NLP:自然语言处理技术的简介、发展历史、案例应用之详细攻略

NLP:自然语言处理技术的简介、发展历史、案例应用之详细攻略
目录
3、2008年到2019年——深度学习的RNN、LSTM、GRU
相关文章
NLP:自然语言处理技术的简介、发展历史、案例应用之详细攻略
Paper之ACL&EMNLP:2009年~2019年ACL计算语言学协会年会&EMNLP自然语言处理的经验方法会议历年最佳论文简介及其解读
自然语言处理技术的简介
自然语言处理(Natural Language Processing,NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
1、自然语言+处理
自然语言是指汉语、英语、法语等人们日常使用的语言,是人类社会发展演变而来的语言,而不是人造的语言,它是人类学习生活的重要工具。概括说来,自然语言是指人类社会约定俗成的,区别于如程序设计的语言的人工语言。在整个人类历史上以语言文字形式记载和流传的知识占到知识总量的80%以上。就计算机应用而言,据统计,用于数学计算的仅占10%,用于过程控制的不到5%,其余85%左右都是用于语言文字的信息处理。
处理包含理解、转化、生成等过程。自然语言处理,是指用计算机对自然语言的形、音、义等信息进行处理,即对字、词、句、篇章的输入、输出、识别、分析、理解、生成等的操作和加工。实现人机间的信息交流,是人工智能、计算机科学和语言学所共同关注的重要问题。自然语言处理的具体表现形式包括机器翻译、文本摘要、文本分类、文本校对、信息抽取、语音合成、语音识别等。可以说,自然语言处理就是要计算机理解自然语言,自然语言处理机制涉及两个流程,包括自然语言理解和自然语言生成。自然语言理解是指计算机能够理解自然语言文本的意义,自然语言生成则是指能以自然语言文本来表达给定的意图。
2、NLP技术的意义
用自然语言与计算机进行通信,这是人们长期以来所追求的。因为它既有明显的实际意义,同时也有重要的理论意义:人们可以用自己最习惯的语言来使用计算机,而无需再花大量的时间和精力去学习不很自然和习惯的各种计算机语言;人们也可通过它进一步了解人类的语言能力和智能的机制。
3、NLP的两个方向——自然语言理解和自然语言生成
实现人机间自然语言通信意味着要使计算机既能理解自然语言文本的意义,也能以自然语言文本来表达给定的意图、思想等。前者称为自然语言理解,后者称为自然语言生成。因此,自然语言处理大体包括了自然语言理解和自然语言生成两个部分。历史上对自然语言理解研究得较多,而对自然语言生成研究得较少。但这种状况已有所改变。
无论实现自然语言理解,还是自然语言生成,都远不如人们原来想象的那么简单,而是十分困难的。从现有的理论和技术现状看,通用的、高质量的自然语言处理系统,仍然是较长期的努力目标,但是针对一定应用,具有相当自然语言处理能力的实用系统已经出现,有些已商品化,甚至开始产业化。典型的例子有:多语种数据库和专家系统的自然语言接口、各种机器翻译系统、全文信息检索系统、自动文摘系统等。
4、自然语言理解的五个层次

自然语言的理解和分析是一个层次化的过程,许多语言学家把这一过程分为五个层次,可以更好地体现语言本身的构成,五个层次分别是语音分析、词法分析、句法分析、语义分析和语用分析。
- 语音分析:要根据音位规则,从语音流中区分出一个个独立的音素,再根据音位形态规则找出音节及其对应的词素或词。
