爬虫百战穿山甲(1)有道翻译爬虫


系列简介
将我的“爬虫百战穿山甲”团队平时做的项目放到这个专栏里吧,
仅供学习研究使用,如有侵权,私信我删除,不得转载
本系列不多废话,小白入门爬虫可以先看一下我的另一个专栏:点击进入:精写15篇,带你入门Python爬虫
里面有十一篇教程,带四个项目。
分析网页
点此蓝字打开:有道翻译
直奔主题:
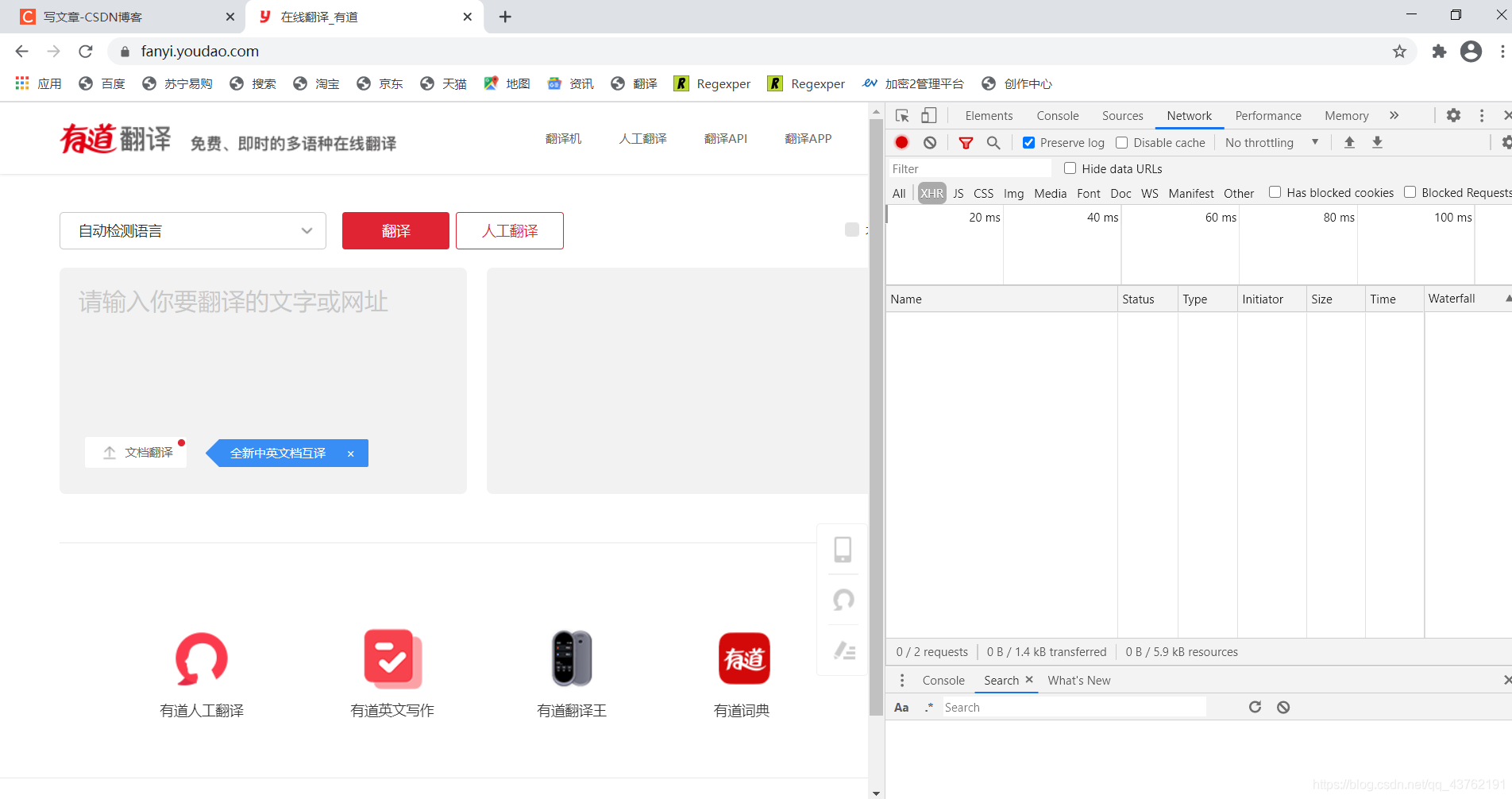
直接打开网络传输板块,选择“XHR”。
输入测试单词,比如说:hello,发现两个包,但是不知道有什么不一样的,就拿一个就好了:
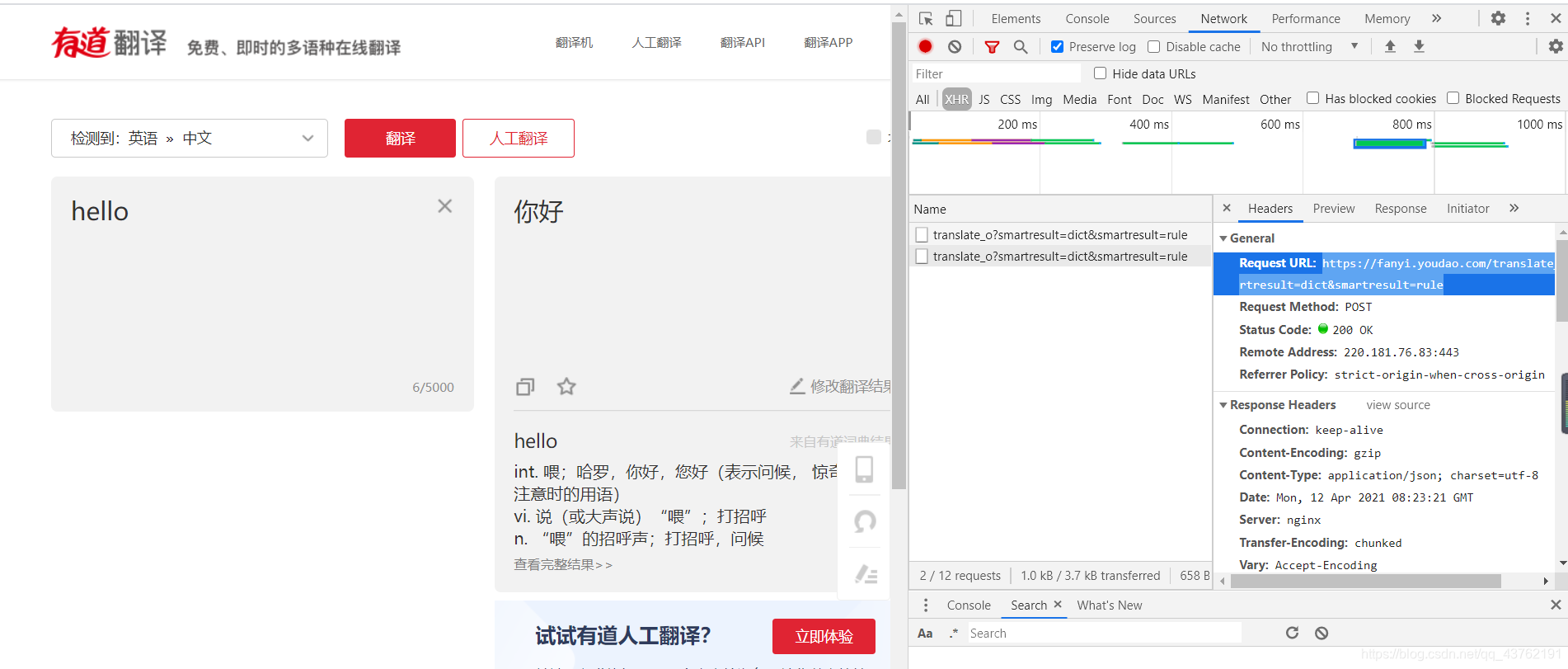
拿下那个网址:https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule,这个网页打开是被锁的。
根据前辈的经验,把translate后面的_o去掉。
去掉之后,会发现打开的页面依旧还是有道,这是什么原因呢?我们再看一下:
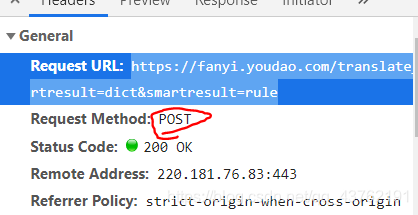
感受到了吗?这是一个post请求的包。
我们直接打开这个网址,没有进行post提交,自然是没有反应的。
既然如此,那我们就找form data吧,看看要提交什么数据上去:
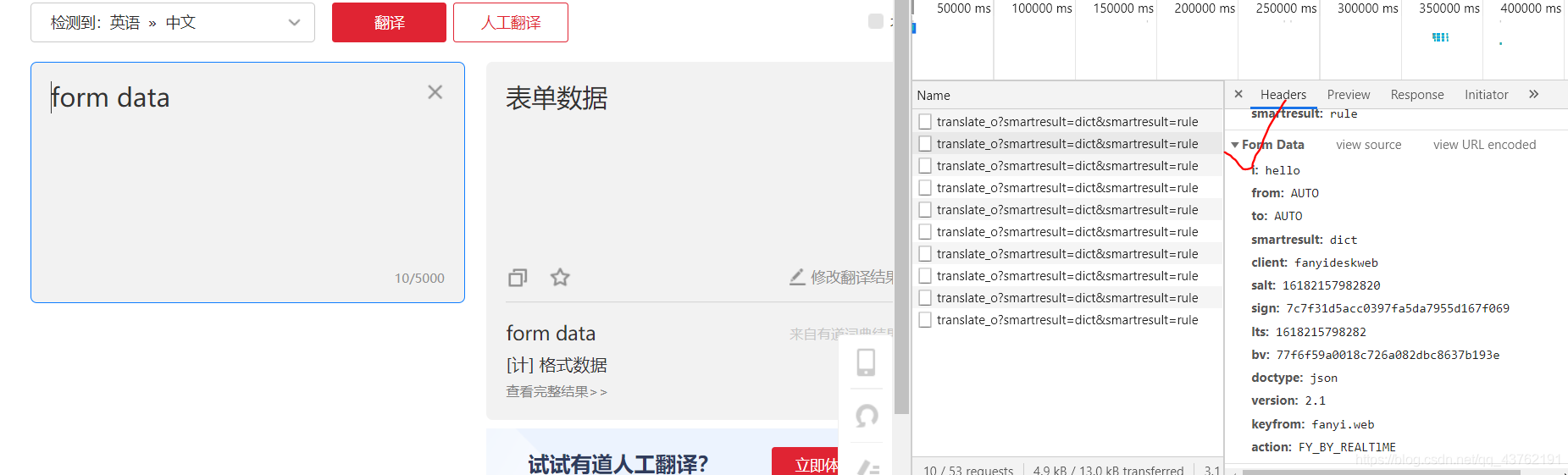
判断一下,这个 i 就是待查询的数据,from 是 i 的语言,to 是目标语言,默认是英语。至于有道上有多少中语种支持,它们的代号分别是什么,自行想办法。(不要设自动检测就行。)
