源码分析RocketMQ消息轨迹

本文沿着《RocketMQ消息轨迹-设计篇》的思路,从如下3个方面对其源码进行解读:
- 发送消息轨迹
- 消息轨迹格式
- 存储消息轨迹数据
本节目录
1、发送消息轨迹流程
首先我们来看一下在消息发送端如何启用消息轨迹,示例代码如下:
public class TraceProducer { public static void main(String[] args) throws MQClientException, InterruptedException { DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName",true); // @1 producer.setNamesrvAddr("127.0.0.1:9876"); producer.start(); for (int i = 0; i < 10; i++) try { { Message msg = new Message("TopicTest", "TagA", "OrderID188", "Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET)); SendResult sendResult = producer.send(msg); System.out.printf("%s%n", sendResult); } } catch (Exception e) { e.printStackTrace(); } producer.shutdown(); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
从上述代码可以看出其关键点是在创建DefaultMQProducer时指定开启消息轨迹跟踪。我们不妨浏览一下DefaultMQProducer与启用消息轨迹相关的构造函数:
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace)
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace, final String customizedTraceTopic)
- 1
- 2
参数如下:
- String producerGroup
生产者所属组名。 - boolean enableMsgTrace
是否开启跟踪消息轨迹,默认为false。 - String customizedTraceTopic
如果开启消息轨迹跟踪,用来存储消息轨迹数据所属的主题名称,默认为:RMQ_SYS_TRACE_TOPIC。
1.1 DefaultMQProducer构造函数
public DefaultMQProducer(final String producerGroup, RPCHook rpcHook, boolean enableMsgTrace,final String customizedTraceTopic) { // @1 this.producerGroup = producerGroup; defaultMQProducerImpl = new DefaultMQProducerImpl(this, rpcHook); //if client open the message trace feature if (enableMsgTrace) { // @2 try { AsyncTraceDispatcher dispatcher = new AsyncTraceDispatcher(customizedTraceTopic, rpcHook); dispatcher.setHostProducer(this.getDefaultMQProducerImpl()); traceDispatcher = dispatcher; this.getDefaultMQProducerImpl().registerSendMessageHook( new SendMessageTraceHookImpl(traceDispatcher)); // @3 } catch (Throwable e) { log.error("system mqtrace hook init failed ,maybe can't send msg trace data"); } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
代码@1:首先介绍一下其局部变量。
- String producerGroup
生产者所属组。 - RPCHook rpcHook
生产者发送钩子函数。 - boolean enableMsgTrace
是否开启消息轨迹跟踪。 - String customizedTraceTopic
定制用于存储消息轨迹的数据。
代码@2:用来构建AsyncTraceDispatcher,看其名:异步转发消息轨迹数据,稍后重点关注。
代码@3:构建SendMessageTraceHookImpl对象,并使用AsyncTraceDispatcher用来异步转发。
1.2 SendMessageTraceHookImpl钩子函数
1.2.1 SendMessageTraceHookImpl类图
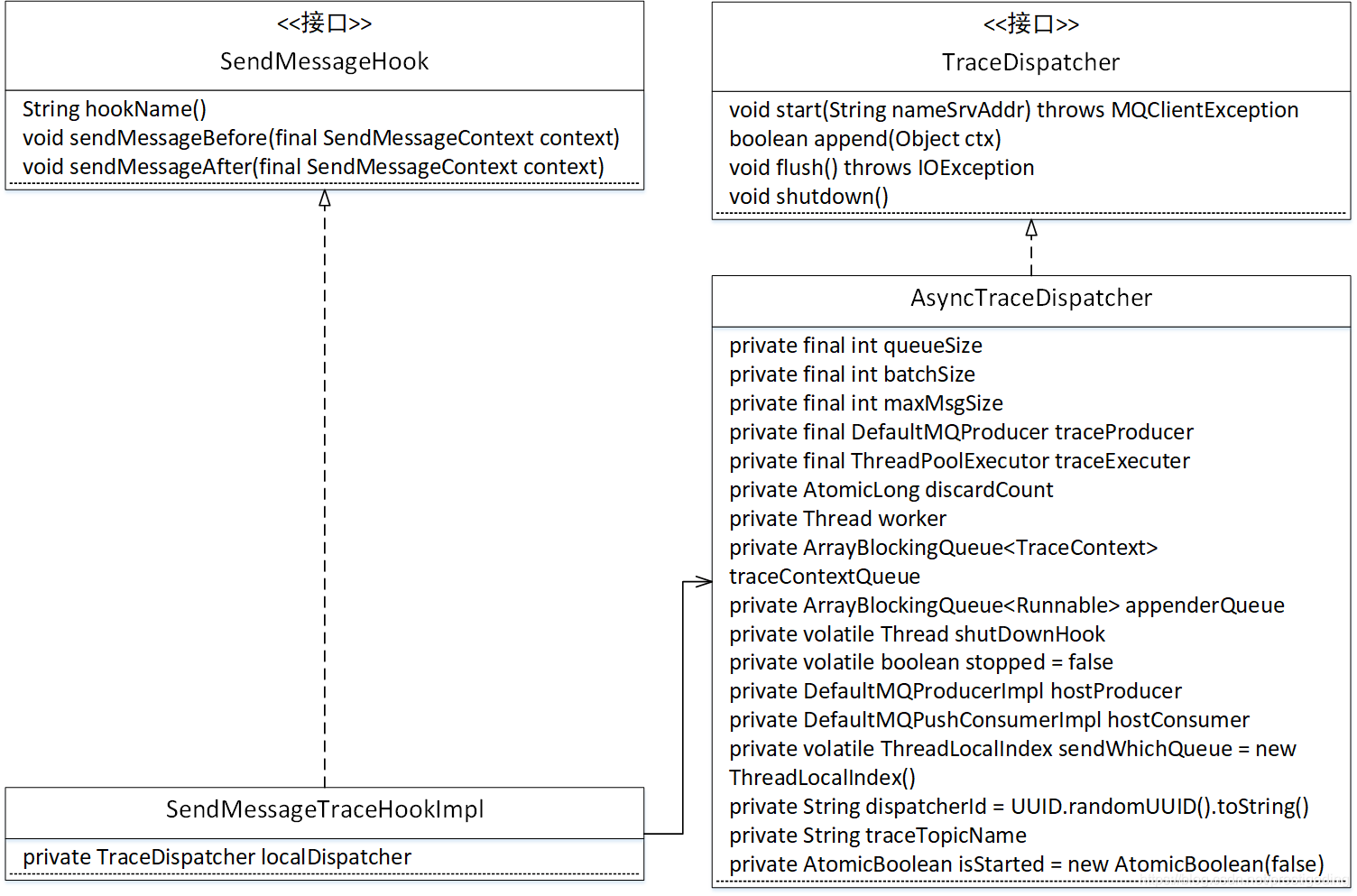
- SendMessageHook
消息发送钩子函数,用于在消息发送之前、发送之后执行一定的业务逻辑,是记录消息轨迹的最佳扩展点。 - TraceDispatcher
消息轨迹转发处理器,其默认实现类AsyncTraceDispatcher,异步实现消息轨迹数据的发送。下面对其属性做一个简单的介绍:- int queueSize
异步转发,队列长度,默认为2048,当前版本不能修改。 - int batchSize
