初识爬虫之基本原理篇

在写爬虫之前,我们还需要了解一些基础知识,如 HTTP 原理、网页的基础知识、爬虫的基本原理 、 Cookies 的基本原理等。
HTTP基本原理
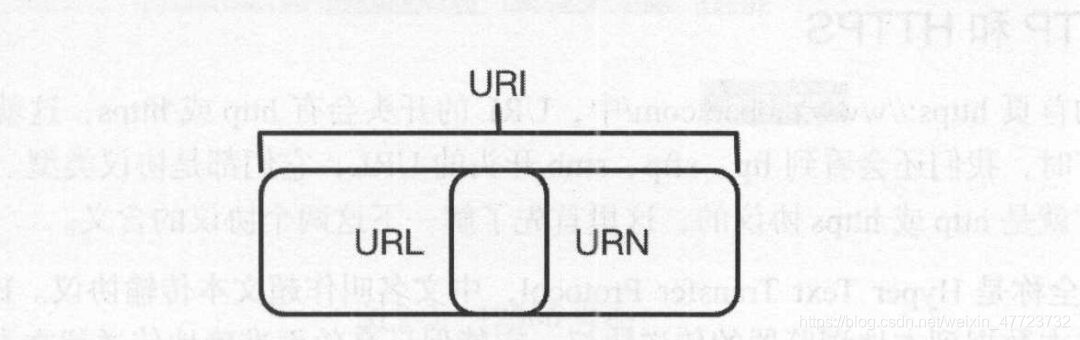 一个网站的图标链接,它就是一个URL,也可以叫URI,但是我个人习惯于URL,而且在互联网中URL也是比较常见的。
一个网站的图标链接,它就是一个URL,也可以叫URI,但是我个人习惯于URL,而且在互联网中URL也是比较常见的。
超文本
我们在浏览器里看到的网页就是超文本解析而成的, 其网页源代码是一系列 HTML 代码, 里面包含了一系列标签,在网页里面的HTML就是可以被称之为超文本。例如我们在谷歌浏览器,打开开发者工具,看到的就是一些源码,这些源代码就是超文本。
HTTP和HTTPS
HTTPS被称之为安全通道,也就是HTTP的一个安全升级。这个我们在自己也可以看到。感兴趣的可以点击了解
HTTP请求过程
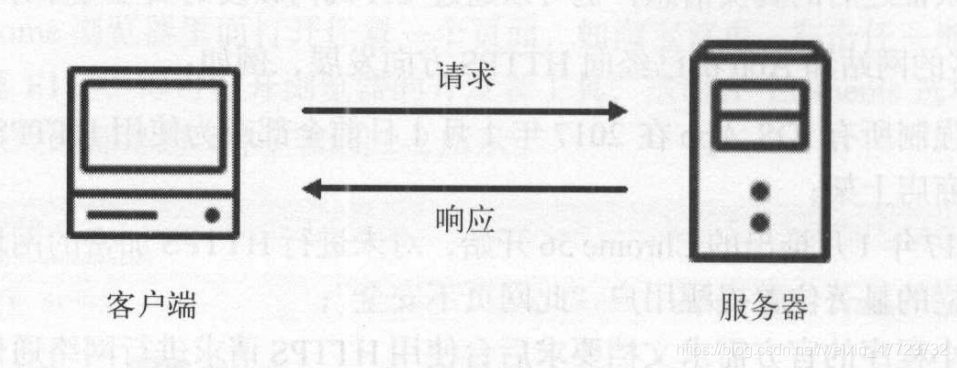
我们在浏览器中输入一个 URL ,回车之后便会在浏览器中观察到页面内容 实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。 响应里包含了页面的源代码等内容,浏览器再对其进行解析便将网页呈现了出来。
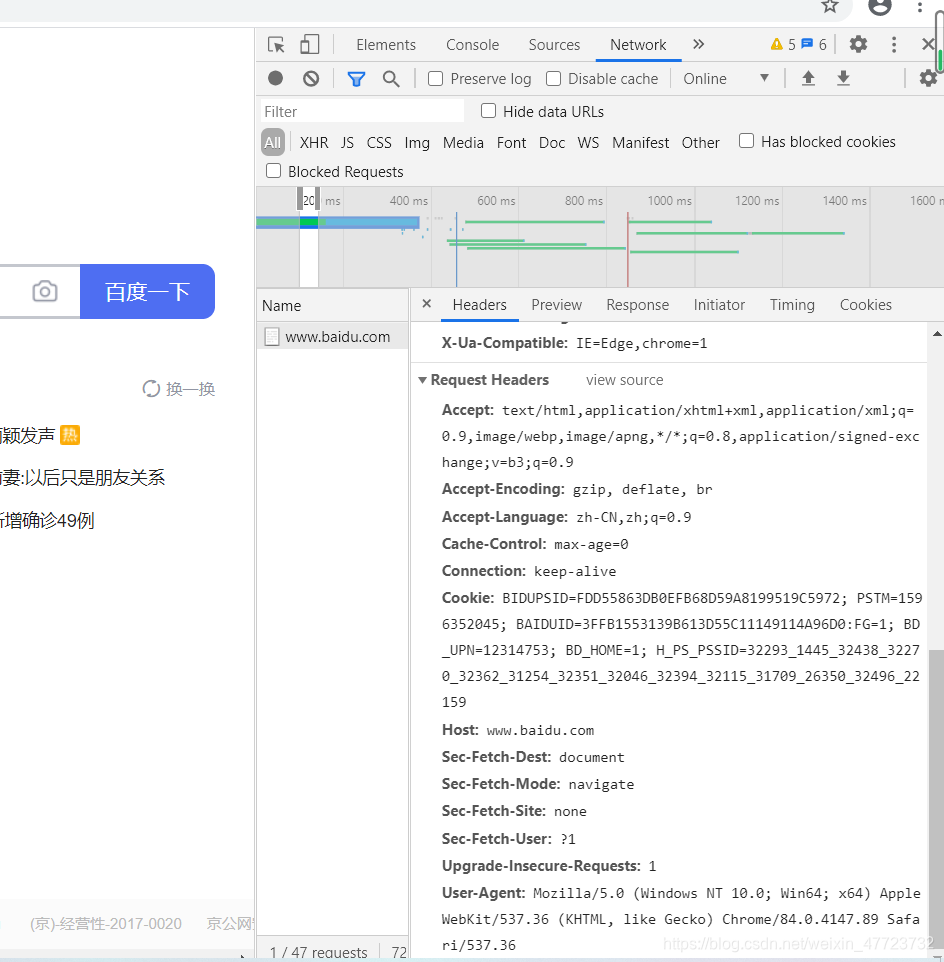
学会看懂网页的一些元素也是很重要的,比如一些请求头信息,响应头信息,这些都是我们在网络爬取过程必须要走过的路。
请求
1.请求方法

