初识Mongdb之概念认知篇

目录
Mongdb
什么是mongdb?
mongodb 是一个文档型数据库 也就是非关系型(nosql),同时MongoDB也是一款为web应用程序和互联网基础设施设计的数据库管理系统。
它是由c++语言编写的,在大数据的背景时代下,我们的数据过于的多,而且并不是简简单单的二维数据,有时候网页日志、全国信息,电商平台信息等都需要运用大数据技术进行处理和解决,这个时候我们可以利用MySQL来处理,但是我们知道MySQL只能处理有结构的数据,那么难道我们每次进行处理的时候还要对大量的数据进行预处理和清洗吗?显然在这样的高速的信息时代背景下,并不是好的方案。所以我们引进nosql语言-mongdb数据库来解决这些我们认为的不足和难题。

mongdb的特点
(1)MongoDB提出的是文档、集合的概念,使用BSON(类JSON)作为其数据模型结构,其结构是面向对象的而不是二维表,存储一个用户在MongoDB中是这样子的。
-
{
-
username:'王小王',
-
password:'123321'
-
}
使用这样的数据模型,使得MongoDB能在生产环境中提供高读写的能力,吞吐量较于mysql等SQL数据库大大增强。
(2)易伸缩,自动故障转移。易伸缩指的是提供了分片能力,可以对数据集进行分片,数据的存储压力分摊给多台服务器。自动故障转移是副本集的概念,MongoDB能检测主节点是否存活,当失活时能自动提升从节点为主节点,达到故障转移。
(3)数据模型因为是面向对象的,所以可以表示丰富的、有层级的数据结构,比如博客系统中能把“评论”直接怼到“文章“的文档中,而不必像myqsl一样创建三张表来描述这样的关系,它的应用场景比较的广泛,我们在日常的开发当中需要不断地去理解,这样才能在我们的工作当中做到事半功倍的效果。
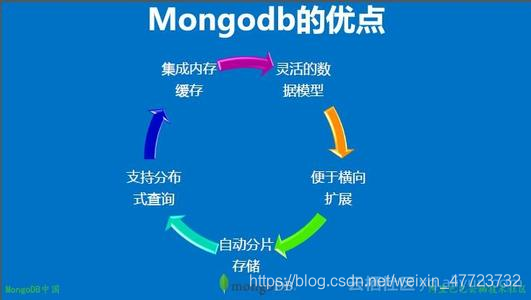
主要特性
(1)文档数据类型
MongoDB没有固定的Schema,正因为MongoDB少了一些这样的约束条件,可以让数据的存储数据结构更灵活,存储速度更加快。
(2)即时查询能力
MongoDB保留了关系型数据库即时查询的能力,保留了索引(底层是基于B tree)的能力,相比于同类型的NoSQL redis 并没有上述的能力。
(3)复制能力
MongoDB自身提供了副本集能将数据分布在多台机器上实现冗余,目的是可以提供自动故障转移、扩展读能力。
(4)速度与持久性
MongoDB的驱动实现一个写入语义 fire and forget ,即通过驱动调用写入时,可以立即得到返回得到成功的结果(即使是报错),这样让写入的速度更加快,当然会有一定的不安全性,完全依赖网络。
(5)数据扩展
MongoDB使用分片技术对数据进行扩展,MongoDB能自动分片、自动转移分片里面的数据块,让每一个服务器里面存储的数据都是一样大小。
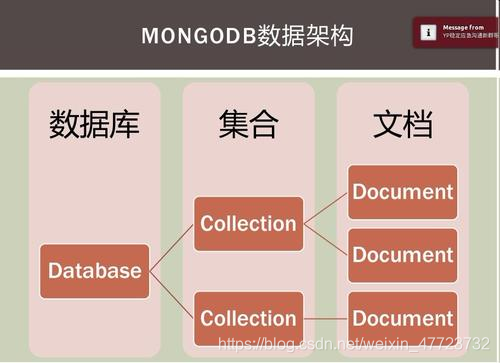
基本概念
深入认知
(1)文档
文档是 MongoDB 中数据的基本单位,类似于关系数据库中的行(但是比行复杂)。多个键及其关联的值有序地放在一起就构成了文档。不同的编程语言对文档的表示方法不同,在JavaScript 中文档表示为:
{“greeting”:“hello,world”}
这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。例如:
{“greeting”:“hello,world”,“foo”: 3}
文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。
{“foo”: 3 ,“greeting”:“hello,world”}
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
(2)集合
集合就是一组文档,类似于关系数据库中的表。集合是无模式的,集合中的文档可以是各式各样的。例如,{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。
所以在实际使用中,往往将文档分类存放在不同的集合中,例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。例如,对于一个博客系统,可能包括blog.user 和blog.article 两个子集合,这样划分只是让组织结构更好一些,blog 集合和blog.user、blog.article 没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB 推荐的方法。
(3)数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。一个MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。MongoDB 中存在以下系统数据库。
应用场景
MongoDB 的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)和传统的RDBMS 系统(具有丰富的功能)之间架起一座桥梁,它集两者的优势于一身。根据官方网站的描述,Mongo 适用于以下场景。
● 网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
● 缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo 搭建的持久化缓存层可以避免下层的数据源过载。
● 大尺寸、低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
● 高伸缩性的场景:Mongo 非常适合由数十或数百台服务器组成的数据库,Mongo 的路线图中已经包含对MapReduce 引擎的内置支持。
● 用于对象及JSON 数据的存储:Mongo 的BSON 数据格式非常适合文档化格式的存储及查询。
MongoDB 的使用也会有一些限制,例如,它不适合于以下几个地方。
● 高度事务性的系统:例如,银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
● 传统的商业智能应用:针对特定问题的BI 数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
● 需要SQL 的问题。
每文一语
知其然还须知其所以然
文章来源: blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_47723732/article/details/114293808

- 点赞
- 收藏
- 关注作者
评论(0)