批量消息条数,消息轨迹一次消息发送请求包含的数据条数,默认为100,当前版本不能修改。 - int maxMsgSize
消息轨迹一次发送的最大消息大小,默认为128K,当前版本不能修改。 - DefaultMQProducer traceProducer
用来发送消息轨迹的消息发送者。 - ThreadPoolExecutor traceExecuter
线程池,用来异步执行消息发送。 - AtomicLong discardCount
记录丢弃的消息个数。 - Thread worker
woker线程,主要负责从追加队列中获取一批待发送的消息轨迹数据,提交到线程池中执行。 - ArrayBlockingQueue< TraceContext> traceContextQueue
消息轨迹TraceContext队列,用来存放待发送到服务端的消息。 - ArrayBlockingQueue< Runnable> appenderQueue
线程池内部队列,默认长度1024。 - DefaultMQPushConsumerImpl hostConsumer
消费者信息,记录消息消费时的轨迹信息。 - String traceTopicName
用于跟踪消息轨迹的topic名称。
- int queueSize
1.2.2 源码分析SendMessageTraceHookImpl
1.2.2.1 sendMessageBefore
public void sendMessageBefore(SendMessageContext context) { //if it is message trace data,then it doesn't recorded if (context == null || context.getMessage().getTopic().startsWith(((AsyncTraceDispatcher) localDispatcher).getTraceTopicName())) { // @1 return; } //build the context content of TuxeTraceContext TraceContext tuxeContext = new TraceContext(); tuxeContext.setTraceBeans(new ArrayList<TraceBean>(1)); context.setMqTraceContext(tuxeContext); tuxeContext.setTraceType(TraceType.Pub); tuxeContext.setGroupName(context.getProducerGroup()); // @2 //build the data bean object of message trace TraceBean traceBean = new TraceBean(); // @3 traceBean.setTopic(context.getMessage().getTopic()); traceBean.setTags(context.getMessage().getTags()); traceBean.setKeys(context.getMessage().getKeys()); traceBean.setStoreHost(context.getBrokerAddr()); traceBean.setBodyLength(context.getMessage().getBody().length); traceBean.setMsgType(context.getMsgType()); tuxeContext.getTraceBeans().add(traceBean);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
代码@1:如果topic主题为消息轨迹的Topic,直接返回。
代码@2:在消息发送上下文中,设置用来跟踪消息轨迹的上下环境,里面主要包含一个TraceBean集合、追踪类型(TraceType.Pub)与生产者所属的组。
代码@3:构建一条跟踪消息,用TraceBean来表示,记录原消息的topic、tags、keys、发送到broker地址、消息体长度等消息。
从上文看出,sendMessageBefore主要的用途就是在消息发送的时候,先准备一部分消息跟踪日志,存储在发送上下文环境中,此时并不会发送消息轨迹数据。
1.2.2.2 sendMessageAfter
public void sendMessageAfter(SendMessageContext context) { //if it is message trace data,then it doesn't recorded if (context == null || context.getMessage().getTopic().startsWith(((AsyncTraceDispatcher) localDispatcher).getTraceTopicName()) // @1 || context.getMqTraceContext() == null) { return; } if (context.getSendResult() == null) { return; } if (context.getSendResult().getRegionId() == null || !context.getSendResult().isTraceOn()) { // if switch is false,skip it return; } TraceContext tuxeContext = (TraceContext) context.getMqTraceContext(); TraceBean traceBean = tuxeContext.getTraceBeans().get(0); // @2 int costTime = (int) ((System.currentTimeMillis() - tuxeContext.getTimeStamp()) / tuxeContext.getTraceBeans().size()); // @3 tuxeContext.setCostTime(costTime); // @4 if (context.getSendResult().getSendStatus().equals(SendStatus.SEND_OK)) { tuxeContext.setSuccess(true); } else { tuxeContext.setSuccess(false); } tuxeContext.setRegionId(context.getSendResult().getRegionId()); traceBean.setMsgId(context.getSendResult().getMsgId()); traceBean.setOffsetMsgId(context.getSendResult().getOffsetMsgId()); traceBean.setStoreTime(tuxeContext.getTimeStamp() + costTime / 2); localDispatcher.append(tuxeContext); // @5
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
代码@1:如果topic主题为消息轨迹的Topic,直接返回。
代码@2:从MqTraceContext中获取跟踪的TraceBean,虽然设计成List结构体,但在消息发送场景,这里的数据永远只有一条,及时是批量发送也不例外。
代码@3:获取消息发送到收到响应结果的耗时。
代码@4:设置costTime(耗时)、success(是否发送成功)、regionId(发送到broker所在的分区)、msgId(消息ID,全局唯一)、offsetMsgId(消息物理偏移量,如果是批量消息,则是最后一条消息的物理偏移量)、storeTime,这里使用的是(客户端发送时间 + 二分之一的耗时)来表示消息的存储时间,这里是一个估值。
代码@5:将需要跟踪的信息通过TraceDispatcher转发到Broker服务器。其代码如下:
public boolean append(final Object ctx) { boolean result = traceContextQueue.offer((TraceContext) ctx); if (!result) { log.info("buffer full" + discardCount.incrementAndGet() + " ,context is " + ctx); } return result;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里一个非常关键的点是offer方法的使用,当队列无法容纳新的元素时会立即返回false,并不会阻塞。
接下来将目光转向TraceDispatcher的实现。
1.3 TraceDispatcher实现原理
TraceDispatcher,用于客户端消息轨迹数据转发到Broker,其默认实现类:AsyncTraceDispatcher。
1.3.1 TraceDispatcher构造函数
public AsyncTraceDispatcher(String traceTopicName, RPCHook rpcHook) throws MQClientException { // queueSize is greater than or equal to the n power of 2 of value this.queueSize = 2048; this.batchSize = 100; this.maxMsgSize = 128000; this.discardCount = new AtomicLong(0L); this.traceContextQueue = new ArrayBlockingQueue<TraceContext>(1024); this.appenderQueue = new ArrayBlockingQueue<Runnable>(queueSize); if (!UtilAll.isBlank(traceTopicName)) { this.traceTopicName = traceTopicName; } else { this.traceTopicName = MixAll.RMQ_SYS_TRACE_TOPIC; } // @1 this.traceExecuter = new ThreadPoolExecutor(// : 10, // 20, // 1000 * 60, // TimeUnit.MILLISECONDS, // this.appenderQueue, // new ThreadFactoryImpl("MQTraceSendThread_")); traceProducer = getAndCreateTraceProducer(rpcHook); // @2
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代码@1:初始化核心属性,该版本这些值都是“固化”的,用户无法修改。
- queueSize
队列长度,默认为2048,异步线程池能够积压的消息轨迹数量。 - batchSize
一次向Broker批量发送的消息条数,默认为100. - maxMsgSize
向Broker汇报消息轨迹时,消息体的总大小不能超过该值,默认为128k。 - discardCount
