redis——NOSQL及redis概述

NoSql入门概述
单机Mysql的美好时代
瓶颈:
-
- 数据库总大小一台机器硬盘内存放不下
- 数据的索引(B + tree)一个机器的运行内存放不下
- 访问量(读写混合)一个实例不能承受
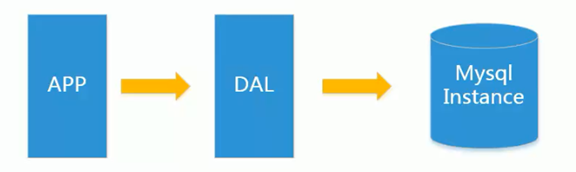
Memcached(缓存)+ MySql + 垂直拆分
通过缓存来缓解数据库的压力,优化数据库的结构和索引
垂直拆分指的是:分成多个数据库存储数据(如:卖家库与买家库)
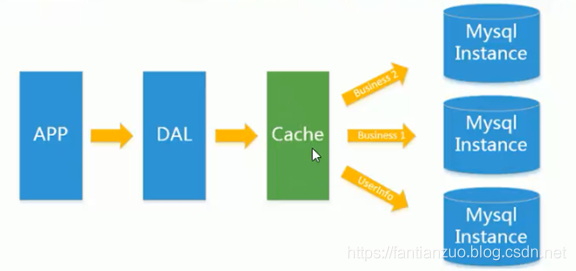
MySql主从复制读写分离
- 主从复制:主库来一条数据,从库立刻插入一条。
- 读写分离:读取(从库Master),写(主库Slave)
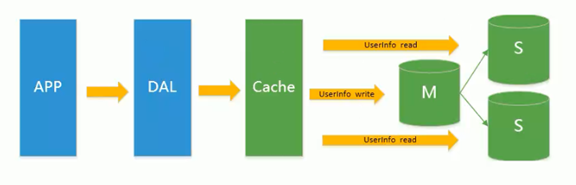
分表分库+水平拆分+MySql集群
- 主库的写压力出现瓶颈(行锁InnoDB取代表锁MyISAM)
- 分库:根据业务相关紧耦合在同一个库,对不同的数据读写进行分库(如注册信息等不常改动的冷库与购物信息等热门库分开)
- 分表:切割表数据(例如90W条数据,id 1-30W的放在A库,30W-60W的放在B库,60W-90W的放在C库)
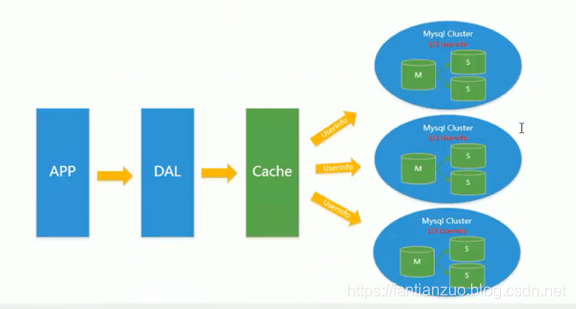
MySql扩展的瓶颈
- 大数据下IO压力大
- 表结构更改困难
常用的Nosql
Redis
memcache
Mongdb
以上几种Nosql 请到各自的官网上下载并参考使用
Nosql 的核心功能点
KV(存储)
Cache(缓存)
Persistence(持久化)
……
大数据时代的3V
海量Volume
多样Variety
实时Velocity
互联网需求的3高
高并发
高可扩
高性能
redis的介绍和特点:
问题:
传统数据库:持久化存储数据。
solr索引库:大量的数据的检索。
在实际开发中,高并发环境下,不同的用户会需要相同的数据。因为每次请求,
在后台我们都会创建一个线程来处理,这样造成,同样的数据从数据库中查询了N次。
而数据库的查询本身是IO操作,效率低,频率高也不好。
总而言之,一个网站总归是有大量的数据是用户共享的,但是如果每个用户都去数据库查询
效率就太低了。
解决:
将用户共享数据缓存到服务器的内存中。
实现:
redis
概念:
redis是一个非关系型C语言开发的基于键值对的数据库
特点:
1、基于键值对
2、非关系型(redis)
关系型数据库:存储了数据以及数据之间的关系,oracle,mysql
非关系型数据库:存储了数据,redis,mdb.
3、数据存储在内存中,服务器关闭后,持久化到硬盘中
4、支持主从同步
总结:
实现了缓存数据和项目的解耦。
数据类型:
String
list
set
sortedset
hash
redis存储的数据特点:
大量数据
用户共享数据
数据不经常修改。
查询数据
redis的应用场景:
网站高并发的主页数据
网站数据的排名
消息订阅
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/102526465

- 点赞
- 收藏
- 关注作者
评论(0)