Dataset之WebVision:WebVision数据集简介、下载、使用方法之详细攻略

【摘要】 Dataset之WebVision:WebVision数据集简介、下载、使用方法之详细攻略
目录
WebVision数据集简介
1、WebVision数据集挑战
WebVision数据集下载
WebVision数据集使用方法
WebVision数据集简介
WebVision数据集主要有Google和...
Dataset之WebVision:WebVision数据集简介、下载、使用方法之详细攻略
目录
WebVision数据集简介
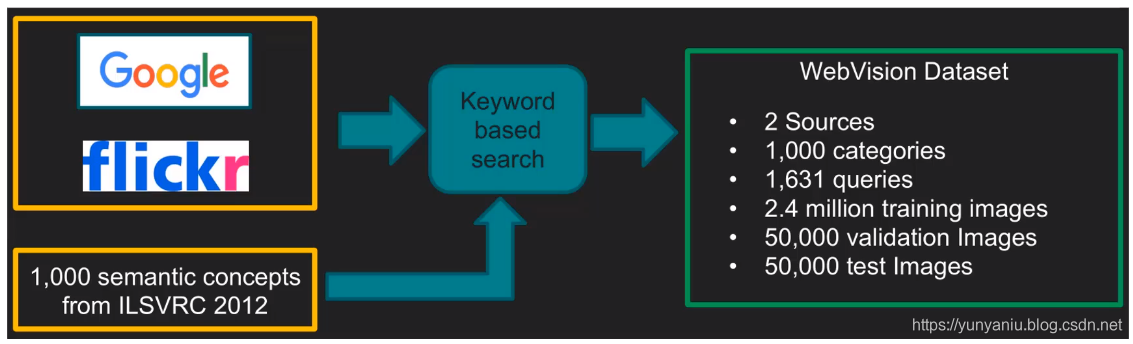
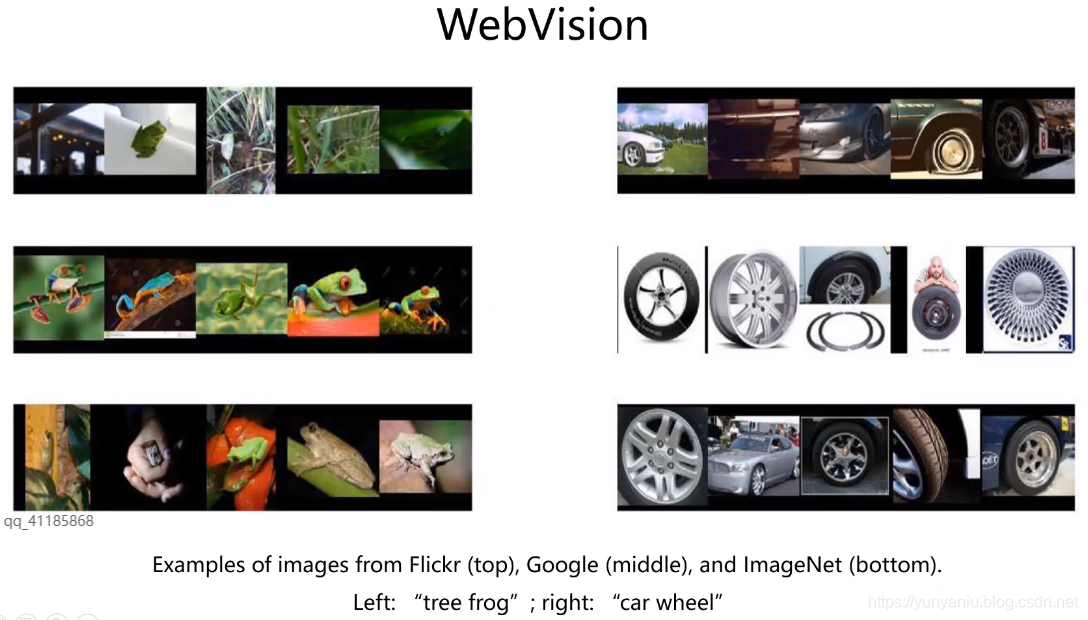
WebVision数据集主要有Google和Flickr两个数据源。主要是利用ImageNet1000个类的文本信息 从网站上爬数据,所以它的数据类别与}mageNet完全一样,为1000类别,由240万幅图片构成训练 数据。比}mageNet的两倍还多,分别由5万张图片构成验证集和测试集(均带有人工标注)。
1、WebVision数据集挑战
(1)、数据分布不平衡

WebVision数据集主要有两个挑战。 第一个挑战,数据分布非常不平衡。 如图横坐标代表1000个类别,纵坐标代表每个类别的图片数量。如图浅蓝色的平稳曲线是ImageNet的 数据分布,每一个类别大概有1200张图片。而深蓝色曲线为Web Vision数据分布,可以看出有的类别高达11000张,而最少的小于400张图片,这种极度不平衡的分布对训练模型影响非常大。
(2)、数据集含有大量错误或歧义的标签

第二个挑战,数据集含有大量错误或歧义的标签。 数据集中含有大量与类别标签不相关或歧义的图片,也就是所谓的噪声,这也是最主要的一个难点。比如Willet可以是一种鸟,但也可以是人名,也可以是建筑物的名字。
WebVision数据集下载
后期更新……
WebVision数据集使用方法
后期更新……
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/90454474

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)