整个运行过程中,丢弃的消息轨迹数据,这里要说明一点的是,如果消息TPS发送过大,异步转发线程处理不过来时,会主动丢弃消息轨迹数据。 - traceContextQueue
traceContext积压队列,客户端(消息发送、消息消费者)在收到处理结果后,将消息轨迹提交到噶队列中,则会立即返回。 - appenderQueue
提交到Broker线程池中队列。 - traceTopicName
用于接收消息轨迹的Topic,默认为RMQ_SYS_TRANS_HALF_TOPIC。 - traceExecuter
用于发送到Broker服务的异步线程池,核心线程数默认为10,最大线程池为20,队列堆积长度2048,线程名称:MQTraceSendThread_。、 - traceProducer
发送消息轨迹的Producer。
代码@2:调用getAndCreateTraceProducer方法创建用于发送消息轨迹的Producer(消息发送者),下面详细介绍一下其实现。
1.3.2 getAndCreateTraceProducer详解
private DefaultMQProducer getAndCreateTraceProducer(RPCHook rpcHook) { DefaultMQProducer traceProducerInstance = this.traceProducer; if (traceProducerInstance == null) { //@1 traceProducerInstance = new DefaultMQProducer(rpcHook); traceProducerInstance.setProducerGroup(TraceConstants.GROUP_NAME); traceProducerInstance.setSendMsgTimeout(5000); traceProducerInstance.setVipChannelEnabled(false); // The max size of message is 128K traceProducerInstance.setMaxMessageSize(maxMsgSize - 10 * 1000); } return traceProducerInstance; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
代码@1:如果还未建立发送者,则创建用于发送消息轨迹的消息发送者,其GroupName为:_INNER_TRACE_PRODUCER,消息发送超时时间5s,最大允许发送消息大小118K。
1.3.3 start
public void start(String nameSrvAddr) throws MQClientException { if (isStarted.compareAndSet(false, true)) { // @1 traceProducer.setNamesrvAddr(nameSrvAddr); traceProducer.setInstanceName(TRACE_INSTANCE_NAME + "_" + nameSrvAddr); traceProducer.start(); } this.worker = new Thread(new AsyncRunnable(), "MQ-AsyncTraceDispatcher-Thread-" + dispatcherId); // @2 this.worker.setDaemon(true); this.worker.start(); this.registerShutDownHook();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
开始启动,其调用的时机为启动DefaultMQProducer时,如果启用跟踪消息轨迹,则调用之。
代码@1:如果用于发送消息轨迹的发送者没有启动,则设置nameserver地址,并启动着。
代码@2:启动一个线程,用于执行AsyncRunnable任务,接下来将重点介绍。
1.3.4 AsyncRunnable
class AsyncRunnable implements Runnable { private boolean stopped;
public void run() { while (!stopped) { List<TraceContext> contexts = new ArrayList<TraceContext>(batchSize); // @1 for (int i = 0; i < batchSize; i++) { TraceContext context = null; try { //get trace data element from blocking Queue — traceContextQueue context = traceContextQueue.poll(5, TimeUnit.MILLISECONDS); // @2 } catch (InterruptedException e) { } if (context != null) { contexts.add(context); } else { break; } } if (contexts.size() > 0) { : AsyncAppenderRequest request = new AsyncAppenderRequest(contexts); // @3 traceExecuter.submit(request); } else if (AsyncTraceDispatcher.this.stopped) { this.stopped = true; } } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码@1:构建待提交消息跟踪Bean,每次最多发送batchSize,默认为100条。
