爬虫百战穿山甲(3):全国高校的自我介绍,快来找找你的大学吧!!!


郑重申明:本文仅为研究学习使用。
网页分析
网址:https://gkcx.eol.cn/school/search
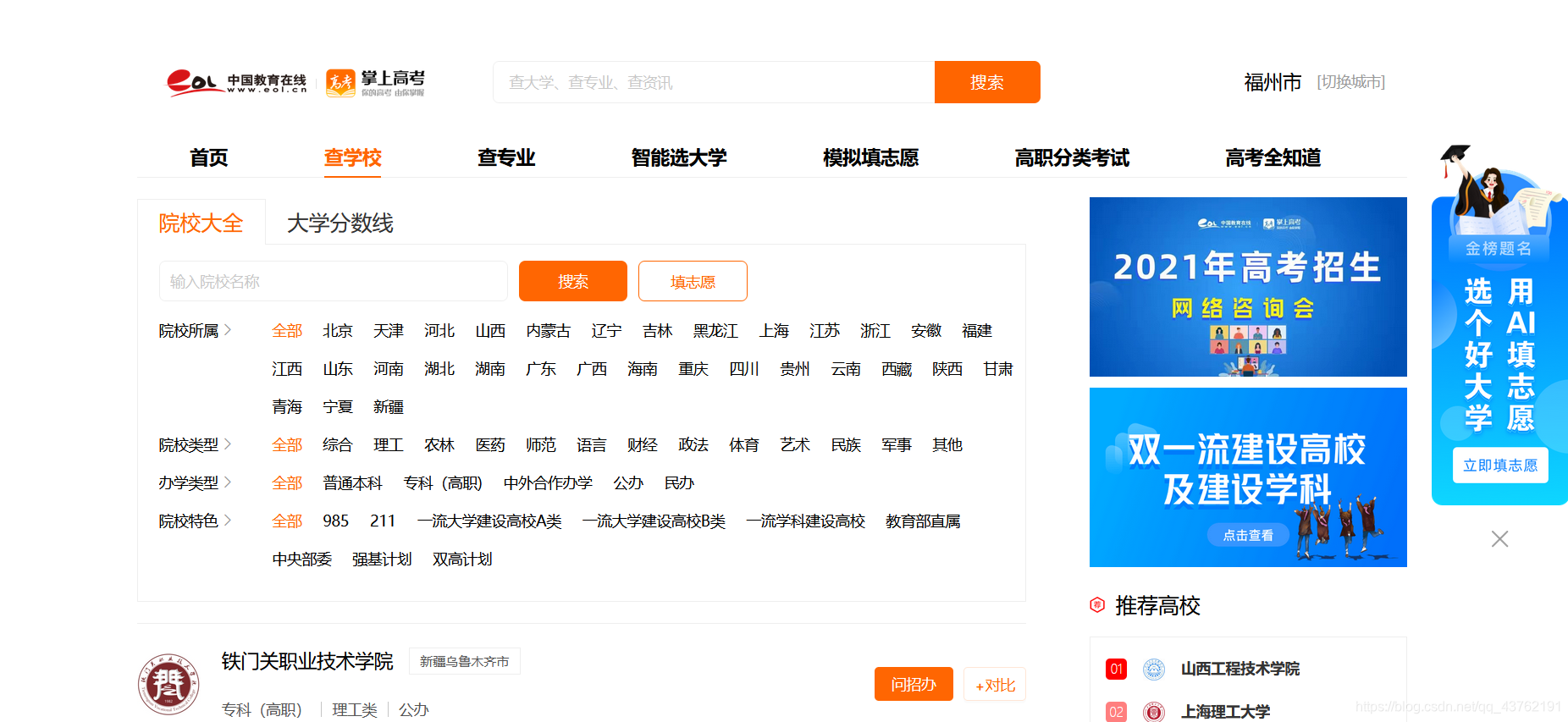
一页20个学校,总共一百多页:
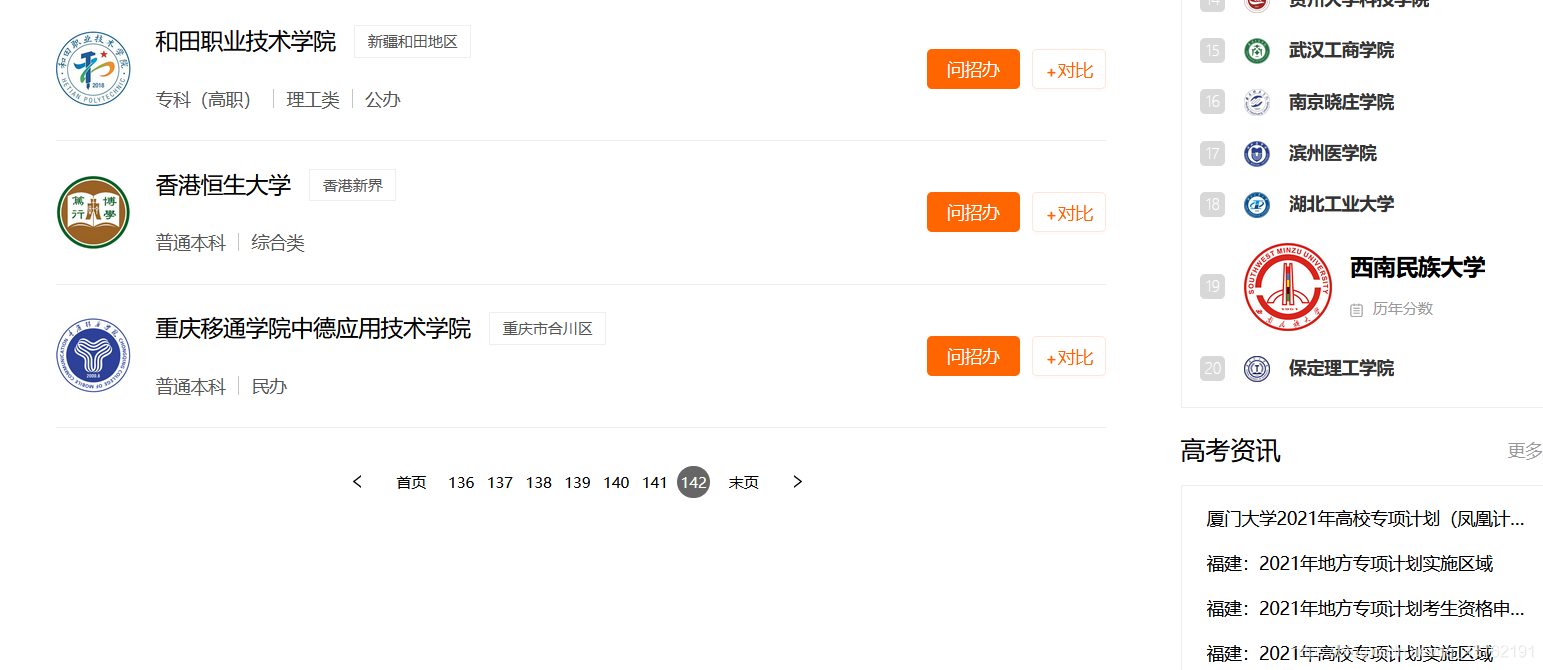
我估摸着有近三千个学校吧。
接触一个陌生网站做爬虫,先拿源码试试水嘛,源码要是都拿不下来那就,懂得都懂。
源码拿下来之后,做一下Xpath提取标签?一看就不专业。
这个是动态网页,要提取标签要用post方法来提。
那你这一百多页,PO一百多次,可能第一次就直接失败了。反正我post这么多次成功次数两只手熟的过来。
而且要PO,那就是找到包了嘛,那我直接解析json不好吗?
我就不多说怎么找包了吧,XHR下面就三个包,一个一个开业很快。
不过我还是要提个醒,最近谷歌浏览器被报出漏洞,所以访问陌生网站会有一定的风险,反正你们自己选择嘛,我是用谷歌的。
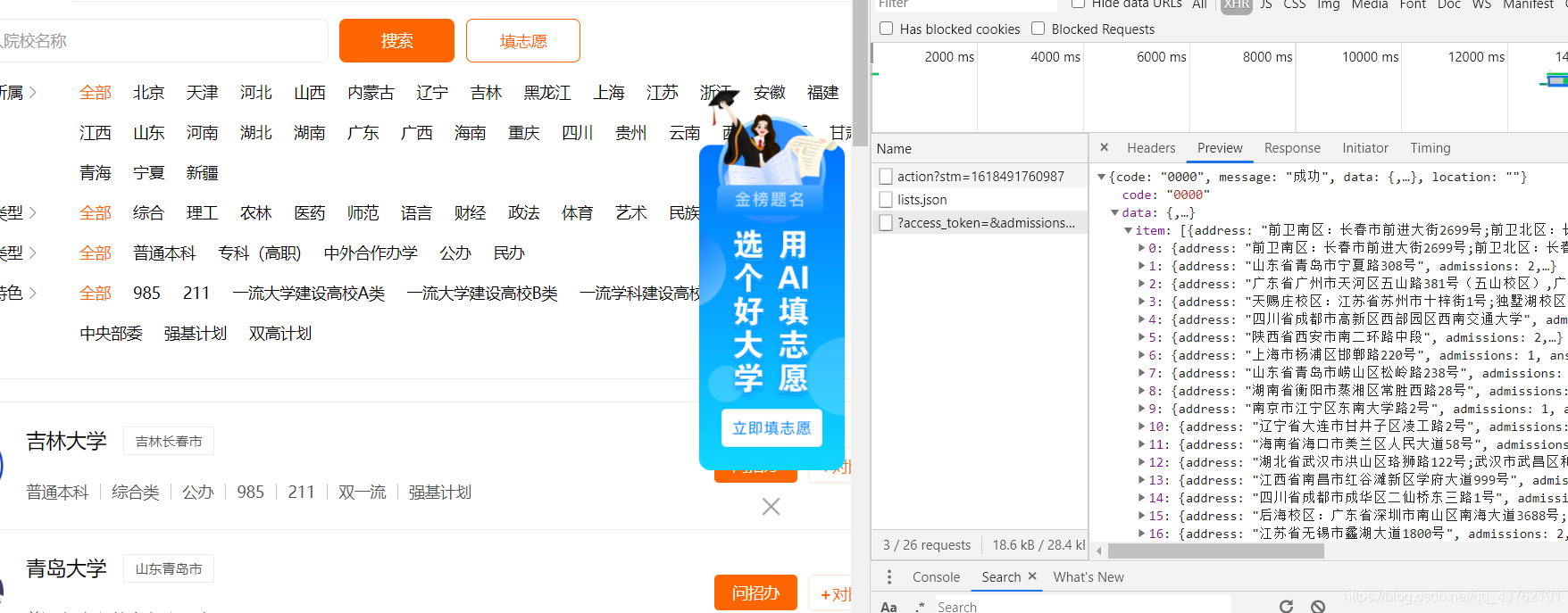
看一下json的url啊,这要是没有规律咱可不能蛮干,一百四十多页呢!!!
json数据网址:
https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page=2&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&type=&uri=apidata/api/gk/school/lists
眼尖的一下就看到了哈。
那还说啥,开始干活儿呗。
开工
#coding:utf-8
# 我们李老师说了,这个的意思是:告诉解释器,本段代码获取的数据皆以utf-8编码,解码的时候以utf-8解码即可
import requests import json
import time
from lxml import etree
import random
import openpyxl
#使用时请自行寻找四五个可用的请求头
header_list = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"]
def get_html(url,sleep_time): ''' 获取网页源码 :param url: 目标网址 :param header_list: 请求头列表 :param sleep_time: 友好时间 :return: 网页源码,未经任何处理 ''' times = 3 try: res = requests.get(url=url, headers={"User-Agent":random.choice(header_list)}) if res.status_code >= 200 and res.status_code<300: time.sleep(sleep_time) return res else: return None except Exception as e: print(e) if times>0: print("机会次数:"+str(times)) get_html(url,sleep_time) else: print("无法爬取")
def get_xpath_data(html_data,xpath): ''' 解析网页源码,获取标签数据 :param html_data: 网页源码 :param xpath: Xpath路径 :return: 标签数据列表 ''' data = html_data.content # 这里要使用content,而不是text data = data.decode().replace("<!--","").replace("--!>","") # 对数据进行转码操作 tree = etree.HTML(data) # 创建element对象 el_list = tree.xpath(xpath) return el_list
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['address', 'admissions', 'answerurl', 'belong', 'central', 'city_id', 'city_name', 'code_enroll', 'colleges_level', 'county_id', 'county_name', 'department', 'doublehigh', 'dual_class', 'dual_class_name', 'f211', 'f985', 'id', 'is_recruitment', 'is_top', 'level', 'level_name', 'name', 'nature', 'nature_name', 'province_id', 'province_name', 'rank', 'rank_type', 'school_id', 'school_type', 'single_province', 'type', 'type_name', 'view_month', 'view_month_number', 'view_total', 'view_total_number', 'view_week', 'view_week_number', 'view_year'])
for i in range(1,143): url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page='+str(i)+'&province_id=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&type=&uri=apidata/api/gk/school/lists' try: res = get_html(url,2) j_data = json.loads(res.content)["data"]['item'] for data in j_data: ws.append([data['address'], data['admissions'], data['answerurl'], data['belong'], data['central'], data['city_id'], data['city_name'], data['code_enroll'], data['colleges_level'], data['county_id'], data['county_name'], data['department'], data['doublehigh'], data['dual_class'], data['dual_class_name'], data['f211'], data['f985'], data['id'], data['is_recruitment'], data['is_top'], data['level'], data['level_name'], data['name'], data['nature'],data[ 'nature_name'],data[ 'province_id'],data['province_name'],data['rank'],data[ 'rank_type'],data['school_id'],data['school_type'], data['single_province'],data['type'],data['type_name'],data['view_month'],data['view_month_number'],data['view_total'], data['view_total_number'],data['view_week'],data['view_week_number'],data['view_year']]) print("Success") except: print(url)
wb.save('test.xlsx')
wb.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
事后会获取到一批的网址,至于批量获取网址打开之后的内容,就需要用到并发编程了,后面专门出一套,先关注,不迷路。


文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/115739621

- 点赞
- 收藏
- 关注作者
评论(0)