剩下那些,salt时间戳,我讲过的,上面推荐的那个专栏里面也会有。
sign,md5的码,事实证明要不要自己写都行,大不了就直接去复制一个。
时间戳也是。无所谓的。
讲解到此,上代码:
代码实现
import urllib.request
import requests
import urllib.parse
import json
import time # 做时间戳的
import random # 为做时间戳提供随机值
import hashlib # md5所用
content = input('请输入需要翻译的内容:')
from_s = input("请输入待翻译的语种,中文请输入ZH,英文请输入EN:")
to_s = input("请输入目标语种,中文请输入ZH,英文请输入EN:")
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {}
u = 'fanyideskweb'
d = content
f = str(int(time.time() * 1000) + random.randint(1, 10))
c = 'rY0D^0\'nM0}g5Mm1z%1G4'
sign = hashlib.md5((u + d + f + c).encode('utf-8')).hexdigest()
data['i'] = content
data['from'] = from_s
data['to'] = to_s
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = f
data['sign'] = sign
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CL1CKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
res = requests.post(url,data=data)
request = urllib.request.Request(url=url, data=data, method='POST')
response = urllib.request.urlopen(request)
pre_js = response.read().decode('utf-8')
a = pre_js.split('[[')
b = a[1].split(']]')
c = b[0]
j = json.loads(c)
print(j['tgt'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
拓展延伸
有兴趣的小伙伴可以多开发几种其他的语种,都是支持的,就是语种代号我没去弄。
可以做成一个语种下拉框,就好。
事了拂尘去,深藏功与名。

文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/115626972

- 点赞
- 收藏
- 关注作者
评论(0)