何为布隆过滤器

问题的提出
我们有一个不安全网页的黑名单,包含了100亿个黑名单网页的URL,每个网页URL最多占用64B.。
现在我们要设计一个网页过滤系统,这个系统要判断该网页是否在黑名单里,但是我们的空间有限,只有30GB.
允许有万分之一的判断失误
布隆过滤器
我们可以把所有的URL保存起来,比如放到hashmap里,但是64B*100亿=640GB,不符合要求。
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果遇到网页黑名单系统、垃圾邮件过滤、爬虫网址判重等问题,如果可以容忍一定程度的失误率,那么我们就可以用布隆过滤器来解决。
哈希函数
我们先来认识一下哈希函数(或者说是复习)
1)
哈希函数的输入可以认为是无穷大或者是非常大的范围,比如任意一个整数(字符串),而输出域是有范围的
(这就意味着不同的输入可能是相同的输出)
2)
当输入相同的值时,返回值也相同(确定性)
3)
所有不同的输入值得到的输出,均匀地分布在输出域内,并且与输入值出现的规律无关。(这也是评价一个哈希函数是否优秀的两个重要标准)比如:1和2相差很近,但是经过优秀的哈希函数计算后,他们应该差距较大。
4)
速度快:可以认为哈希函数的计算时间是O(1)的。
布隆过滤器输入
下面就开始介绍布隆过滤器啦。
1)
我们准备k个哈希函数,并且他们之间没有什么关系,彼此独立。
那么对于同一个输入对象(你想的没错就是一个URL),经过计算出来的结果也是完全独立的没有规律的。
2)
我们准备一个数组,长度为m,只有两种状态,所以我们选用bit数组名为bitmap。
3)
我们输入一个黑名单里的URL时:把URL用每一个哈希函数计算出来,结果%数组长度(目的是能存下呀。。。。。),把对应位置的bit变为1,记录下来。
处理完所有URL,我们的布隆过滤器就准备好啦。
布隆过滤器检查
我们如何用布隆过滤器检查某个URL是否是黑名单中的呢?
同样的方法,把这个值用k个哈希函数算出结果,每一个结果都去bitmap里找有没有存在过,只要有一个结果不存在,那这个URL就肯定不是黑名单了。(因为之前用同样的方法,bitmap变为1的那些位置和现在应该是一样的)
接下来就是比较佛性的事了,既然有一个答案不存在,这个URL就不是黑名单里的,那。。。所有答案都存在,就能确定它在黑名单里吗?
不是的。
因为可能是其它URL算出的答案恰好把本URL的答案全都算出来过。
想到这就不禁要问了:那这个数据结构有啥用?不是坑爹呢?
其实是有用的,他的失误率是很低很低的。
他的原则就是:“宁可错杀三千,不可放过一个”
如何设计空间和哈希函数
首先我们应该想到:数组太小的话肯定是不准确的,比如:

就这么小个数组,存了几个URL,十个地方全算出来过,全成1了。
那后面判断的时候就比较坑了,随便来什么URL,随便什么哈希函数,算出的答案全都出现过,这显然不是我们想要的。
所以,我们应该知道,数组过小会影响准确性。
那么我们如何根据数据量来设计数组大小和哈希函数个数呢?
以本题为例:
样本数:100亿
失误率:不超过0.01%,记为p
每个样本大小:64B(这个其实不影响布隆过滤器大小,因为这是和哈希函数有关的,一般的哈希函数都能接受64B的数据,并且输出,bitmap只需记录答案是否出现过即可)
布隆过滤器大小m由以下公式决定:

根据公式算出m=19.19n,向上取整20,所以需要2000亿bit=25GB
哈希函数的个数由以下公式决定:
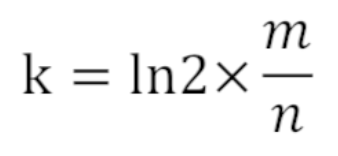
k=14
布隆过滤器的失误率为:

计算出为0.006%,符合要求,此题可解。
公式分析





白名单
过滤器会用错误,对已经发现的错误样本可以建立白名单防止错误。
其他使用场景
- 网页爬虫对URL的去重,避免爬去相同的URL地址
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是杀垃圾邮箱
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/92177826

- 点赞
- 收藏
- 关注作者
评论(0)