ML之FE:数据处理—特征工程之高维组合特征的处理案例(矩阵分解)——基于LoR算法的广告点击预估问题

【摘要】 ML之FE:数据处理—特征工程之高维组合特征的处理案例(矩阵分解)——基于LoR算法的广告点击预估问题
目录
特征工程之高维组合特征的处理思路
1、原始数据:语⾔言和类型两种离散特征
2、为了提高拟合能力,语言和类型可以组成二阶特征
3、以逻辑回归算法为例例
4、所有的特征,才开始看起来没有任何问题
问题出现
问题解决
...
ML之FE:数据处理—特征工程之高维组合特征的处理案例(矩阵分解)——基于LoR算法的广告点击预估问题
目录
特征工程之高维组合特征的处理思路
1、原始数据:语⾔言和类型两种离散特征
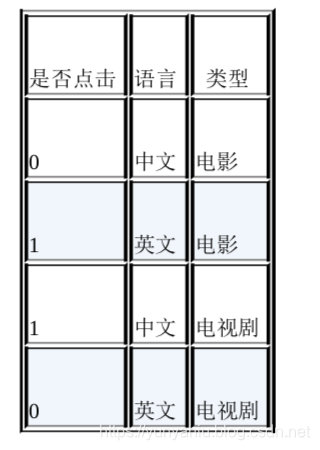
2、为了提高拟合能力,语言和类型可以组成二阶特征
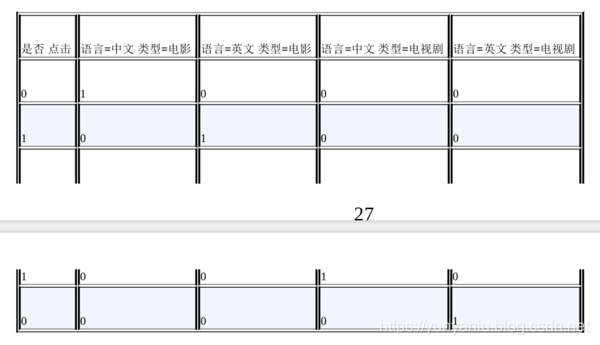
3、以逻辑回归算法为例例
<x_i,x_j>表示x_i和x_j的组合特征,w_ij的维度等于 |x_i|*|x_j| = 2*2 = 4
4、所有的特征,才开始看起来没有任何问题
但当引入ID类型的特征时,就会出现大规模数据。
(1)、⽤用户ID和物品ID对点击的影响
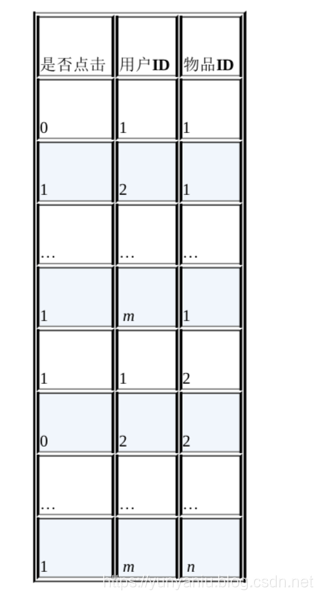
(2)、用户ID和物品ID的组合特征对点击的影响
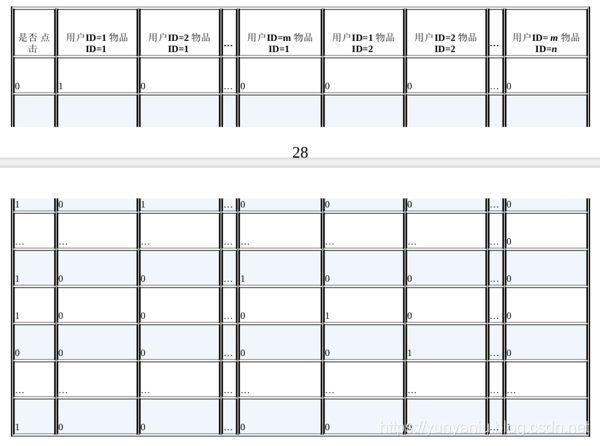
问题出现
若用户的数量=m,物品的数量为n,那么学习的参数的规模mxn。但是可是,在互联⽹网环境下,数量
都可以达到千万量级,几乎无法学习这么大规模的参数。
问题解决
有效的方法就是将用户和物品分别用k维的低维向量表示(k<<m, k<<n),其中$x_i^’$ 和 $x_j^’$分别表示
x_i和x_j对应的低维向量。
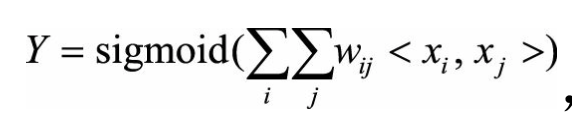
![]()
需要学习的参数的规模变成m*k+n*k (实质上就是等价于矩阵分解)。
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/92074201

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)