- 词法分析:找出词汇的各个词素,从中获得语言学的信息。
- 句法分析:对句子和短语的结构进行分析,目的是要找出词、短语等的相互关系以及各自在句中的作用。
- 语义分析:找出词义、结构意义及其结合意义,从而确定语言所表达的真正含义或概念。
- 语用分析:研究语言所存在的外界环境对语言使用者所产生的影响。
5、图灵试验判断计算机是否理解了某种自然语言
在人工智能领域或者是语音信息处理领域中,学者们普遍认为采用图灵试验可以判断计算机是否理解了某种自然语言,具体的判别标准有以下几条:
- 问答:机器人能正确回答输入文本中的有关问题;
- 文摘生成:机器有能力生成输入文本的摘要;
- 释义:机器能用不同的词语和句型来复述其输入的文本;
- 翻译:机器具有把一种语言翻译成另一种语言的能力。
自然语言处理技术的发展历史
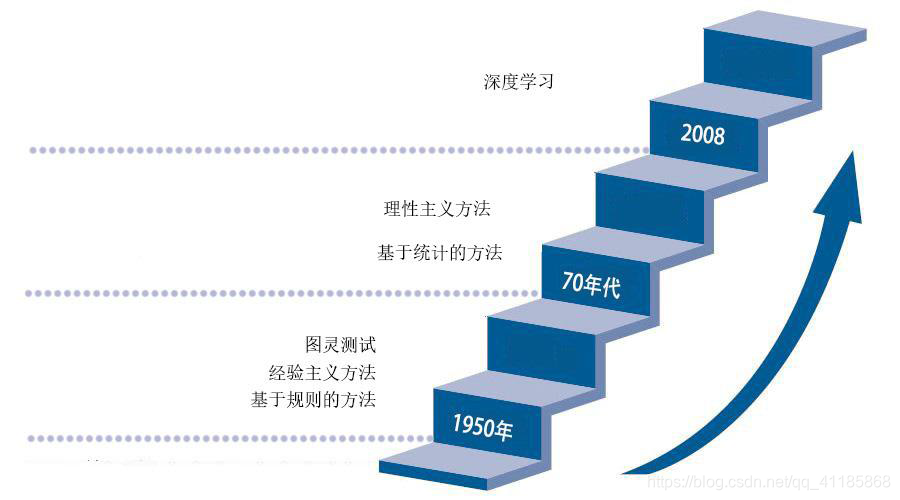
自然语言处理是包括了计算机科学、语言学心理认知学等一系列学科的一门交叉学科,这些学科性质不同但又彼此相互交叉。最早的自然语言理解方面的研究工作是机器翻译。1949年,美国人威弗首先提出了机器翻译设计方案。20世纪60年代,国外对机器翻译曾有大规模的研究工作,耗费了巨额费用,但人们当时显然是低估了自然语言的复杂性,语言处理的理论和技术均不成热,所以进展不大。
近年自然语言处理在词向量(word embedding)表示、文本的(编码)encoder和decoder(反编码)技术以及大规模预训练模型(pre-trained)上的方法极大地促进了自然语言处理的研究。
1、20世纪50年代到70年代——采用基于规则的方法
1950年图灵提出了著名的“图灵测试”,这一般被认为是自然语言处理思想的开端,20世纪50年代到70年代自然语言处理主要采用基于规则的方法,研究人员们认为自然语言处理的过程和人类学习认知一门语言的过程是类似的,所以大量的研究员基于这个观点来进行研究,这时的自然语言处理停留在理性主义思潮阶段,以基于规则的方法为代表。但是基于规则的方法具有不可避免的缺点,首先规则不可能覆盖所有语句,其次这种方法对开发者的要求极高,开发者不仅要精通计算机还要精通语言学,因此,这一阶段虽然解决了一些简单的问题,但是无法从根本上将自然语言理解实用化。
2、20世纪70年代到21世纪初——采用基于统计的方法
70年代以后随着互联网的高速发展,丰富的语料库成为现实以及硬件不断更新完善,自然语言处理思潮由经验主义向理性主义过渡,基于统计的方法逐渐代替了基于规则的方法。贾里尼克和他领导的IBM华生实验室是推动这一转变的关键,他们采用基于统计的方法,将当时的语音识别率从70%提升到90%。在这一阶段,自然语言处理基于数学模型和统计的方法取得了实质性的突破,从实验室走向实际应用。
3、2008年到2019年——深度学习的RNN、LSTM、GRU
从2008年到现在,在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深度学习来做自然语言处理研究,由最初的词向量到2013年的word2vec,将深度学习与自然语言处理的结合推向了高潮,并在机器翻译、问答系统、阅读理解等领域取得了一定成功。深度学习是一个多层的神经网络,从输入层开始经过逐层非线性的变化得到输出。从输入到输出做端到端的训练。把输入到输出对的数据准备好,设计并训练一个神经网络,即可执行预想的任务。RNN已经是自然语言处理最常用的方法之一,GRU、LSTM等模型相继引发了一轮又一轮的热潮。
