABLE school.student ADD FULLTEXT INDEX `studentName`(`studentName`); # 在 school数据库下的student表里面添加全文索引字段
# EXPLAIN 分析sql执行的状况
EXPLAIN SELECT * FROM student; # 非全文索引
SELECT * FROM student WHERE
MATCH(studentName) AGAINST('xx'); # 全文索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
索引添加
# 给表中的字段添加索引
# CREATE INDEX 索引名 on 表(字段)
CREATE INDEX id_app_user_name ON apper_user(`name`); # 给每一个用户插入唯一索引
- 1
- 2
- 3
索引原则
- 索引不是越多越好
- 不要对进程变动数据加索引
- 小数据量的表不需要加索引
- 索引加在常用来查询的字段上
索引数据结构
文章来源: blog.csdn.net,作者:αβγθ,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_38022166/article/details/116708866

- 点赞
- 收藏
- 关注作者
评论(0)