redis——HyperLogLog

HyperLogLog 是一种概率数据结构,用来估算数据的基数。数据集可以是网站访客的 IP 地址,E-mail 邮箱或者用户 ID。
基数就是指一个集合中不同值的数目,比如 a, b, c, d 的基数就是 4,a, b, c, d, a 的基数还是 4。虽然 a 出现两次,只会被计算一次。
使用 Redis 统计集合的基数一般有三种方法,分别是使用 Redis 的 HashMap,BitMap 和 HyperLogLog。前两个数据结构在集合的数量级增长时,所消耗的内存会大大增加,但是 HyperLogLog 则不会。
Redis 的 HyperLogLog 通过牺牲准确率来减少内存空间的消耗,只需要12K内存,在标准误差0.81%的前提下,能够统计2^64个数据。所以 HyperLogLog 是否适合在比如统计日活月活此类的对精度要不不高的场景。
这是一个很惊人的结果,以如此小的内存来记录如此大数量级的数据基数。下面我们就带大家来深入了解一下 HyperLogLog 的使用,基础原理,源码实现和具体的试验数据分析。
HyperLogLog 在 Redis 中的使用
Redis 提供了 PFADD 、 PFCOUNT 和 PFMERGE 三个命令来供用户使用 HyperLogLog。
PFADD 用于向 HyperLogLog 添加元素。
-
> PFADD visitors alice bob carol
-
-
(integer) 1
-
-
> PFCOUNT visitors
-
-
(integer) 3
如果 HyperLogLog 估计的近似基数在 PFADD 命令执行之后出现了变化, 那么命令返回 1 , 否则返回 0 。 如果命令执行时给定的键不存在, 那么程序将先创建一个空的 HyperLogLog 结构, 然后再执行命令。
PFCOUNT 命令会给出 HyperLogLog 包含的近似基数。在计算出基数后, PFCOUNT 会将值存储在 HyperLogLog 中进行缓存,知道下次 PFADD 执行成功前,就都不需要再次进行基数的计算。
PFMERGE 将多个 HyperLogLog 合并为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的并集基数。
-
> PFADD customers alice dan
-
-
(integer) 1
-
-
> PFMERGE everyone visitors customers
-
-
OK
-
-
> PFCOUNT everyone
-
-
(integer) 4
内存消耗对比实验
我们下面就来通过实验真实对比一下下面三种数据结构的内存消耗,HashMap、BitMap 和 HyperLogLog。
我们首先使用 Lua 脚本向 Redis 对应的数据结构中插入一定数量的数,然后执行 bgsave 命令,最后使用 redis-rdb-tools 的 rdb 的命令查看各个键所占的内存大小。
下面是 Lua 的脚本
-
local key = KEYS[1]
-
-
local size = tonumber(ARGV[1])
-
-
local method = tonumber(ARGV[2])
-
-
-
-
for i=1,size,1 do