请求头
请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie 、 Referer 、 User-Agent 等 ,下面简要说明一些常用的头信息 。
Cookie :也常用复数形式 Cookies ,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据 。 它的主要功能是维持当前访问会话 。 例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功劳 。 Cookies 里有信息标识了我们所对应的服务器
的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容 。
Referer :此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等 。
User-Agent :简称 UA ,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本 、 浏览器及版本等信息 。 在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别州为爬虫 。
一般在进行爬虫的时候,我们都需要加入请求头,不然就会被识别为爬虫,其中最为重要的就是user-agent
响应
响应状态码表示服务器的响应状态,如 200 代表服务器正常响应, 404 代表页面未找到, 500 代表服务器内部发生错误。 在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为 200 ,则证明成功返回数据 , 再进行进一步的处理,否则直接忽略。


最重要的当属响应体的内容了 。 响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的 HTML 代码 ; 请求一张图片时 , 它的响应体就是图片的二进制数据 。 我们做爬虫请求网页后,要解析的 内容就是响应体 ,在浏览器开发者工具中点击 Preview ,就可以看到网页的源代码 , 也就是响应体的内容,它是解析的目标。
网页基础
网页可以分为三大部分一一HTML , CSS 和 JavaScript。 如果把网页 比作一个人的话 , HTML 相当于骨架, JavaScript 相当于肌肉 , css 相当于皮肤,三者结合起来才能形成一个完善的网页 。