4、自然语言处理最新进展
近年来,预训练语言模型在自然语言处理领域有了重要进展。预训练模型指的是首先在大规模无监督的语料上进行长时间的无监督或者是自监督的预先训练(pre-training),获得通用的语言建模和表示能力。之后在应用到实际任务上时对模型不需要做大的改动,只需要在原有语言表示模型上增加针对特定任务获得输出结果的输出层,并使用任务语料对模型进行少许训练即可,这一步骤被称作微调(fine tuning)。
自 ELMo、GPT、BERT 等一系列预训练语言表示模型(Pre-trained Language Representation Model)出现以来,预训练模型在绝大多数自然语言处理任务上都展现出了远远超过传统模型的效果,受到越来越多的关注,是 NLP 领域近年来最大的突破之一,是自然语言处理领域的最重要进展。
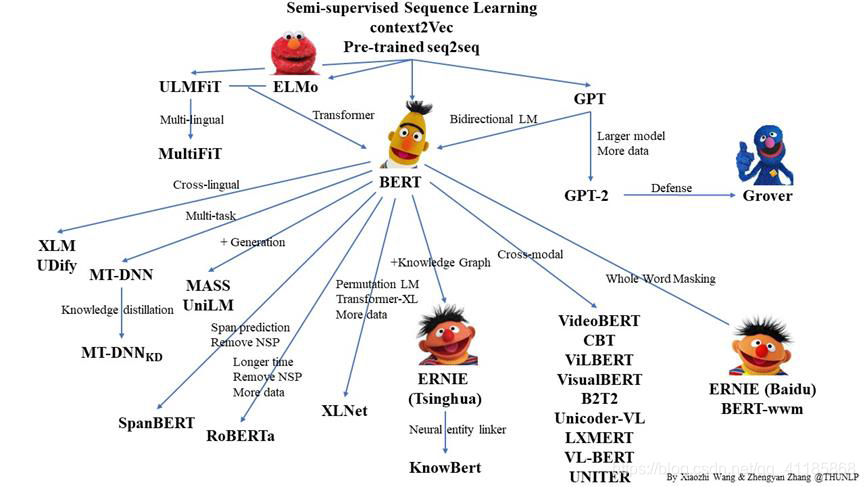
BERT(Bidirectional Encoder Representation from Transformer)是 Google AI于NAACL2019 提出的一个预训练语言模型。BERT 的创新点是提出了有效的无监督预训练任务,从而使得模型能够从无标注语料中获得通用的语言建模能力。BERT之后涌现了许多对其进行扩展的模型(如上图所示),包括:跨语言预训练的XLM和UDify,跨模态预训练的模型,融合知识图谱的ERNIE,将seq2seq等语言生成任务整合入BERT类模型的MASS, UniLM等。其中几个重要的进展包括:
- (1)XLNet使用Transformer-XL替代了Transformer作为基础模型,拥有编码超长序列的能力。XLNet提出了一个新的预训练语言任务:Permutation Language Modeling(排列语言模型),模型将句子内的词语打乱顺序,从而使得预测当前词语时可以利用双向信息。XLNet相对BERT也使用了更多的语料。
- (2)RoBERTa采用了与BERT具有相同的模型结构,同样采用了屏蔽语言模型任务进行预训练,但舍弃了 BERT中下句预测模型。此外,RoBERTa采用了更大规模的数据和更鲁棒的优化方法,从而取得了更好的表现。
- (3)ALBERT模型针对BERT参数量过大难以训练的问题做了优化,一是对词向量矩阵做分解,二是在层与层之间共享参数。此外,ALBERT将下句预测模型替换为句序预测任务,即给定一些句子预测它们的排列顺序。
自然语言处理技术的案例应用
NLP之情感分析:基于python编程(jieba库)实现中文文本情感分析(得到的是情感评分)
NLP之TEA:基于SnowNLP实现自然语言处理之对输入文本进行情感分析(分词→词性标注→拼音&简繁转换→情感分析→测试)
NLP之WordCloud:基于jieba+matplotlib库对一段文本生成词云图~~情人节最好的礼物(给你一张过去的词云图,看看那时我们的爱情)
NLP:基于textrank4zh库对文本实现提取文本关键词、文本关键短语和文本摘要
NLP:基于snownlp库对文本实现提取文本关键词和文本摘要
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/79130306

- 点赞
- 收藏
- 关注作者
评论(0)