二叉树序列化/反序列化

【摘要】 二叉树被记录成文件的过程,为二叉树的序列化
通过文件重新建立原来的二叉树的过程,为二叉树的反序列化
设计方案并实现。
(已知结点类型为32位整型)
思路:先序遍历实现。
因为要写入文件,我们要把二叉树序列化为一个字符串。
首先,我们要规定,一个结点结束后的标志:“!”
然后就可以通过先序遍历生成先序序列了。
但是,众所周知,只靠...
二叉树被记录成文件的过程,为二叉树的序列化
通过文件重新建立原来的二叉树的过程,为二叉树的反序列化
设计方案并实现。
(已知结点类型为32位整型)
思路:先序遍历实现。
因为要写入文件,我们要把二叉树序列化为一个字符串。
首先,我们要规定,一个结点结束后的标志:“!”
然后就可以通过先序遍历生成先序序列了。
但是,众所周知,只靠先序序列是无法确定一个唯一的二叉树的,原因分析如下:
比如序列1!2!3!
我们知道1是根,但是对于2,可以作为左孩子,也可以作为右孩子:
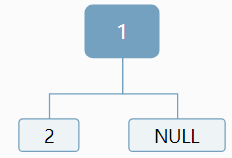
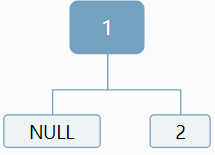
对于3,我们仍然无法确定,应该作为左孩子还是右孩子,情况显得更加复杂:
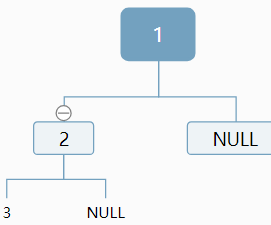
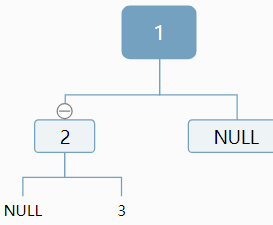

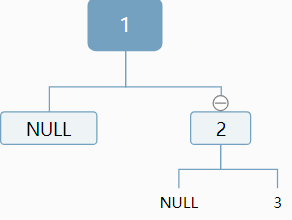
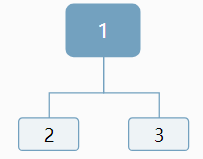
原因:我们对于当前结点,插入新结点是无法判断插入位置,是应该作为左孩子,还是作为右孩子。
因为我们的NULL并未表示出来。
如果我们把NULL也用一个符号表示出来:
比如
1!2!#!#!3!#!#!
我们再按照先序遍历的顺序重建:
对于1,插入2时,就确定要作为左孩子,因为左孩子不为空。
然后接下来两个#,我们就知道了2的左右孩子为空,然后重建1的右子树即可。
我们定义结点:
-
public static class Node {
-
public int value;
-
public Node left;
-
public Node right;
-
-
public Node(int data) {
-
this.value = data;
-
}
-
}
序列化:
-
public static String serialByPre(Node head) {
-
if (head == null) {
-
return "#!";
-
}
-
String res = head.value + "!";
-
res += serialByPre(head.left);
-
res += serialByPre(head.right);
-
return res;
-
}
-
public static Node reconByPreString(String preStr) {
-
//先把字符串转化为结点序列
-
String[] values = preStr.split("!");
-
Queue<String> queue = new LinkedList<String>();
-
for (int i = 0; i != values.length; i++) {
-
queue.offer(values[i]);
-
}
-
return reconPreOrder(queue);
-
}
-
-
public static Node reconPreOrder(Queue<String> queue) {
-
String value = queue.poll();
-
if (value.equals("#")) {
-
return null;//遇空
-
}
-
Node head = new Node(Integer.valueOf(value));
-
head.left = reconPreOrder(queue);
-
head.right = reconPreOrder(queue);
-
return head;
-
}
这样并未改变先序遍历的时空复杂度,解决了先序序列确定唯一一颗树的问题,实现了二叉树序列化和反序列化。
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/84553147

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)