HTML
在HTML中图片用 img 标签表示, 视频用 video 标签表示 ,段落用 p 标签表示 ,它们之间的布局又常通过布局标签 div 嵌套组合而戚 ,各种标签通过不同的排列和嵌套才形成了 网页的框架。
CSS
css 是目前唯一的网页页面排版样式标准,HTML 定义了网页的结构,但是只有 HTML 页面的布局并不美观,可能只是简单的节点元素的排列,为了让网页看起来更好看一些,这里借助了 css 。
JavaScript
JavaScript ,简称 JS , 是一种脚本语言 。 HTML 和 css 配合使用, 提供给用户的只是一种静态信息,缺乏交互性。 我们在网页里可能会看到一些交互和动画效果,如下载进度条、提示框 、 轮播图等 ,这通常就是JavaScript 的功劳。 它的出现使得用户与信息之间不只是一种浏览与显示的关系,而是实现了一种实时、动态、交互的页面功能 。
节树点
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
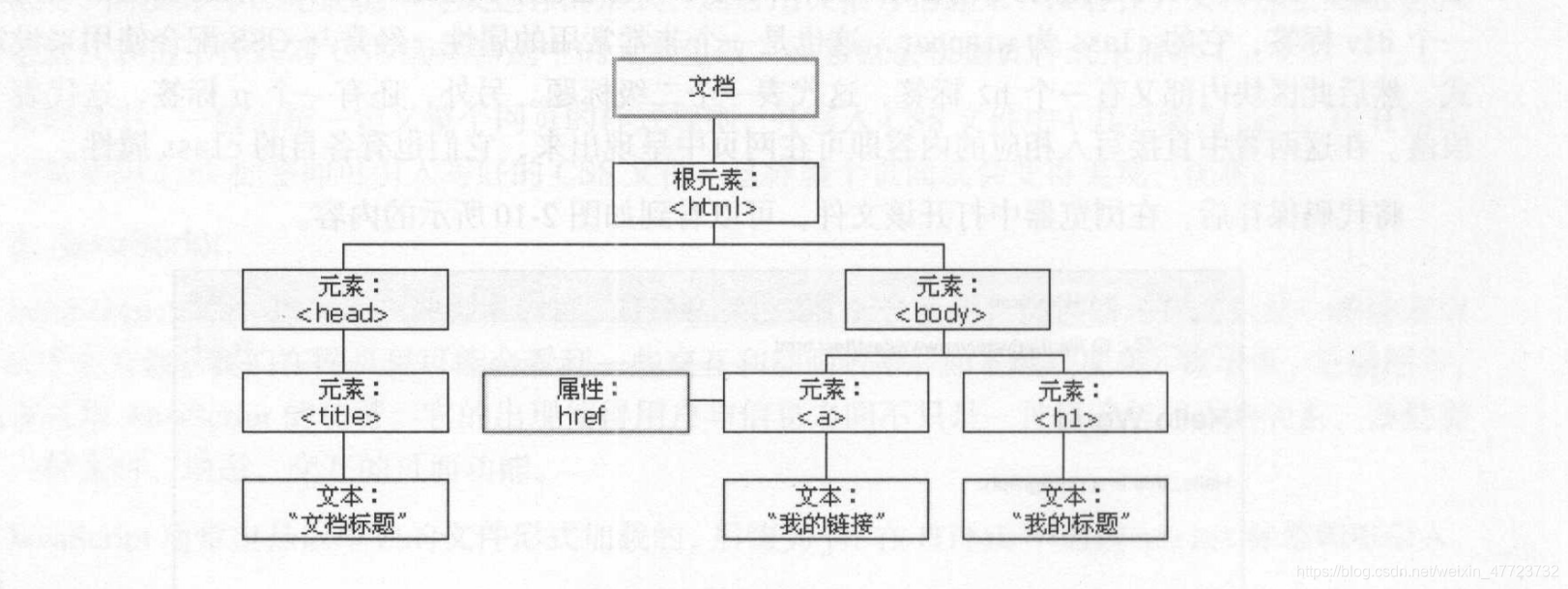
节树点与节点的关系
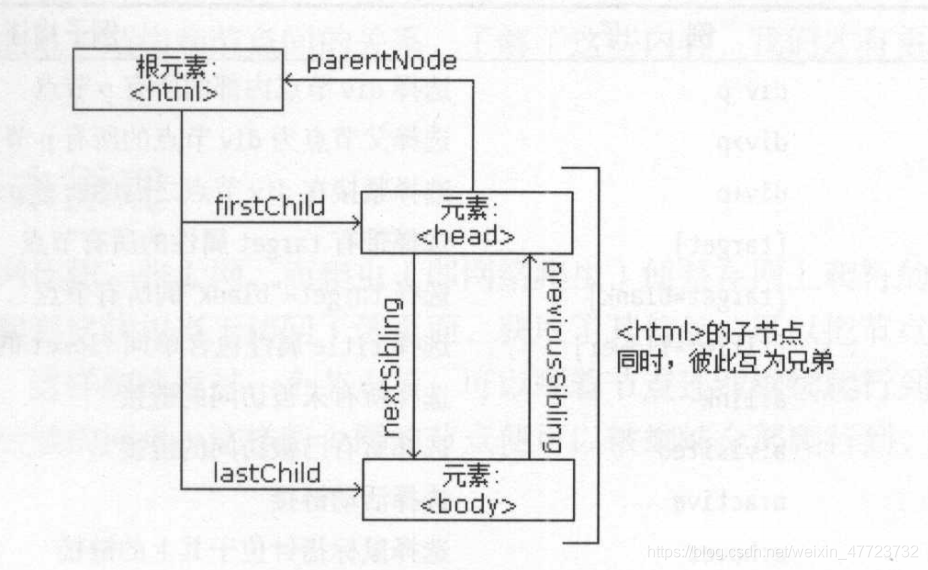 选择器
选择器
在 css 中,我们使用 css 选择器来定位节点 。 例如,上例中 div 节点的 id 为 container ,那么就可以表示为#container ,其中#开头代表选择 id ,其后紧跟 id 的名称。 另外,如果我们想选择 class为 wrapper 的节点 ,便可以使用 .wrapper ,这里以点(.)开头代表选择 class ,其后紧跟 class 的名称 。另外,还有一种选择方式,那就是根据标签名筛选,例如想选择二级标题 ,直接用 h2 即可 。 这是最常用的 3 种表示,分别是根据id 、 class 、标签名筛选


在进行Python爬虫筛选的时候,我们有CSS,Xpath,还有正则表达式进行筛选我们需要的,比较简单的是正则表达式,但是它比较繁琐,稍不注意就会出现差错,其实最好用的还是Xpath。后期文章我们会介绍的!
文章来源: blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_47723732/article/details/107906599

- 点赞
- 收藏
- 关注作者
评论(0)