代码@2:从traceContextQueue中取出一个待提交的TraceContext,设置超时时间为5s,即如何该队列中没有待提交的TraceContext,则最多等待5s。
代码@3:向线程池中提交任务AsyncAppenderRequest。
1.3.5 AsyncAppenderRequest#sendTraceData
public void sendTraceData(List<TraceContext> contextList) { Map<String, List<TraceTransferBean>> transBeanMap = new HashMap<String, List<TraceTransferBean>>(); for (TraceContext context : contextList) { //@1 if (context.getTraceBeans().isEmpty()) { continue; } // Topic value corresponding to original message entity content String topic = context.getTraceBeans().get(0).getTopic(); // @2 // Use original message entity's topic as key String key = topic; List<TraceTransferBean> transBeanList = transBeanMap.get(key); if (transBeanList == null) { transBeanList = new ArrayList<TraceTransferBean>(); transBeanMap.put(key, transBeanList); } TraceTransferBean traceData = TraceDataEncoder.encoderFromContextBean(context); // @3 transBeanList.add(traceData); } for (Map.Entry<String, List<TraceTransferBean>> entry : transBeanMap.entrySet()) { // @4 flushData(entry.getValue()); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代码@1:遍历收集的消息轨迹数据。
代码@2:获取存储消息轨迹的Topic。
代码@3:对TraceContext进行编码,这里是消息轨迹的传输数据,稍后对其详细看一下,了解其上传的格式。
代码@4:将编码后的数据发送到Broker服务器。
1.3.6 TraceDataEncoder#encoderFromContextBean
根据消息轨迹跟踪类型,其格式会有一些不一样,下面分别来介绍其合适。
1.3.6.1 PUB(消息发送)
case Pub: { TraceBean bean = ctx.getTraceBeans().get(0); //append the content of context and traceBean to transferBean's TransData sb.append(ctx.getTraceType()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getTimeStamp()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getRegionId()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getGroupName()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getTopic()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getMsgId()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getTags()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getKeys()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getStoreHost()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getBodyLength()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getCostTime()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getMsgType().ordinal()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getOffsetMsgId()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.isSuccess()).append(TraceConstants.FIELD_SPLITOR);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
消息轨迹数据的协议使用字符串拼接,字段的分隔符号为1,整个数据以2结尾,感觉这个设计还是有点“不可思议”,为什么不直接使用json协议呢?
