数据结构课上笔记5

介绍了链表和基本操作
用一组物理位置任意的存储单元来存放线性表的数据元素。 这组存储单元既可以是连续的,也可以是不连续的,甚至是零散分布在内存中的任意位置上的。因此,链表中元素的逻辑次序和 物理次序不一定相同。
定义:
-
typedef struct Lnode{
-
//声明结点的类型和指向结点的指针类型
-
ElemType data; //数据元素的类型
-
struct Lnode *next; //指示结点地址的指针
-
}Lnode, *LinkList;
-
struct Student
-
{ char num[8]; //数据域
-
char name[8]; //数据域
-
int score; //数据域
-
struct Student *next; // next 既是 struct Student
-
// 类型中的一个成员,又指
-
// 向 struct Student 类型的数据。
-
}Stu_1, Stu_2, Stu_3, *LL;
头结点:在单链表的第一个结点之前人为地附设的一个结点。

带头结点操作会方便很多。
带和不带的我都写过了
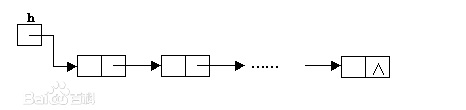
下面列出我见过的一些好题
1、
线性表的每个结点只能是一个简单类型,而链表的每个结点可以是一个复杂类型。
-
正确 -
错误
错,线性表是逻辑结构概念,可以顺序存储或链式储,与元素数据类型无关。链表就是线性表的一种 前后矛盾
2、
若某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用( )存储方式最节省运算时间。
-
单链表 -
仅有头指针的单循环链表 -
双链表 -
仅有尾指针的单循环链表对于A,B,C要想在尾端插入结点,需要遍历整个链表。
对于D,要插入结点,只要改变一下指针即可,要删除头结点,只要删除指针.next的元素即可。
3、注意:线性表是具有n个数据元素的有限序列,而不是数据项
4、
以下关于单向链表说法正确的是
-
如果两个单向链表相交,那他们的尾结点一定相同 -
快慢指针是判断一个单向链表有没有环的一种方法 -
有环的单向链表跟无环的单向链表不可能相交 -
如果两个单向链表相交,那这两个链表都一定不存在环
自己多画画想想就明白了,关于快慢指针我以后会写总结。
5、
链接线性表是顺序存取的线性表 。 ( )
-
正确 -
错误
链接线性表可以理解为链表
线性表分为顺序表和链表
顺序表是顺序存储结构、随机存取结构
链表是随机存储结构、顺序存取结构
6、
-
typedef struct node_s{
-
int item;
-
struct node_s* next;
-
}node_t;
-
node_t* reverse_list(node_t* head)
-
{
-
node_t* n=head;
-
head=NULL;
-
while(n){
-
_________
-
}
-
return head;
-
}
空白处填入以下哪项能实现该函数的功能?
-
node_t* m=head; head=n; head->next=m; n=n->next; -
node_t* m=n; n=n->next; m->next=head; head=m; -
node_t* m=n->next; n->next=head; n=m; head=n; -
head=n->next; head->next=n; n=n->next;
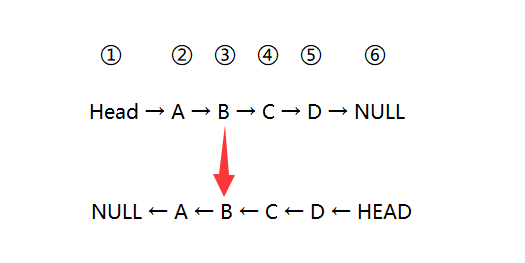
代码的功能是要实现链表的反转。为了方便阐述,每个结点用①②③④⑤⑥等来标示。
在执行while(n)循环之前,有两句代码:
|
|
这两行代码的中:第一句的作用是用一个临时变量n来保存结点①,第二句是把head修改为NULL。
然后就开始遍历了,我们看到while循环里的那四句代码:
-
node_t* m=n;
-
n=n->next;
-
m->next=head;
-
head=m;
先看前两句,用m来保存n,然后让n指向n的下一个结点,之所以复制 n 给 m ,是因为 n 的作用其实是 控制while循环次数 的作用,每循环一次它就要被修改为指向下一个结点。
再看后两句,变量head在这里像是一个临时变量,后两句让 m 指向了 head,然后 head 等于 m。
7、
若某表最常用的操作是在最后一个结点之后插入一个节点或删除最后一二个结点,则采用()省运算时间。
-
单链表 -
双链表 -
单循环链表 -
带头结点的双循环链表
D
带头结点的双向循环链表,头结点的前驱即可找到最后一个结点,可以快速插入,再向前可以找到最后一二个结点快速删除
单链表找到链表尾部需要扫描整个链表
双链表找到链表尾部也需要扫描整个链表
单循环链表只有单向指针,找到链表尾部也需要扫描整个链表
8、
单链表的存储密度( )
-
大于1 -
等于1 -
小于1 -
不能确定
存储密度 = 数据项所占空间 / 结点所占空间
9、完成在双循环链表结点p之后插入s的操作是
-
s->prior=p; s->next=p->next; p->next->prior=s ; p->next=s;
10、用不带头结点的单链表存储队列,其队头指针指向队头结点,队尾指针指向队尾结点,则在进行出队操作时()
-
仅修改队头指针 -
仅修改队尾指针 -
队头、队尾指针都可能要修改 -
队头、队尾指针都要修改
当只有一个元素,出队列时,要将队头和队尾,指向-1.所以说队头和队尾都需要修改
链表刷了几百道吧,好题还有很多,以后接着更新
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/82834818

- 点赞
- 收藏
- 关注作者
评论(0)