DL之VGGNet:VGGNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略

DL之VGGNet:VGGNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
目录
1、关于imagenet-vgg-verydeep-19.mat模型简介
相关文章
DL之VGGNet:VGGNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻
DL之VGGNet:VGGNet算法的架构详解、损失函数、网络训练和测试之详细攻略
VGG系列神经网络算法简介
VGGNet 是2014 年ILSVRC竞赛分类任务的第二名(第一名是GoogLeNet)和定位任务的第一名,来自牛津大学VGG group 。
Abstract
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively.
摘要
本文研究了卷积网络深度对大规模图像识别中卷积网络精度的影响。我们的主要贡献是对深度增加的网络进行彻底评估,这表明,通过将深度推至16-19重量层,可以显著改善现有技术配置。这些发现是我们提交的ImageNet挑战赛2014的基础,我们的团队在localisation和classification tracks中分别获得第一和第二名。
Conclusion
In this work we evaluated very deep convolutional networks (up to 19 weight layers) for largescale image classification. It was demonstrated that the representation depth is beneficial for the classification accuracy, and that the state-of-the-art performance on the ImageNet challenge dataset can be achieved using a conventional ConvNet architecture [10, 11] with substantially increased depth. Namely, our object localisation system won the ILSVRC-2014 localisation challenge, while our classification system took the second place in the classification challenge. Our results yet again confirm the importance of depth in visual representations.
结论
在这项工作中,我们评估了非常深的卷积网络(高达19个权重层)的大规模图像分类。结果表明,表示深度有利于分类的准确性,并且可以使用传统的ConvNet结构[10,11]在深度上显著增加,从而在ImageNet挑战赛数据集上实现最先进的性能。也就是说,我们的目标定位系统赢得了ILSVRC-2014定位挑战,而我们的分类系统在分类挑战中排名第二。我们的结果再次证实了深度在视觉表现中的重要性。
论文:Karen Simonyan and Andrew Zisserman(2014): Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs] (September 2014).
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR, 2015.
Visual Geometry Group, Department of Engineering Science, University of Oxford
https://arxiv.org/abs/1409.1556v1
1、网络架构
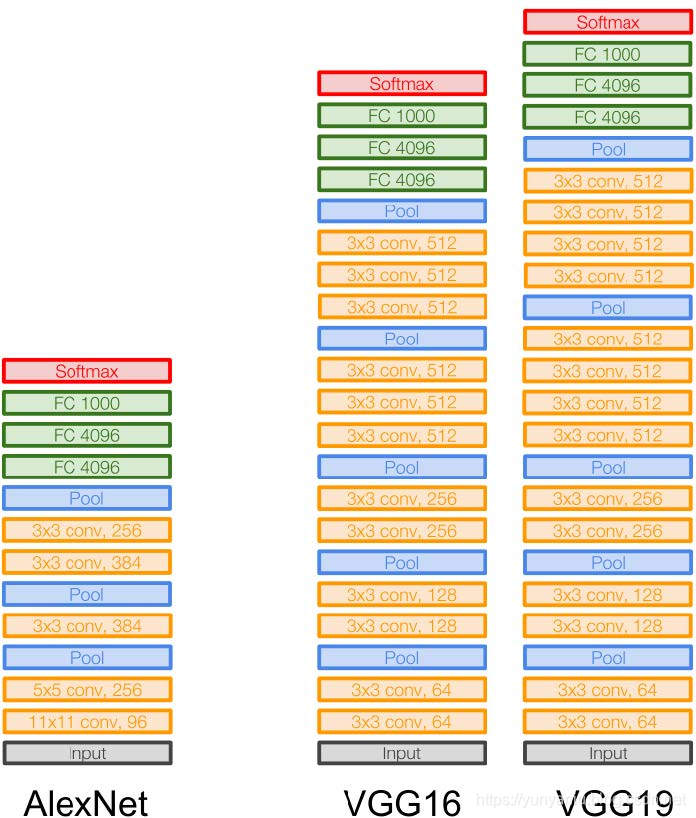
- 网络配置:VGG16是16个卷积层或全连接层,包括五组卷积层和3个全连接层。
- 网络规模 :总的参数个数138M 。
2、实验结果
- VGG16: top-1和top -5错误率分别为24.4%和7.2%
- VGG19: top-1和top-5错误率分别为24.4%和7.1%
VGG系列神经网络的架构详解
DL之VGGNet:VGGNet算法的架构详解、损失函数、网络训练和学习之详细攻略
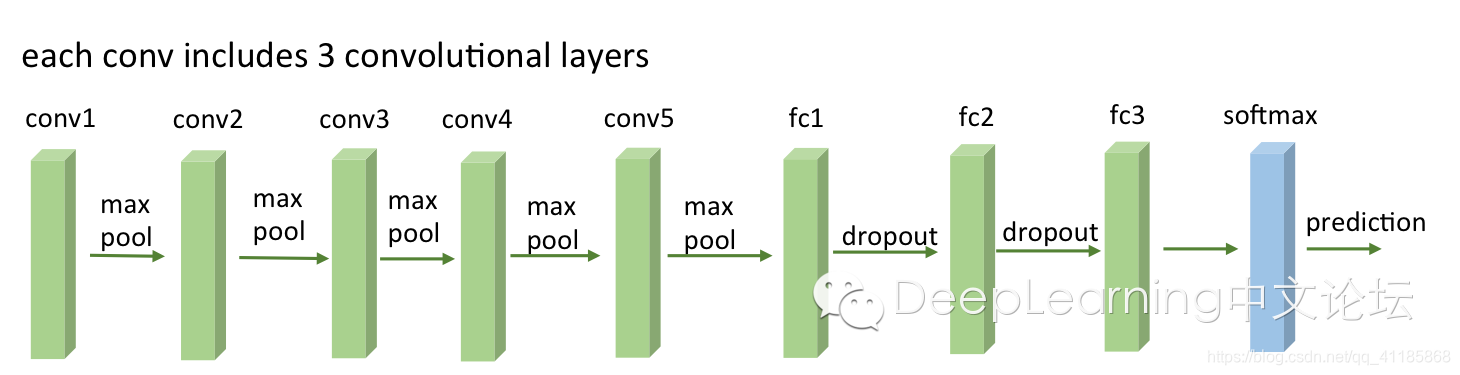
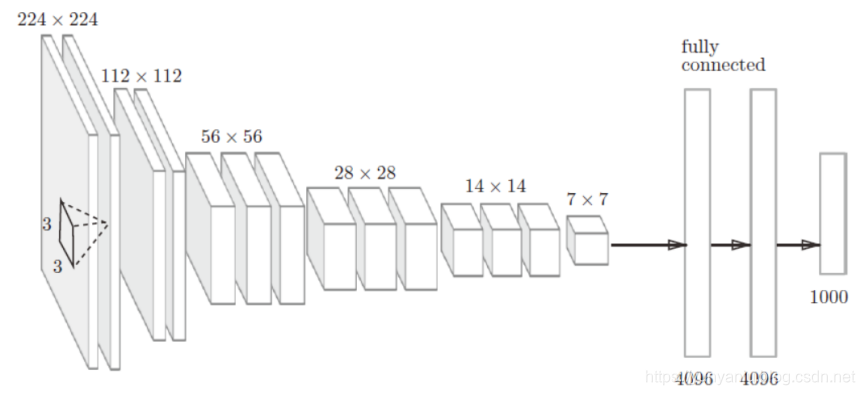