1.3.6.2 SubBefore(消息消费之前)
for (TraceBean bean : ctx.getTraceBeans()) { sb.append(ctx.getTraceType()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getTimeStamp()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getRegionId()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getGroupName()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getRequestId()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getMsgId()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getRetryTimes()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getKeys()).append(TraceConstants.FIELD_SPLITOR);// }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
轨迹就是按照上述顺序拼接而成,各个字段使用1分隔,每一条记录使用2结尾。
1.3.2.3 SubAfter(消息消费后)
case SubAfter: { for (TraceBean bean : ctx.getTraceBeans()) { sb.append(ctx.getTraceType()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getRequestId()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getMsgId()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getCostTime()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.isSuccess()).append(TraceConstants.CONTENT_SPLITOR)// .append(bean.getKeys()).append(TraceConstants.CONTENT_SPLITOR)// .append(ctx.getContextCode()).append(TraceConstants.FIELD_SPLITOR); } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
格式编码一样,就不重复多说。
经过上面的源码跟踪,消息发送端的消息轨迹跟踪流程、消息轨迹数据编码协议就清晰了,接下来我们使用一张序列图来结束本部分的讲解。
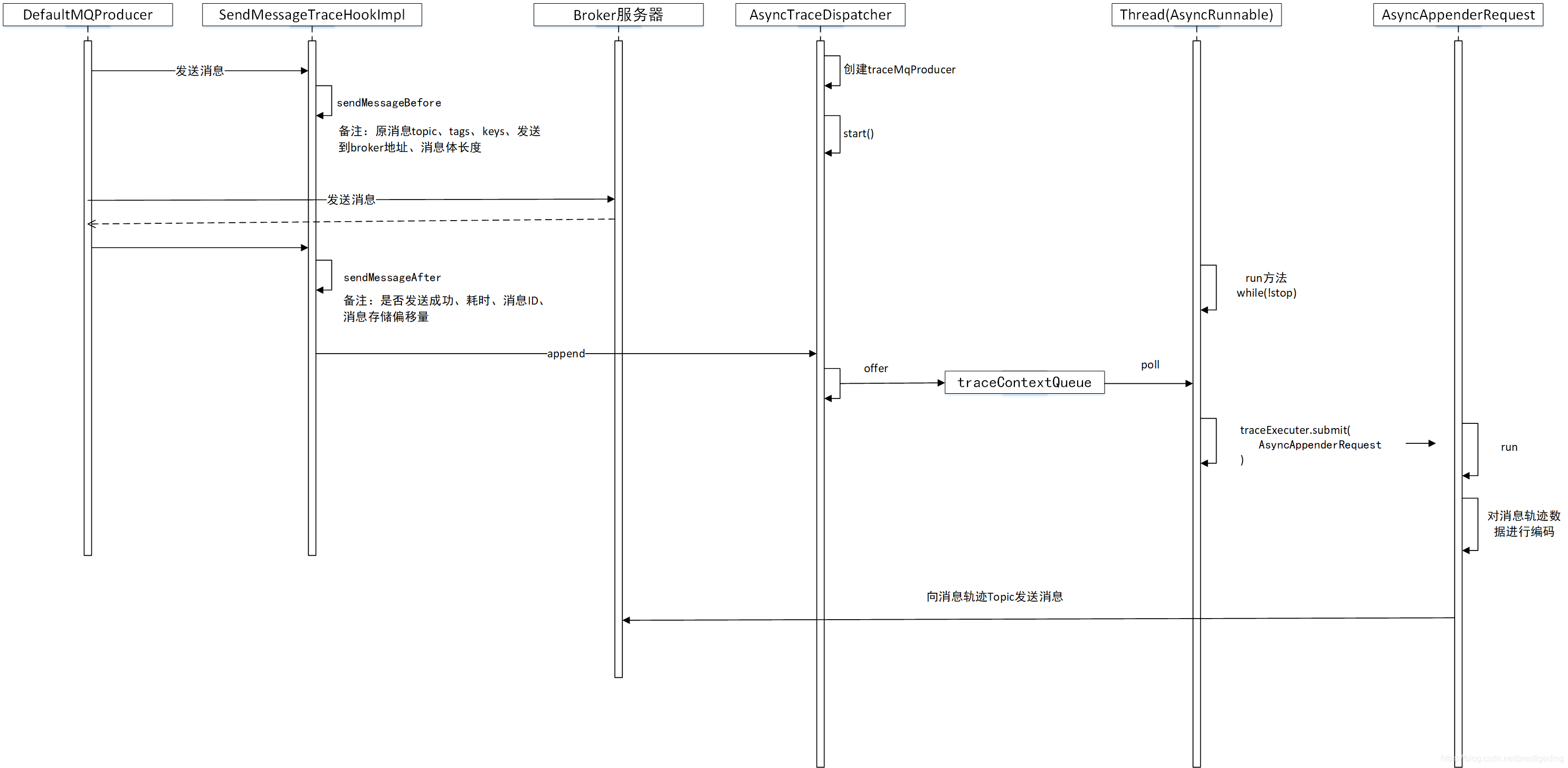
其实行文至此,只关注了消息发送的消息轨迹跟踪,消息消费的轨迹跟踪又是如何呢?其实现原理其实是一样的,就是在消息消费前后执行特定的钩子函数,其实现类为ConsumeMessageTraceHookImpl,由于其实现与消息发送的思路类似,故就不详细介绍了。
2、 消息轨迹数据如何存储