-
-
if (method == 0)
-
-
then
-
-
redis.call('hset',key,i,1)
-
-
elseif (method == 1)
-
-
then
-
-
redis.call('pfadd',key, i)
-
-
else
-
-
redis.call('setbit', key, i, 1)
-
-
end
-
-
end
我们在通过 redis-cli 的 script load 命令将 Lua 脚本加载到 Redis 中,然后使用 evalsha 命令分别向 HashMap、HyperLogLog 和 BitMap 三种数据结构中插入了一千万个数,然后使用 rdb 命令查看各个结构内存消耗。
我们进行了两轮实验,分别插入一万数字和一千万数字,三种数据结构消耗的内存统计如下所示。
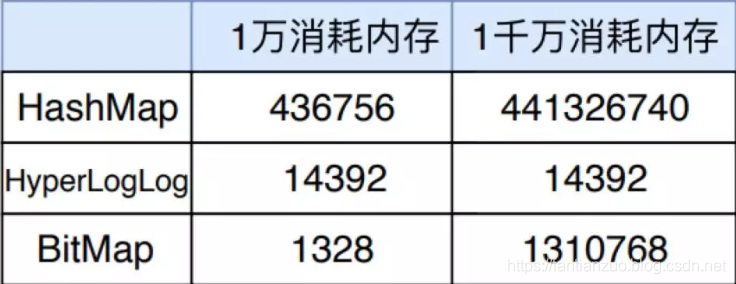
从表中可以明显看出,一万数量级时 BitMap 消耗内存最小, 一千万数量级时 HyperLogLog 消耗内存最小,但是总体来看,HyperLogLog 消耗的内存都是 14392 字节,可见 HyperLogLog 在内存消耗方面有自己的独到之处。
基本原理
HyperLogLog 是一种概率数据结构,它使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程。
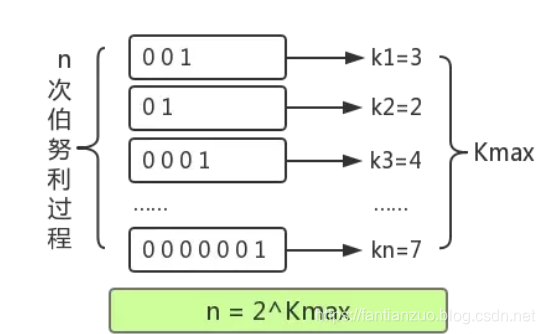
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
对于 n 次伯努利过程,我们会得到 n 个出现正面的投掷次数值 k1, k2 ... kn , 其中这里的最大值是k_max。
根据一顿数学推导,我们可以得出一个结论: 2^{k_ max} 来作为n的估计值。也就是说你可以根据最大投掷次数近似的推算出进行了几次伯努利过程。
下面,我们就来讲解一下 HyperLogLog 是如何模拟伯努利过程,并最终统计集合基数的。
HyperLogLog 在添加元素时,会通过Hash函数,将元素转为64位比特串,例如输入5,便转为101(省略前面的0,下同)。这些比特串就类似于一次抛硬币的伯努利过程。比特串中,0 代表了抛硬币落地是反面,1 代表抛硬币落地是正面,如果一个数据最终被转化了 10010000,那么从低位往高位看,我们可以认为,这串比特串可以代表一次伯努利过程,首次出现 1 的位数为5,就是抛了5次才出现正面。
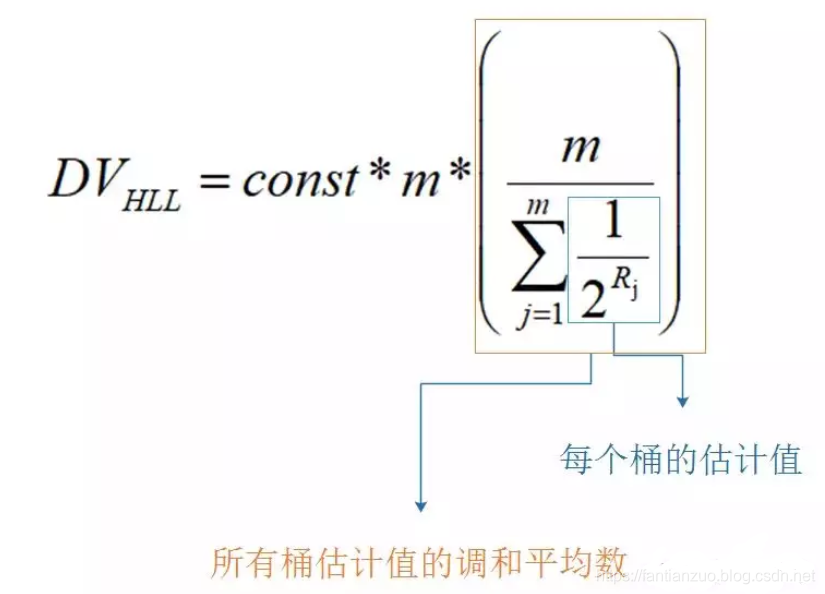
所以 HyperLogLog 的基本思想是利用集合中数字的比特串第一个 1 出现位置的最大值来预估整体基数,但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog中引入分桶平均的概念,计算 m 个桶的调和平均值。
Redis 中 HyperLogLog 一共分了 2^14 个桶,也就是 16384 个桶。每个桶中是一个 6 bit 的数组。
HyperLogLog 将上文所说的 64 位比特串的低 14 位单独拿出,它的值就对应桶的序号,然后将剩下 50 位中第一次出现 1 的位置值设置到桶中。50位中出现1的位置值最大为50,所以每个桶中的 6 位数组正好可以表示该值。