1、VGG一般的网络结构及其参数



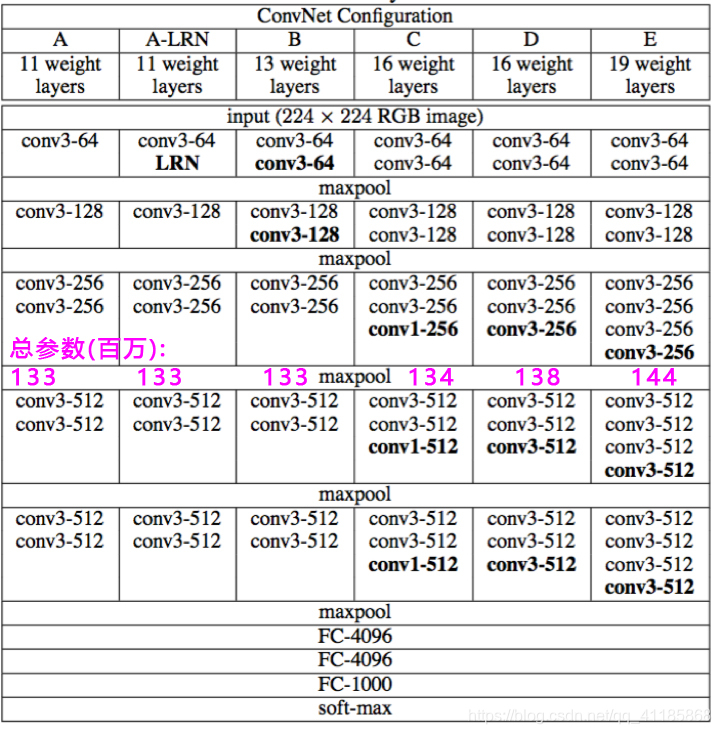
VGG系列集合以及对比
VGG11~VGG19
(1)、训练VGG系列模型所需要的显存:模型D(VGG16)性能效果最好

VGG16练习攻略二
1、VGG16实践经验
相关文章
DL之CNN优化技术:学习卷积神经网络CNN的优化、实践经验(练习调参)、从代码深刻认知CNN架构之练习技巧
- 尝试使用VGG16模型的其它层来作为传输层。它如何影响训练和分类的准确性?
- 改变我们添加的新的分类层。你能通过增加或减少全连接层的节点数量来提高分类精度吗?
- 如果你在新的分类器中移除随机失活层会发生什么?
- 改变迁移学习和微调时的学习率。
- 尝试微调整个VGG16模型。它如何影响训练和测试集的分类精度?为什么?
- 试着从一开始就进行微调,这样新的分类层就会和VGG16模型的所有卷积层一起开始训练。您可能需要降低优化器的学习速度。
- 给测试集和训练集添加一些图像。这样能使性能提升吗?
- 尝试删除一些刀和汤匙的图像,使所有类别的图像数目相等。这是否改善了混淆矩阵中的数字?
- Use another dataset.
- 使用另一个数据集。
- 使用Keras中另一个预训练模型。
- 向朋友解释程序如何工作。
VGG19
1、关于imagenet-vgg-verydeep-19.mat模型简介
Stanford CS20SI公开课里的一个神经网络style_transfer小模型的时候,用到了vgg pretrained模型,VGG-Net的结构图,来自论文《VERY DEEP CONVOLUTIONAL NETWORK SFORLARGE-SCALE IMAGE RECOGNITION》,发表于ICLR 2015上,比较起ALEXNET,VGG对图片有更精确的估值以及更省空间。包含了卷积层、池化层、全连接层、soft输出层等。更多详细内容见参考博客


模型下载imagenet-vgg-verydeep-19.mat
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/80564009

- 点赞
- 收藏
- 关注作者
评论(0)