其实从上面的分析,我们已经得知,RocketMQ的消息轨迹数据存储在到Broker上,那消息轨迹的主题名如何指定?其路由信息又怎么分配才好呢?是每台Broker上都创建还是只在其中某台上创建呢?RocketMQ支持系统默认与自定义消息轨迹的主题。
2.1 使用系统默认的主题名称
RocketMQ默认的消息轨迹主题为:RMQ_SYS_TRACE_TOPIC,那该Topic需要手工创建吗?其路由信息呢?
{ if (this.brokerController.getBrokerConfig().isTraceTopicEnable()) { // @1 String topic = this.brokerController.getBrokerConfig().getMsgTraceTopicName(); TopicConfig topicConfig = new TopicConfig(topic); this.systemTopicList.add(topic); topicConfig.setReadQueueNums(1); // @2 topicConfig.setWriteQueueNums(1); this.topicConfigTable.put(topicConfig.getTopicName(), topicConfig); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上述代码出自TopicConfigManager的构造函数,在Broker启动的时候会创建topicConfigManager对象,用来管理topic的路由信息。
代码@1:如果Broker开启了消息轨迹跟踪(traceTopicEnable=true)时,会自动创建默认消息轨迹的topic路由信息,注意其读写队列数为1。
2.2 用户自定义消息轨迹主题
在创建消息发送者、消息消费者时,可以显示的指定消息轨迹的Topic,例如:
public DefaultMQProducer(final String producerGroup, RPCHook rpcHook, boolean enableMsgTrace,final String customizedTraceTopic)
public DefaultMQPushConsumer(final String consumerGroup, RPCHook rpcHook, AllocateMessageQueueStrategy allocateMessageQueueStrategy, boolean enableMsgTrace, final String customizedTraceTopic)
- 1
- 2
- 3
- 4
通过customizedTraceTopic来指定消息轨迹Topic。
温馨提示:通常在生产环境上,将不会开启自动创建主题,故需要RocketMQ运维管理人员提前创建好Topic。
好了,本文就介绍到这里了,本文详细介绍了RocktMQ消息轨迹的实现原理,下一篇,我们将进入到多副本的学习中。
见文如面,我是威哥,热衷于成体系剖析JAVA主流中间件,关注公众号『中间件兴趣圈』,回复专栏可获取成体系专栏导航,回复资料可以获取笔者的学习思维导图。

文章来源: blog.csdn.net,作者:中间件兴趣圈,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/prestigeding/article/details/98376981

- 点赞
- 收藏
- 关注作者
评论(0)