redis——新版复制

sync虽然解决了数据同步问题,但是在数据量比较大情况下,从库断线从来依然采用全量复制机制,无论是从数据恢复、宽带占用来说,sync所带来的问题还是很多的。于是redis从2.8开始,引入新的命令psync。
psync有两种模式:完整重同步和部分重同步。
部分重同步主要依赖三个方面来实现,依次介绍。
offset(复制偏移量):
主库和从库分别各自维护一个复制偏移量(可以使用info replication查看),用于标识自己复制的情况:
在主库中代表主节点向从节点传递的字节数,在从库中代表从库同步的字节数。
每当主库向从节点发送N个字节数据时,主节点的offset增加N
从库每收到主节点传来的N个字节数据时,从库的offset增加N。
因此offset总是不断增大,这也是判断主从数据是否同步的标志,若主从的offset相同则表示数据同步量,不通则表示数据不同步。
replication backlog buffer(复制积压缓冲区):
复制积压缓冲区是一个固定长度的FIFO队列,大小由配置参数repl-backlog-size指定,默认大小1MB。
需要注意的是该缓冲区由master维护并且有且只有一个,所有slave共享此缓冲区,其作用在于备份最近主库发送给从库的数据。
在主从命令传播阶段,主节点除了将写命令发送给从节点外,还会发送一份到复制积压缓冲区,作为写命令的备份。
除了存储最近的写命令,复制积压缓冲区中还存储了每个字节相应的复制偏移量,由于复制积压缓冲区固定大小先进先出的队列,所以它总是保存的是最近redis执行的命令。
所以,重连服务器后,从服务器会发送自己的复制偏移量offset给主服务器,
如果offset偏移量之后的数据仍然存在于复制挤压缓冲区,就执行部分重同步操作。
相反,执行完整重同步操作。
run_id(服务器运行的唯一ID)
每个redis实例在启动时候,都会随机生成一个长度为40的唯一字符串来标识当前运行的redis节点,查看此id可通过命令info server查看。
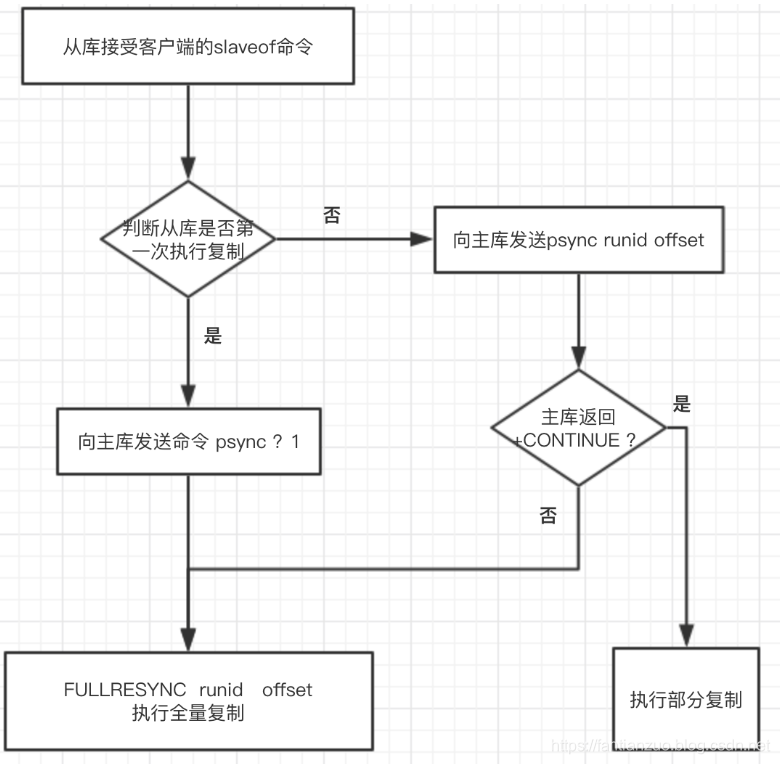
当主从复制在初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来,当断线重连时,从节点会将这个runid发送给主节点。主节点根据runid判断能否进行部分复制:
- 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会更具offset偏移量之后的数据判断是否执行部分复制,如果offset偏移量之后的数据仍然都在复制积压缓冲区里,则执行部分复制,否则执行全量复制;
- 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的redis节点并不是当前的主节点,只能进行全量复制;
psync流程:
复制
客户端向服务器端发送:SLAVEOF
1、设置主服务器的地址和端口
存到masterhost和mastterport两个属性里之后,向客户端发送ok,然后开始复制工作。
2、建立套接字链接
从服务器根据命令设置的地址和端口,创建链接,并且为这个套接字创建一个专门处理复制工作的文件事件处理器。
主服务器也会为套接字创建相应的客户端状态,并且把从服务器当作一个客户端来对待。
3、发送ping命令(检查)
检查套接字状态是否正常
检查主服务器是否能正确处理请求。(如果不能,就重连)
4、身份认证
5、发送端口信息
从服务器向主服务器发送信息,主服务器记录。
6、同步
从服务器向主服务器发送psync命令。(主服务器也成为从服务器的客户端,因为主服务器会发送写命令给从服务器)
7、命令传播
完成同步后,进入传播阶段,主服务器一直发送写命令,从服务器一直接受,保证和主服务器一致。
心跳检测
默认一秒一次,从服务器向主服务器发送命令:REPLCONF ACK <offset>
三个作用:
检测网络连接状态:如果主服务器一秒没收到命令,就说明出问题了
辅助实现min-slaves配置:min-slaves-to-write 3 min-slaves-max-log 10:当从服务器小于3个或延迟都大于10,主服务器拒绝写命令。
检测命令丢失:如果命令丢失,主服务器会发现偏移量不一样,然后它就会根据偏移量,去积压缓冲区找到缺少的数据并发给从服务器。
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/102694618

- 点赞
- 收藏
- 关注作者
评论(0)