在设置前,要设置进桶的值是否大于桶中的旧值,如果大于才进行设置,否则不进行设置。
此时为了性能考虑,是不会去统计当前的基数的,而是将 HyperLogLog 头的 card 属性中的标志位置为 1,表示下次进行 pfcount 操作的时候,当前的缓存值已经失效了,需要重新统计缓存值。在后面 pfcount 流程的时候,发现这个标记为失效,就会去重新统计新的基数,放入基数缓存。
在计算近似基数时,就分别计算每个桶中的值,带入到上文的 DV 公式中,进行调和平均和结果修正,就能得到估算的基数值。
HyperLogLog 具体对象
我们首先来看一下 HyperLogLog 对象的定义
-
struct hllhdr {
-
-
char magic[4]; /* 魔法值 "HYLL" */
-
-
uint8_t encoding; /* 密集结构或者稀疏结构 HLL_DENSE or HLL_SPARSE. */
-
-
uint8_t notused[3]; /* 保留位, 全为0. */
-
-
uint8_t card[8]; /* 基数大小的缓存 */
-
-
uint8_t registers[]; /* 数据字节数组 */
-
-
};
HyperLogLog 对象中的 registers 数组就是桶,它有两种存储结构,分别为密集存储结构和稀疏存储结构,两种结构只涉及存储和桶的表现形式,从中我们可以看到 Redis 对节省内存极致地追求。
我们先看相对简单的密集存储结构,它也是十分的简单明了,既然要有 2^14 个 6 bit的桶,那么我就真使用足够多的 uint8_t 字节去表示,只是此时会涉及到字节位置和桶的转换,因为字节有 8 位,而桶只需要 6 位。
所以我们需要将桶的序号转换成对应的字节偏移量 offsetbytes 和其内部的位数偏移量 offsetbits。需要注意的是小端字节序,高位在右侧,需要进行倒转。
当 offset_bits 小于等于2时,说明一个桶就在该字节内,只需要进行倒转就能得到桶的值。
offset_bits 大于 2 ,则说明一个桶分布在两个字节内,此时需要将两个字节的内容都进行倒置,然后再进行拼接得到桶的值。
Redis 为了方便表达稀疏存储,它将上面三种字节表示形式分别赋予了一条指令。
-
ZERO : 一字节,表示连续多少个桶计数为0,前两位为标志00,后6位表示有多少个桶,最大为64。
-
XZERO : 两个字节,表示连续多少个桶计数为0,前两位为标志01,后14位表示有多少个桶,最大为16384。
-
VAL : 一字节,表示连续多少个桶的计数为多少,前一位为标志1,四位表示连桶内计数,所以最大表示桶的计数为32。后两位表示连续多少个桶。
Redis从稀疏存储转换到密集存储的条件是:
-
任意一个计数值从 32 变成 33,因为 VAL 指令已经无法容纳,它能表示的计数值最大为 32
-
稀疏存储占用的总字节数超过 3000 字节,这个阈值可以通过 hllsparsemax_bytes 参数进行调整。
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/102552599

- 点赞
- 收藏
- 关注作者
评论(0)